
DiffusionData
Last Updated:
Analyst Coverage: Daniel Howard
DiffusionData, formerly Push Technology, was founded in 2006 and is the software vendor that produces the Diffusion Intelligent Data Platform, for which it has won multiple awards for technical innovation and excellence. The company has offices in the US Silicon Valley, UK and Ireland, with a broader presence, particularly (though hardly exclusively) in the finance, gaming, and transportation industries.
Diffusion Intelligent Data Platform
Last Updated: 5th December 2022
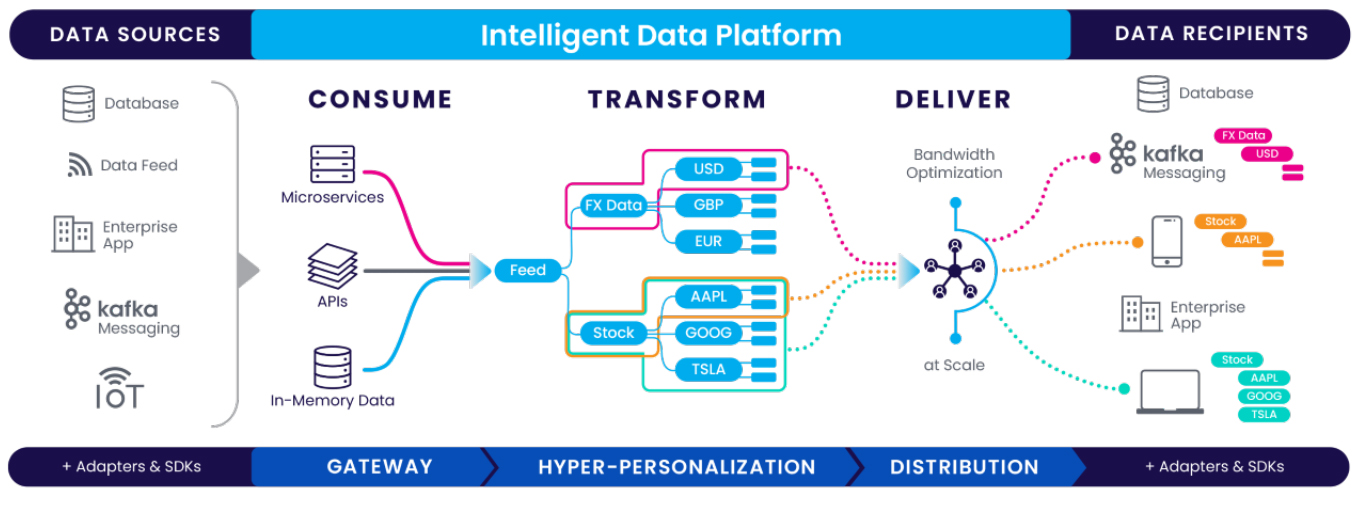
Fig 1 - Diffusion architecture
The Diffusion Intelligent Data Platform is a real-time data management platform that has been purpose-built to operate with event data. To this end, it features a subscription-based, real-time event broker with support for pub-sub, request-response, time series, and API-driven data delivery mechanisms. It also offers sophisticated, low-code stream processing capabilities, including data ingestion, enrichment, and distribution.
Its foremost (though hardly only) differentiator is its ability to allow its users to specify (which is to say, subscribe to) precisely the data they will require, and the form they will require it in, ahead of time. This enables Diffusion to provide them with exactly (and only) the data that they need. By offering this sort of fine-grained, hyper-personalised data distribution, the platform removes the need for users to prune any excess, unwanted data manually, and thus reduces processing time and costs. At the same time, only data that a user is allowed to access will be exposed to them, maintaining data privacy and security.
In addition, Diffusion boasts significant ease of use features targeted specifically at making streaming app development fast, simple, and easy. This includes a unified low-code user interface. Diffusion is available for both on-premise and public or private in-cloud deployments, including multi-cloud and hybrid environments.
Customer Quotes
“With Diffusion, we saved 4-6 months of development time, eliminated 2-3 hours of costly weekly downtime, and we experienced a 5X growth in our major client base.”
