Data Discovery and Catalogues

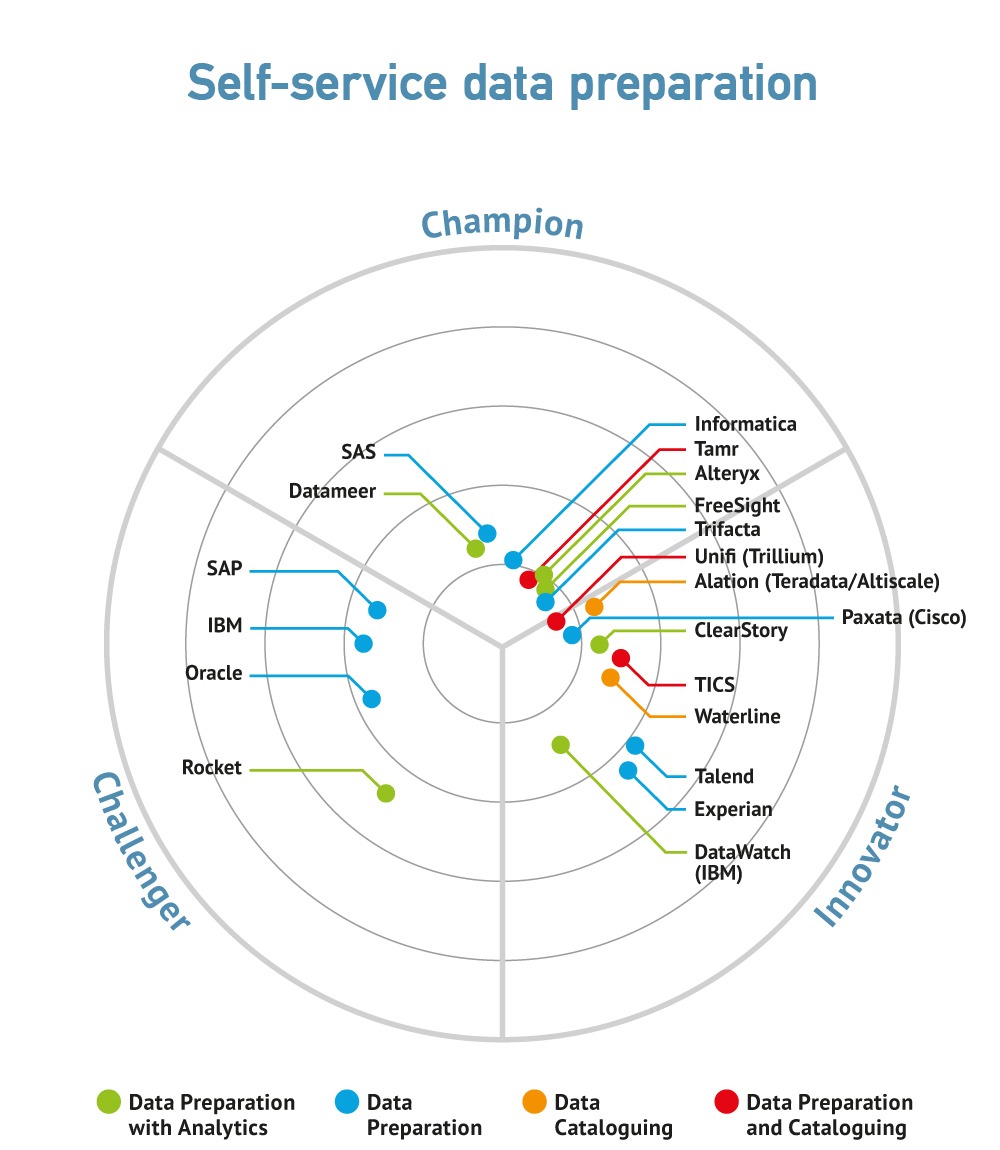
Analyst Coverage:
Both data discovery and data cataloguing are designed to allow you to know what you have and how it is related. The former, often provided as functionality with a data profiling tool, discovers the relationships that exist between different datasets within and across multiple (heterogenous) data sources. It is commonly used to support regulatory compliance (GDPR), to support test data management, and for data asset discovery. Data catalogue tools, which may make use of data discovery under the covers, provide a repository of information about a company’s data assets: what data is held, what format it is in, and within which (business) domains that data is relevant. The information should be collected automatically, and it may be classified further by geography, time, access control (who can see the data) and so on. Data Catalogues are indexed and searchable, and support self-service and collaboration. They are commonly used in conjunction with data preparation tools.
