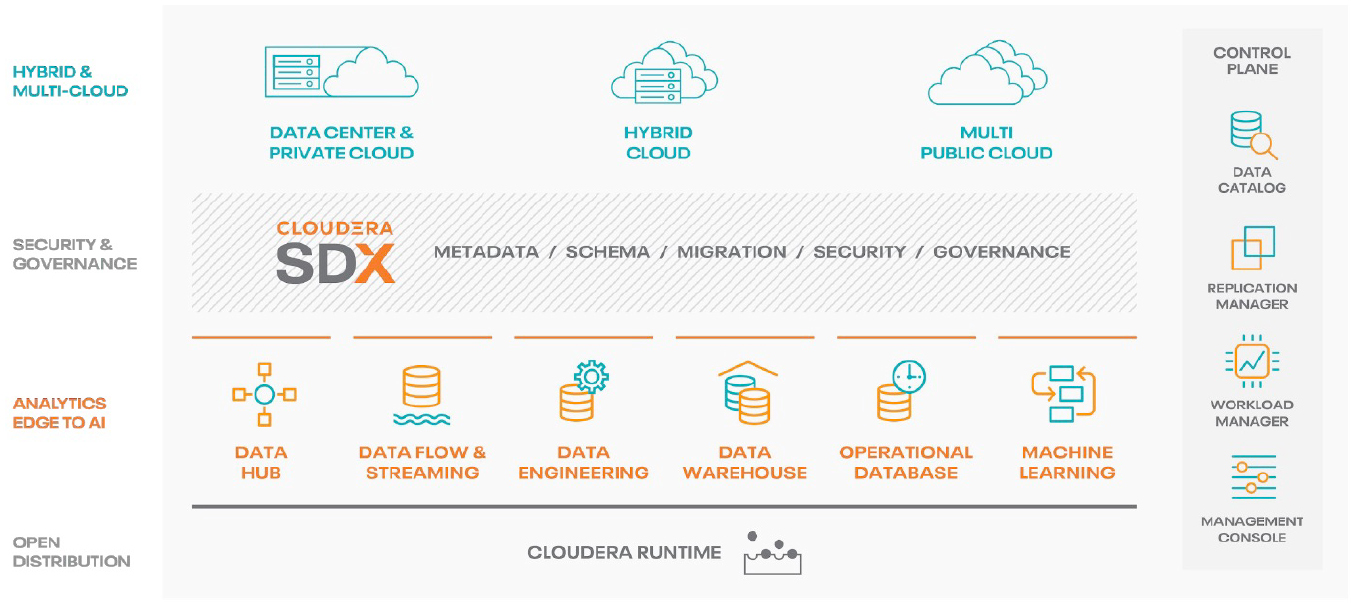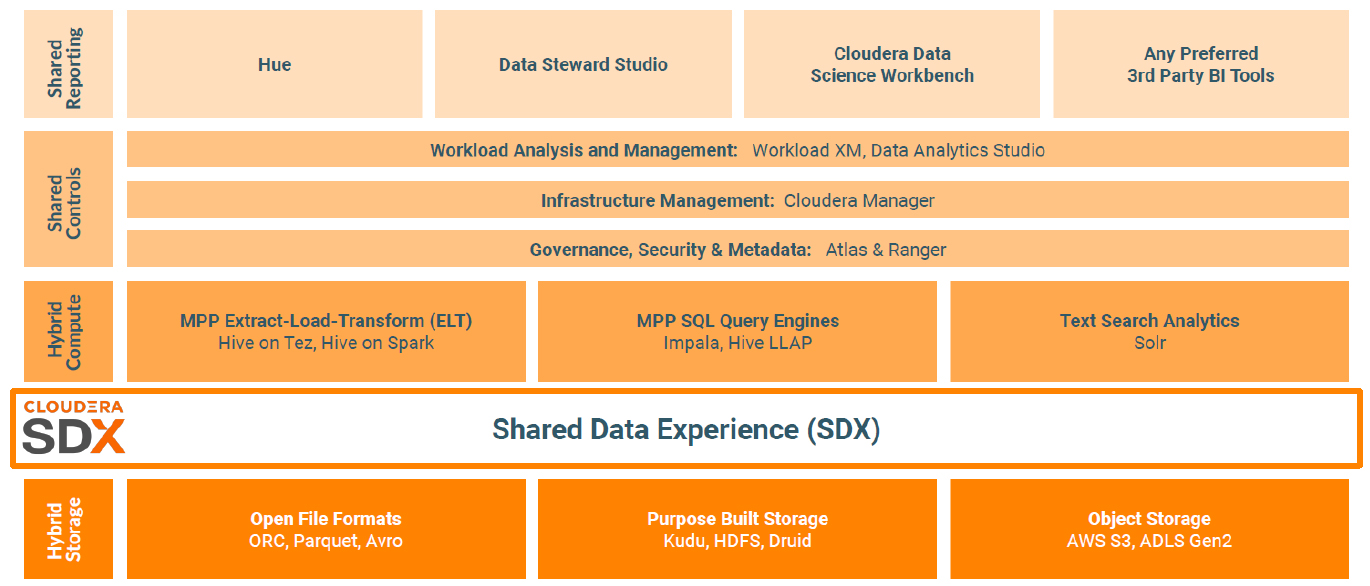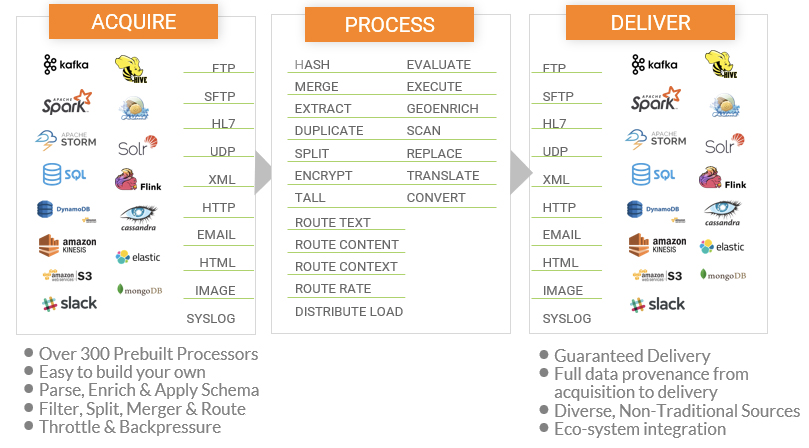
Fig 02 - The CDP integration environment and functions
For data ingestion, stream processing, real-time streaming analytics and large-scale data movement into the data lake or cloud stores, CDP’s DataFlow capabilities powered by Apache NiFi, MiNiFi, Kafka, Flink or Spark Streaming are ideal. They enable the journey of data-in-motion from the edge to the cloud or the enterprise through an integrated platform. ELT (extract, load and transform) is supported with Apache NiFi powering the extract and load parts, while Hive and Tez or Spark provide the Transform part. Traditional ETL is also possible though the majority of CDP use cases are at a much higher-scale of volume and velocity than traditional ETL. Figure 2 provides an illustration of the sorts of capabilities provided.
As far as data quality is concerned, Clouder’s approach is that you land your data in your data lake, curate it using some third party data preparation tool, and then move it into your data warehouse if appropriate. Thus, while data cleansing transformations are available there is no available data quality tool per se. On the other hand, CDP includes Cloudera SDX (shared data experience), which includes the Hive Metastore, Apache Ranger for security, Apache Atlas for governance and Apache Knox for single sign-on. Atlas is especially worth calling out because it provides a metadata repository for assets within the enterprise. That is, details about the assets derived from use of technologies such as Hive, Impala, Spark, Kafka and so on. More than 100 of these are supported out of the box and there is support to allow you to define additional asset classes. Underneath the hood a graph database is used to store asset definitions and instances, and the graph-based nature of the product allows you to explore relationships between different asset classes, and to support data lineage. It also supports the classification of assets and these can be linked to glossary terms to enable easier discovery of assets. The ability to apply policies to assets is enabled by attaching tags to columns that propagate through lineage and are then applied automatically to all derived tables. This is especially when it comes to such activities as masking sensitive data. Atlas integrates with Apache Ranger to enable classification based access control.
In addition to the metadata repository provided by Atlas, Cloudera also offers the Cloudera Data Catalog. This is intended for data stewards and end users to browse, curate and tag data. It provides a single pane of glass for data security and governance across all deployments with the notable exception (currently) that it is limited to data stored within the Cloudera environment.