
Data Management – Then and Now
Published:
Content Copyright © 2022 Bloor. All Rights Reserved.
Also posted on: Bloor blogs

Data management has always been in constant flux. While individual data technologies can, occasionally, become stagnant – or even die out – the vast majority continue to grow and evolve, often in perpetuity. And data management, as something of a consolidation of many of these technologies, changes faster than most.
The purpose of this blog is to provide a whirlwind tour of some of the most recent trends in data management, and to explain what those trends mean and why they’re important.
There are four broad trends that we find to be particularly prominent and important. They are as follows:
1. The cloud
The popularity of storing and managing enterprise data on the (public) cloud is undeniable, whether through single, multi or (especially) hybrid deployments, and it’s not difficult to see why. Cloud storage is highly dynamic and scalable; it’s frequently cost-efficient (although of course this will vary from case to case, and can be impacted by egress costs); and most of all, it offloads the burden (and cost) of building and maintaining your storage solution (or a large part of it, in the hybrid case) to your cloud service provider(s).
That said, there are some challenges to the cloud, or at least, some serious questions you’ll need to ask yourself before you start to leverage it for data management. For instance, how much of your data are you going to keep in the cloud? Are you going to migrate some or all of your existing data to the cloud, and in the former case, which data? Which cloud provider (or even providers) are you going to use? How are you going to integrate your cloud data management with your on-premises data management, either during the transition from on-premises to cloud or indefinitely (in the case of hybrid environments)? What’s more, do you already have data in the cloud, perhaps because it was generated by a SaaS solution? If so, how are you going to manage that data – via the SaaS solution it came from, via your other cloud provider(s), or using another solution entirely? Finally, how are you going to ensure the privacy and security of all of your cloud data?
The last of these, in particular, has ruled out the public cloud for certain categories of data and even some industries, meaning that for this reason and others, on-premises solutions will not be entirely replaced in the foreseeable future, whether hosted in the organisation’s own data centre or in private cloud landscapes. Indeed, by our estimation hybrid data storage solutions are significantly more popular than cloud-only deployments, and we don’t have any reason to believe this will change any time soon. It’s also worth mentioning that multi-cloud deployments are quite common, and may be particularly appealing when you’re moving towards cloud adoption at scale but have some data in the cloud to begin with, perhaps due to a SaaS product you’ve invested in. In this case, multi-cloud gets you your pick of cloud providers for the majority of your data without requiring you to move your SaaS data away from where it currently sits.
Regardless, the cloud continues to surge in popularity. The vast majority of data management solutions now aim to address it in some form or another, along with providing answers to many (if not all) of the questions we’ve posed above.
2. AI and machine learning
It is increasingly in vogue for data products to include AI capabilities – and, more specifically, machine learning capabilities – wherever it could plausibly be useful. This is most obviously present in data analytics, which makes sense considering that machine learning can (somewhat simplistically) be boiled down to a very sophisticated piece of analytics technology, but it can also be felt in such things as, for example, personalised recommendations to the business user for data assets they might be interested in, actions they might want to take, or what have you, often in the context of, say, a data catalogue. And this isn’t even getting into more specialised machine learning applications, such as data classification, quality, and observability solutions, that leverage AI-driven pattern recognition.
What’s more, machine learning can be a very powerful tool. Being able to train your solution specifically in how you want to do things can generate a significant amount of additional automation, and thus efficiency and value, particularly in the more specialised use cases we’ve touched on already.
That said, there are legitimate concerns to be had about machine learning. There can even be ethical issues. For instance, you wouldn’t want to end up in the news for creating a racist model (see here) because you failed to curate your training data for bias beforehand and your algorithm picked up on that bias and ran with it. There’s also the matter of training time: while some vendors offer pre-trained machine learning models, many do not, meaning that there will be a significant lag time before the models actually know enough about your system to be particularly useful.
Basically, there are a lot of reasons you might want to leverage machine learning capabilities, as part of your data management solution or otherwise. But we caution you to tread carefully, and make sure those reasons aren’t ultimately just a matter of hype. Despite (or rather, because of) the advantages of machine learning, there is a certain amount of, for lack of a better term, bandwagoning going on with it at the moment: it has turned into one of the latest buzzwords to come out of data. At its very worst, machine learning is ineffectually thrown into products as a checkbox to put on a marketing document, rather than as a valuable capability with a defined and developed purpose, and we exhort you to make sure this is not the case (or, if it is the case, that at least you’re aware of it) when choosing a data management solution.