Data discovery is used with data migration, in conjunction with data archival, test data management, data masking and other technologies where it is important to understand the (referentially intact) business entities that you are managing or manipulating. This emphasis on business entities is also important in supporting collaboration between the business and IT because it is at this level that business analysts understand the data. Data discovery is also important in implementing MDM (master data management) because it enables the discovery of such things as matching keys and will provide precedence analysis. One major use case for data discovery is aimed at what might be called “understanding data landscapes”. This applies to very large enterprises that have hundreds or thousands of databases and the organisation simply wants to understand the relationships that exist across those databases.
Designed originally to work in conjunction with data lakes, today’s data catalogues can span multiple data sources (relational, NoSQL and others) and they help to eliminate silos of data. Thus, users potentially have access to all information across the organisation and are not limited by the location of any data they are interested in. Secondly, catalogues enable self-service and, thereby, productivity. They allow business users – with appropriate permissions – to search for information they are focused on, without recourse to IT. And thirdly, to find information much more quickly: not wasting inordinate amounts of time searching for data. Finally, given the deluge of data that many companies are being overwhelmed by, catalogues help to make sense of all this by providing some order and structure to the environment, so that users can see what data is relevant and what is not.

Figure 1
Figure 1 – Amount of time spent by different user groups on different data activities.
Data Catalogues can be created in a similar manner to the way that Google provides a “catalogue” of web documents by using web spiders or other technologies to create a fully searchable experience. Business specific terminology can be derived from business glossaries.
While Data Cataloguing tools can discover, for example, geographical details pertaining to a data asset, they cannot determine the relevance of that information. For that, a user will need to define the level at which geography is important: by town, state, country or region, for example. So, some manual intervention will be required. This may also be true where what you can discover about an asset is not clear-cut. In-built machine learning will be useful for classification purposes so that automated assignment of data improves over time, reducing the need for manual input.
To improve the quality of the catalogue “crowd sourcing” allows users to tag, comment upon or otherwise annotate data in the catalogue. Some products support the ability for users to add star ratings as to the usefulness of a data asset. The software will monitor who accesses what data and employs it in which reports, models or processes. If a user starts to search against the catalogue for a particular term, the software will make suggestions to the user about related data that other users have also looked at in conjunction with that term. Catalogues can also be useful in identifying redundant, out-of-date and trivial (ROTten) data that should be removed from the database.
Data discovery will be important both for CIOs that want to understand their data landscape as well as to anyone concerned with governance and compliance. Research has shown that the understanding of relationships uncovered by data discovery is fundamental to data migration.
Data cataloguing serves a dual purpose: supporting governance on the one hand and data preparation on the other, so it is relevant to both the management of data lakes (IT) and their exploitation (the business groups wanting to leverage the information in your data lake).
Although data discovery is a mature technology we have seen an upsurge of interest in it since the introduction of GDPR for finding sensitive data. In this respect there are some significant differences between products. As just one example, there are vendors that can introspect database stored procedures as a part of the discovery process, while other suppliers have no comparable capabilities. We would expect this gap to diminish over time.
As far as data catalogues are concerned, we have seen a proliferation in the number of vendors offering both data preparation and data cataloguing. While the former is not a major issue, the danger is that you can end up with multiple catalogues that do not talk to one another. Some vendors are working with Apache Atlas, which is a data governance and metadata framework for Hadoop, to resolve this issue but, in our opinion, the Odpi (part of the Linux Foundation and thus open source) Egeria project shows more promise, as a means by which metadata can be exchanged between both (existing) metadata repositories and data catalogues. Egeria is backed by IBM, SAS and ING.
Both data discovery and data cataloguing vendors come from a plethora of directions. Data quality, data movement, data masking and test data management suppliers all tend to offer data discovery, while data catalogues may be provided by data preparation and analytics vendors, while both may be provided by data governance suppliers. Many companies offer several of these product types. Data cataloguing is a relatively immature technology and the market is awash with vendors offering both data catalogues or preparation, or both. This not only includes the pure-play vendors, but also just about every business intelligence and analytics vendor. Pretty much all of the data governance vendors now offer data cataloguing. Some consolidation has started (Qlik acquired Podium Data) but more can be expected. It is difficult to see how many of the pure play suppliers can survive in the longer term, and we expect more consolidation.
Related Blog
Related Research
- Fortra DSPM (Data Security Posture Management)
- Solix Sensitive Data Discovery
- K2view Sensitive Data Discovery
- Ataccama ONE Data Discovery
- BigID Next Sensitive Data Discovery
- Aiimi Workplace AI Sensitive Data Discovery
- DataSunrise Sensitive Data Discovery (2025)
- Aim Ltd and dataBelt
- Data management strategies for financial services
- Data Fabric
- Data Fabric – A Different Approach to Data Management
- Alex Data Enterprise Platform
- Informatica Data Catalog
- PKWARE PK Protect
- Informatica Axon Data Governance (July 2020)
Related Companies
Connect with Us
Ready to Get Started
Learn how Bloor Research can support your organization’s journey toward a smarter, more secure future."
Connect with us Join Our Community