Data in Motion

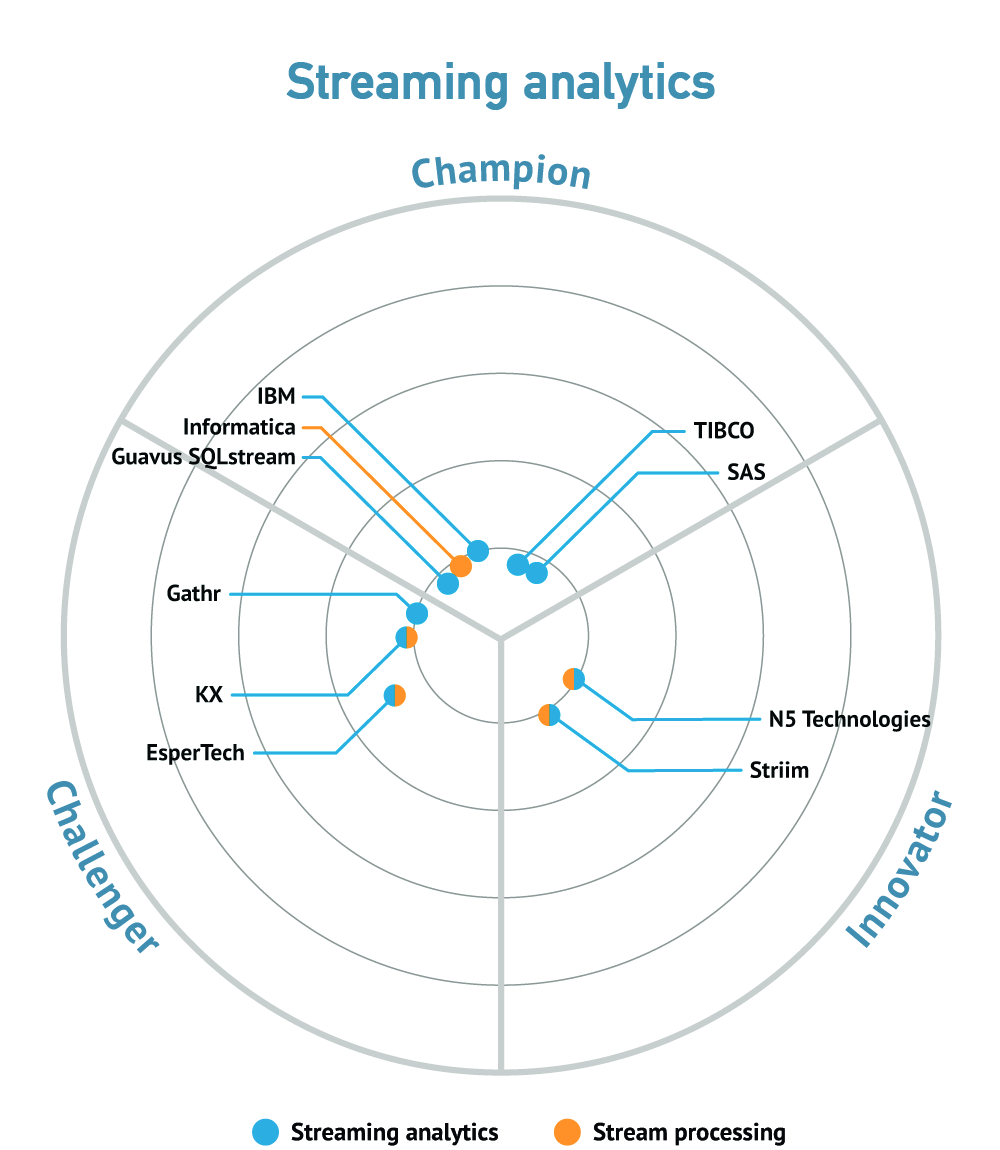
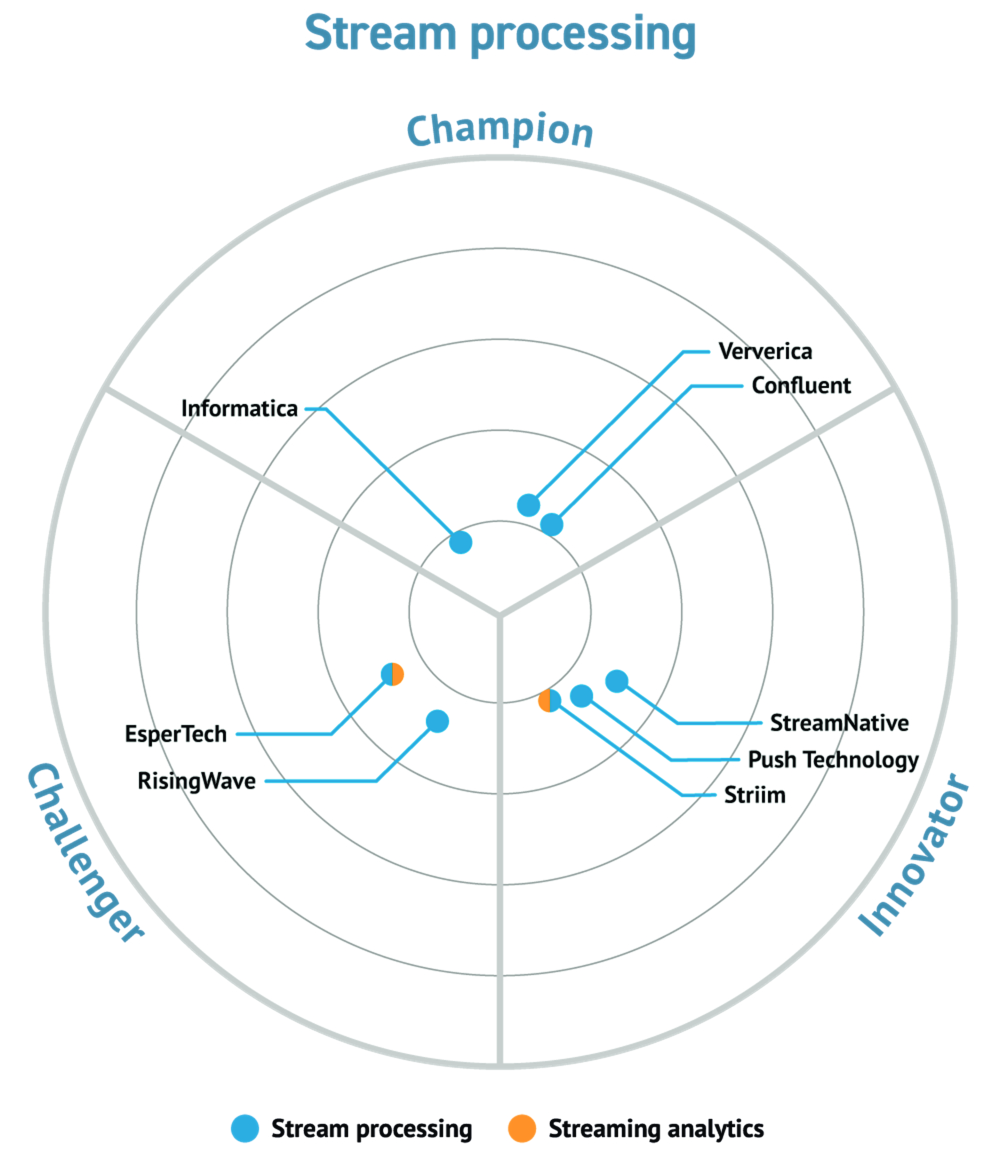
Analyst Coverage:
Lorem ipsum dolData is either in a particular place (or places) or it is being moved between places. The former is referred to as “Data at rest” and the latter as “Data in motion”. There are a variety of technologies that exist for moving data that focus on different use cases, and these are sometimes referred to under the umbrella heading of “data movement”. However, complementary technologies (for example, concerning security) usually refer to data in motion.
