
Talend
Last Updated:
Analyst Coverage: Philip Howard and Daniel Howard
Talend first came to market in August 2005 with the beta version of Talend Open Studio, a data integration tool. This was subsequently extended with new products, so that by 2010, the company was offering a complete Data Management Platform. The company uses an open-core (Apache licenses) business model. Its products are largely home grown but it has made a number of acquisitions during its lifetime, most notably Amalto (for master data management, though this is no longer a focus for Talend), Sopera (ESB and SOA development services), Restlet (cloud-based API development and testing) and, most recently, Stitch (cloud-based, self-service data ingestion).
Initially, Talend was privately owned, based in France, and backed by venture capital but it subsequently, in 2016, floated on NASDAQ. It has nineteen offices worldwide with seven of these located in Europe, five in Australasia and the remainder in the United States. Head office is now in Redwood City. The company has more than 4,000 customers spread across all industry sectors, many of which are household names.
Company Info
Headquarters: 800 Bridge Parkway, Suite 200, Redwood City, California 94065, USATelephone: +1 (650) 539 3200
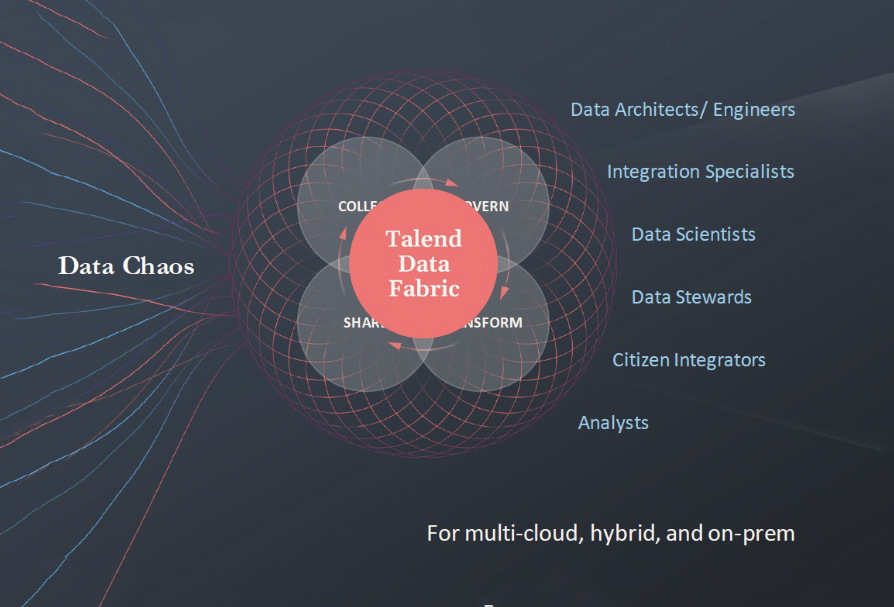
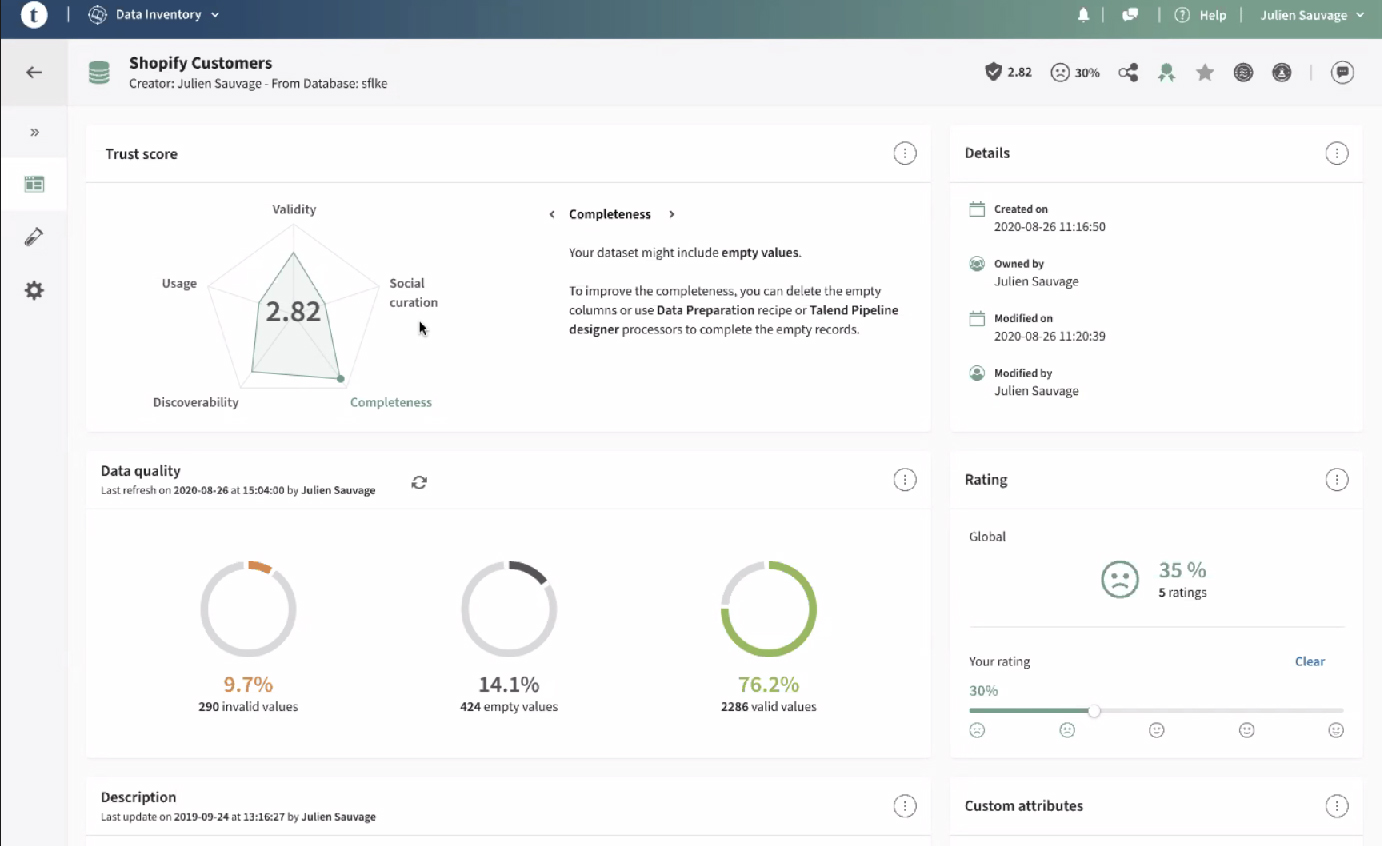


Commentary
Solutions
Research

(Cloud) Data Management Platforms

Talend Data Fabric