3. Data fabrics and data meshes
‘Data fabric’ and ‘data mesh’ have both become popular pieces of data management terminology in recent years. We lump them together here because they both refer to approaches you might take to your data management architecture, because the terms are similarly opaque, at least as far as many end users are concerned, and because they both share the goal of helping you to manage data in a heterogeneous data environment. The terms are also used somewhat nebulously by product vendors, owing to their nature as abstract architectural concepts – you can’t buy a data mesh in the same way you can buy, say, an ETL tool – so the way we use these terms may not precisely match up with the way some vendors do. Of course, this just adds to the confusion: we suggest you take careful heed of the principle of caveat emptor (which is to say, “buyer beware”) when it comes to these topics.
In a nutshell, the data fabric style of architecture is meant to create something like a connecting layer for all of your data sources, facilitating self-service, data access and data delivery across the enterprise. Essentially, a data fabric architecture is meant to abstract away the different locations in which you store your data from an end user perspective, presenting a single, unified view that can be utilised as such even when the underlying architecture is highly distributed.
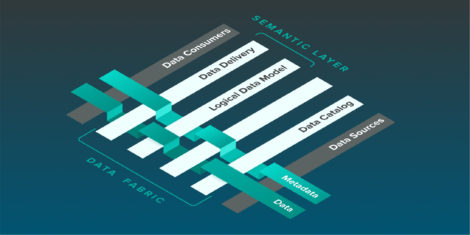
Fig 1 – Data fabric example architecture
Data mesh architectures revolve around the idea of having highly decentralised and domain-oriented data sources, originally conceived in opposition to the then-trendy idea of a single, all-encompassing data lake. Data meshes centre the idea of data-as-a-product (see the next section), and self-service and federated governance are core to this kind of architecture as a direct result of its distributed nature.
The core distinction between a data mesh and a data fabric is that while the latter seeks to create a universal connecting layer for your data sources, the former capitalises on and leverages the fact that different data domains are important to correspondingly different user groups. The logic is that each of these groups is best placed to manage the data that is most significant to them, so data meshes encourage, and enable, them to do so. There will usually include some sort of overarching governance structure out of necessity, but it’s very much deemphasised in favour of decentralised, domain-driven management.
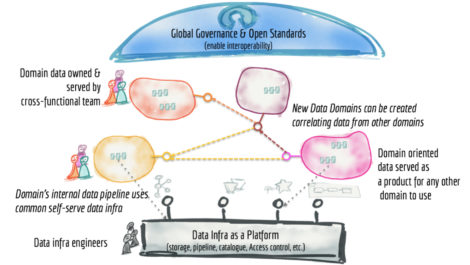
Fig 2 – Data mesh example architecture
The next question, then, is why these concepts have become so prominent. What makes them appealing? The answer is that these concepts have exploded in popularity as a response to the failure of many of the monolithic data lake implementations that were common a few years ago. There is not enough space in this blog to go fully into the history, but the short version is that many users did not see the results they were hoping for from their data lakes. Quite the opposite, in fact: the colloquial term is that they built a “data swamp”, rather than a data lake, wherein data certainly exists but is largely impossible to utilise.
In light of this, turning to a more distributed architecture (such as a data mesh) makes a lot of sense, and promises to be far easier to manage and derive value from. And once you have such a distributed architecture, the value of a data fabric follows pretty naturally. All that said, the idea of a distributed architecture has been around for quite some time, and although the specifics of data fabrics and data meshes may be new, the concepts that underpin them are decidedly less so.
4. Data-as-an-X
There are a few different ways the phrase “data-as-a…” can end, but the two we see the most often are “data-as-a-service” (which is not a particularly recent trend) and “data-as-a-product” (which is). The former, enabled by software as a service (or SaaS, which we’re sure you’ve already heard of), is basically the idea that data and data management capabilities can be delivered to your organisation by a third-party, on-demand, via the cloud. This is a well-understood concept at this point, and we would not mention it except to note that despite the similar names, it and data-as-a-product are rather different things, and in fact are barely related past the fact that they both involve data.
This is because data-as-a-product refers to the practice of treating your internal data like a first-order product, with the job of your data team(s) – and by extension, your Chief Data Officer or equivalent executive – being to provide the rest of your organisation with the right data that it needs at the right time, and at the right level of quality, thus enabling greater utilisation of your data in general (more timely and more accurate analytical insights, for instance). Technologies such as KPIs (Key Performance Indicators) are frequently employed to this end. Essentially, data is treated as a product that is curated and managed by data professionals before being handed off to data “customers” – in other words, the rest of your organisation.
The long and the short of it is that data-as-a-product essentially just means taking your internal data seriously as an asset and helping other stakeholders recognise that, rather than giving it short shrift because it isn’t seen as generating business value. The latter position has always been rather unwise, and data-as-a-product is far from the first time this has been pointed out, but if it convinces organisations to take proper care of their data, we’re all for it.