
Ontotext makes life easier
Published:
Content Copyright © 2020 Bloor. All Rights Reserved.
Also posted on: Bloor blogs

Ontotext has just released version 9.4 of its GraphDB product. It contains some innovative new capabilities that I have not seen from other graph database vendors. In particular, it makes it much easier for people/tools that are not familiar with SPARQL and/or RDF both to ingest data into GraphDB to access the data within it, thereby supporting users who are not RDF experts.
The first of these features is support for SQL. Of course, there are property graph vendors that support SQL or something close to it, but this is not the case for RDF products like GraphDB. What the company has done is to enable this is to leverage the Avatica protocol and Apache Calcite. This may take some explanation. Firstly, Calcite is a generic database optimiser. Secondly, Avatica is a sub-project of Calcite that is increasingly being used as a stand-alone capability. It provides a framework for building database drivers. Taken in conjunction, and as implemented in GraphDB, this means that you can construct SQL views against SPARQL query results, as illustrated in the diagram shown. Where appropriate Calcite can push-down constructs into SPARQL queries in order to improve performance.
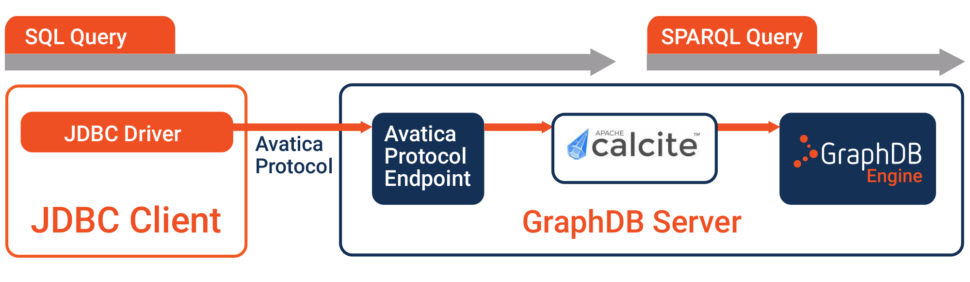
The major implications here is that it will enable you to use SQL-based tools such as Tableau, Qlik and Power BI to query (knowledge) graphs constructed using GraphDB.
That, however, is not the only innovation in this release. The company has also extended its OntoRefine product. OntoRefine is Ontotext’s extended version of OpenRefine, which is an open source project (BSD licence) that was previously known as Google Refine, and which is a data preparation/wrangling tool. What the company has done with this in this release is to introduce a visual interface that allows you to construct reusable mappings from relational (and other tabular) data sources without requiring any knowledge of SPARQL. In other words, you can transform structured data to RDF format so that these can be mapped to a locally stored schema in GraphDB.
Alongside this, the company has introduced an RDF mapping API. This allows you to automate ETL (extract, transform and load) activities to ease the process of creating or updating graphs from “data providers” such as an OntoRefine project or CSV stream.
Finally, Ontotext has announced that in its next release it will take this relational/SQL support even further. The intention is to add No-ETL integration and data virtualisation with relational-to-graph mapping (R2ML) and ontology-based data access (OBDA). This will allow users to expose Oracle, PostgreSQL, IBM Db2 and MySQL databases as virtual SPARQL endpoints. In turn, this should support the synchronisation of relational data with GraphDB as well as providing federated query capabilities across this environment.
The truth is that RDF databases have historically been perceived to be more complex than property graphs even though they have a number of advantages (not least in the way that they support knowledge graphs). Supporting SQL as a query language and making it easier to interoperate with relational databases should go a long way to overcoming such perceptions.