Signal Centre
“The Diffusion, Intelligent Data Platform reduces both complexity and development time. It provides a common gateway into our clients’ micro services via a single API to consume and transform event data. It also manages fan-out, scaling, and high availability of event data delivery for the large global systems we build.”
Baker Technology
The Diffusion platform is a solution in three parts: Data Gateway, for data ingestion; Data Wrangling, for enrichment, transformation, and curation; and Data Distribution, for reliable, efficient data delivery. It usually sits in your application layer, acting as a bridge between your (streaming) apps and your back-end business systems and data sources. It can also be deployed at a lower level, within the data centre, and we are told this use case is growing, but not yet typical.
The Diffusion Data Gateway includes a variety of pre-built adaptors for data ingestion and consumption. These make it simple to leverage Diffusion with data derived from MySQL, Redis, Cassandra and/or Kafka technologies. CDC (Change Data Capture) is also supported via adaptor as is REST. This makes it easy to consume raw event data from a variety of sources in any size, format or velocity. Development teams can also create their own custom Diffusion adaptors for any data sources that they happen to use. This capability significantly expands Diffusion’s flexibility and breadth.
Diffusion’s Data Wrangling allows you create hierarchical ‘topic trees’ to which your users can subscribe at any available level, and thereby choose exactly what information Diffusion will deliver to them without needing to process it themselves. Topics can be understood as a flexible identifier for your data, with typical examples including ID, name, and so on. Diffusion also provides:
- topic views (virtual topic trees) that allow you to change how your data is displayed to you without touching its back-end or altering how it’s stored
- topic inserts, which allow you to augment data from other sources
- and session topic trees, which are topic trees that are automatically specialised for a particular user session based on that session’s properties (geographic location, for example).
Topics are updated in real time using deltas (meaning only changed bytes are sent and received), allowing you to adjust or change topics quickly and easily, and various operations are available as part of the wrangling process. This includes data masking, data transformation, if-then-else conditional support, combining data sets, drilling down into and expanding data sets, and so on, in order to create a bespoke topic tree tailored for each specific user – or group of users – as desired.
Diffusion’s Data Distribution allows you to distribute your streaming data globally and in real time to millions of concurrent consumers, while reducing bandwidth consumption via proprietary delta data and compression algorithms. It also includes features such as automatic reconnect and recovery, and flow controls (such as delay and throttling) to accommodate the needs of slower data consumers and to ensure resiliency.
Finally, security is considered an integral capability for every part of the Diffusion platform. To wit, Diffusion offers fine-grained, role-based access control, with security policies applied instantaneously to all connections.
Diffusion has two features that make it particularly worth caring about. First of all, it is committed to providing a friendly, low-code user interface for building and interacting with streaming applications. This is appealing all by itself, and requires little explanation.
The second is the platform’s data wrangling capabilities: Diffusion offers impressively fine-grained access to your streaming data, meaning that consumers receive exactly and only the data needed and allowed. While filtering out unwanted data is a standard part of most data pipelines (storing excess data is both wasteful from a storage perspective and can cause compliance hiccups), Diffusion allows you to both easily automate the process and do it outside the confines of your own systems, removing any performance hit it might otherwise cause. Moreover, whereas traditional solutions had to be built (and maintained) yourself, and actioned on your system, Diffusion’s method is both built-in and actioned entirely within its platform. This has significant (positive) performance, cost, and perhaps even compliance implications.
It’s also worth noting that Diffusion plays well when deployed alongside Kafka installations. The platform’s queue-driven approach (as opposed to the message-driven approach taken by Kafka) allows optimal and efficient use and distribution of Kafka data without the added infrastructure cost which would otherwise be required.
The Bottom Line
Diffusion is one of a small number of products that have been built from the ground up to handle streaming and event data, so it should go without saying that it does its job well. Moreover, the level of control and ease of use it offers are significant differentiators. If they appeal to you, a free test drive of their cloud offering would be an excellent next step.

Commentary
Coming soon.
Solutions
Research

Diffusion Intelligent Data Platform