The most common ways of moving data are via data integration, replication, change data capture (CDC) and stream processing but we also consider data warehouse (and data lake) automation tools to be primarily concerned with data movement.
Data integration provides a set of capabilities that allow data that is in one place to be moved to another place. The technologies involved include ETL (extract, transform and load), ELT (load the data before transforming it) and variations thereof. Data replication, on the other hand, along with change data capture and associated techniques, is essentially about copying data without any need for transformation.
There are multiple use cases for data integration, but two of the most notable are to support data migration (either to another data store and/or to the cloud – see Infrastructure) and to move data from operational databases to analytic databases such as data warehouses. In the latter case, data warehouse and data lake automation tools extend this capability by understanding the relevant target schemas and helping to automate the creation of the said warehouses and lakes by generating relevant transformation and load scripts. Moreover, they typically leverage replication and/or change data capture in order to ensure that the target system is kept up to date.
Stream processing platforms, on the other hand, are typically about moving large quantities of data in real-time, often without requiring any transformation of the data (though relevant products usually have some processing capabilities). For example, for moving log data or ingesting sensor data. These platforms may also be used to support streaming analytics. Note that, unlike other relevant technologies, stream processing platforms often do not have a source data store from which they are moving data, and they are frequently used to enable edge computing (see Infrastructure).
Technologies for the avoidance of data movement include both data virtualisation and HTAP (hybrid transactional and analytic processing – see “hybrid databases”, also known by various other acronyms) environments where a single database supports both transactional processing as well as analytics. With hybrid databases, as everything is performed in one place, there is, obviously, no need for data movement.
Data virtualisation makes all data, regardless of where it is located and regardless of what format it is in, look as if it is one place and in a consistent format. Note that this is not necessarily ‘your’ data: it may also include data held by partners or data on web sites, and it may be data that is situated on-prem or it may be data in the cloud. Also bear in mind that when we say “regardless of format” we literally mean that, so you could include relational data, data in Hadoop, XML and JSON documents, flat file data, spreadsheet data and so on. Given that you have all of this data looking as if it is in a consistent format, you can then easily merge that data into applications or queries without physically moving said data. This may be important where you do not own the data or when you cannot move it for security reasons, or simply because it would be too expensive to physically move the data. Thus data virtualisation supports the concept of data federation (query across multiple heterogeneous platforms). Data fabrics are an evolution of data virtualisation (and federation) and all of these technologies follow mutable principles.
The first difference between the different types of data in motion products is with respect to transformation. Replication is a process by which data is copied, often for availability and disaster recovery purposes, without requiring any transformation. It is commonly used in distributed database environments and may be provided through either synchronous or asynchronous means. Change data capture is similar, and may be used to support replication, but is essentially about supporting real-time updates to data, where that data is stored in multiple places, and you need to propagate changes from an originating source.
Stream processing platforms typically have some processing capabilities, so it is possible to perform simple transformations using these products. However, this is not their main raison d’être, which is to allow the movement of large volumes of data – typically such things as sensor data, stock ticks, web clicks or log data – where there are low latency performance requirements. Unlike any of the other technologies discussed here they are not usually used for moving data from one database to another but, rather, from sources that are more disparate and less structured.
Finally, data integration tools, and their extension into data warehouse automation, are used when it is necessary to combine and use disparate data that is in different formats, and you need that data in a consistent format for processing purposes. The classical use case for this is in moving, and transforming, data from production systems to data warehouses. However, there are many other use cases, including B2B exchange, data migration and in support of “data preparation” tools within data lakes.
Data movement, in all of its forms, is an enabling technology rather than a solution in its own right: it is used to populate data warehouses and to exchange information with business partners and between applications, it is used to provide high availability, it may be used to support data preparation and, in the case of streaming platforms, it may be the basis for implementing machine learning and analytics in-stream, as well as to support applications – such as predictive maintenance (see Action) – within the context of the Internet of Things (IoT).In addition, these techniques may be built into other, broader tools. In particular, the data warehouse automation tools already discussed.
The emergence of streaming platforms such as Kafka and Flink has radically changed the data movement landscape over the last few years. Moreover, with the adoption of 5G we can only expect even greater adoption of these technologies. In the more traditional data integration space, the major trend is to move towards more cloud-centric provisioning rather than requiring an in-house deployment, as well as integration across hybrid cloud environments. At the same time, there is a continuing shift away from ETL towards ELT (especially where data lakes are involved), while more and more database vendors are moving into the HTAP space, thereby subverting the need for data movement. On the growth side, as graph databases become more popular there is increasing demand for tools that enable transformations from relational into graph structures.
A further major trend is towards the introduction of data fabrics. There are multiple definitions of a data fabric, but they all represent an architecture that leverages data federation and associated (data mesh) software so that all enterprise data assets, data stores and associated architectural constructs can work together. A key requirement is to minimise network traffic, and maximise performance, when querying and processing across multiple, heterogeneous data sources.
The market for data integration remains dominated by traditional vendors, though new entrants to the market, such as FiveTran and Matillion, have recently been gaining traction. Some of these are in more than one space: for example, Attunity (now part of Qlik) is a major provider of data warehouse automation as well as change data capture, while IBM, Informatica and others provide both data integration and data federation. IBM, Oracle and so forth are also in the HTAP space. In the graph space (see above) Neo4j has introduced its own ETL tool as well as integrating with Pentaho’s Data Integration product (previously known as Kettle). As far as streaming platforms are concerned, data Artisans (commercial supporter of Flink) has changed its name to Ververica and been acquired by Alibaba.
With respect to data virtualisation, there are an increasing number of database vendors – including NoSQL providers – building such capabilities into their products, typically using user defined functions alongside external table capabilities. IBM has recently introduced extended capabilities with its Queryplex product.
There are multiple open source streaming products, supported by a variety of vendors, most notably Kafka (Confluent), Flink (previously data Artisans, now Viverica) and Spark Streaming (Databricks), though this category also includes suppliers such as Lightbend, Streamsets and Streamlio. As mentioned, these will often support third-party analytics. It is also worth noting Cloudera’s support for NiFi (and MiNiFi), which are used for streaming data from edge devices within an Internet of Things context. Other notable suppliers have emerged from what used to be known as “Complex Event Processing”, such as TIBCO, Software AG (focused on the IoT space) and others.
Finally, thatDot, which provides what it refers to as a complex event stream processing, has recently released Quine, which combines graph and stream processing. Airbyte, which provides an open-source data integration platform, has launched this as a Cloud service, though only in the United States at present. Striim is also now available as a SaaS service (though more widely).
Related Blog
- InfoSec 2.0: Rethinking Data Security in 2025
- InterSystems IRIS – Letting the light in
- InterSystems IRIS: Now that is what I call a Data Management Platform
- Peer Software’s PeerGFS, maintaining choice
- Actian (re)launches data platform with integration-as-a-service
- BigPanda announces Generative AI capabilities
- RisingWave targets stream processing with SQL
- Applications in highly regulated industries
- Denodo relies on data virtualisation, but isn’t defined by it
- Free Apama Community Edition from Software AG
- “Big Data” announcements
- For everything there is a season
- Entota acquired
- Goodbye CEP, hello streaming and Cassandra
- Cisco acquires Composite: implications
Related Research
- Data management strategies for financial services
- The Rise of the Private Data Cloud
- Striim (2024)
- Matillion Data Productivity Cloud
- Fivetran (2024)
- Dataddo
- The Fabric of Teradata
- SnapLogic in the Data Fabric
- Starburst – A Data Fabric Foundation Technology
- InterSystems and the Data Fabric
- Data Fabric – A Different Approach to Data Management
- Syniti (2023)
- Fivetran (2023)
- Software AG CONNX and StreamSets Data Integration
- Top data integration qualities to watch out for in 2023
Related Companies
Connect with Us
Ready to Get Started
Learn how Bloor Research can support your organization’s journey toward a smarter, more secure future."
Connect with us Join Our Community