
Neo4j
Last Updated:
Analyst Coverage: Philip Howard and Daniel Howard
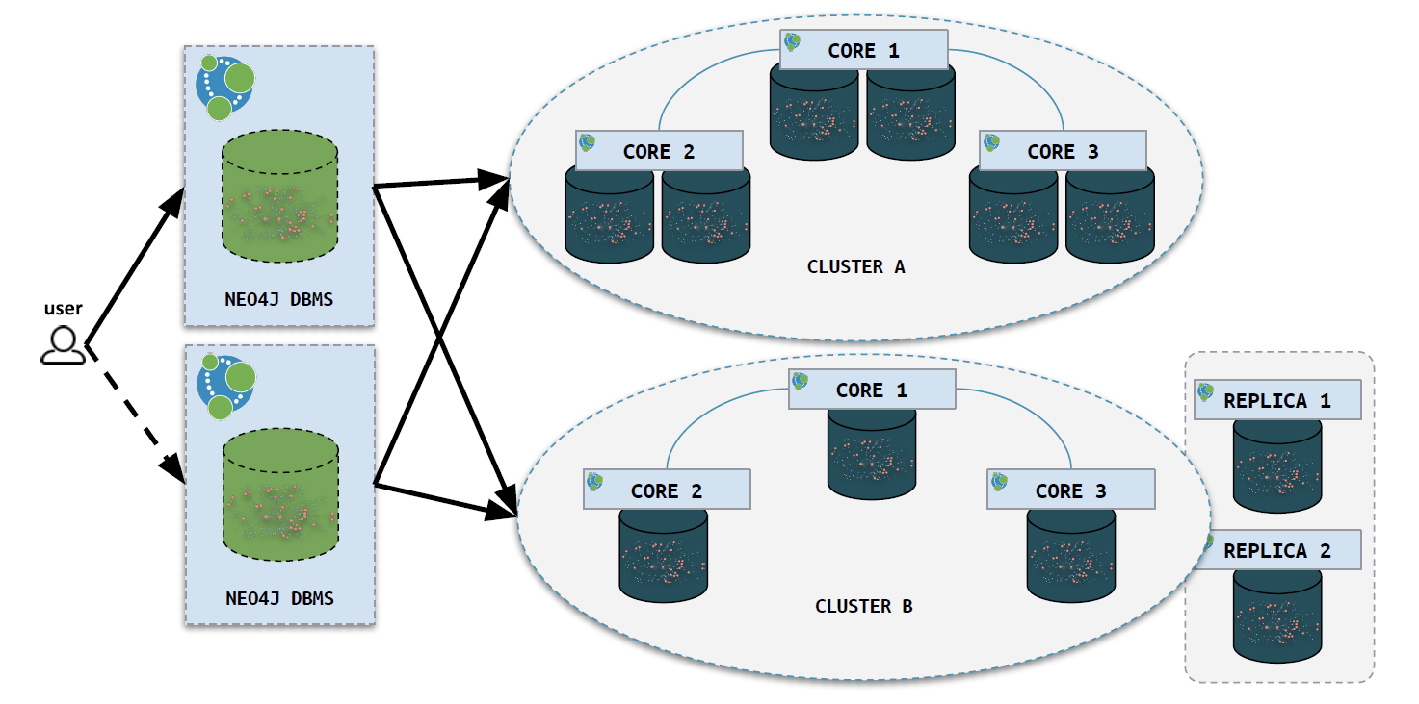
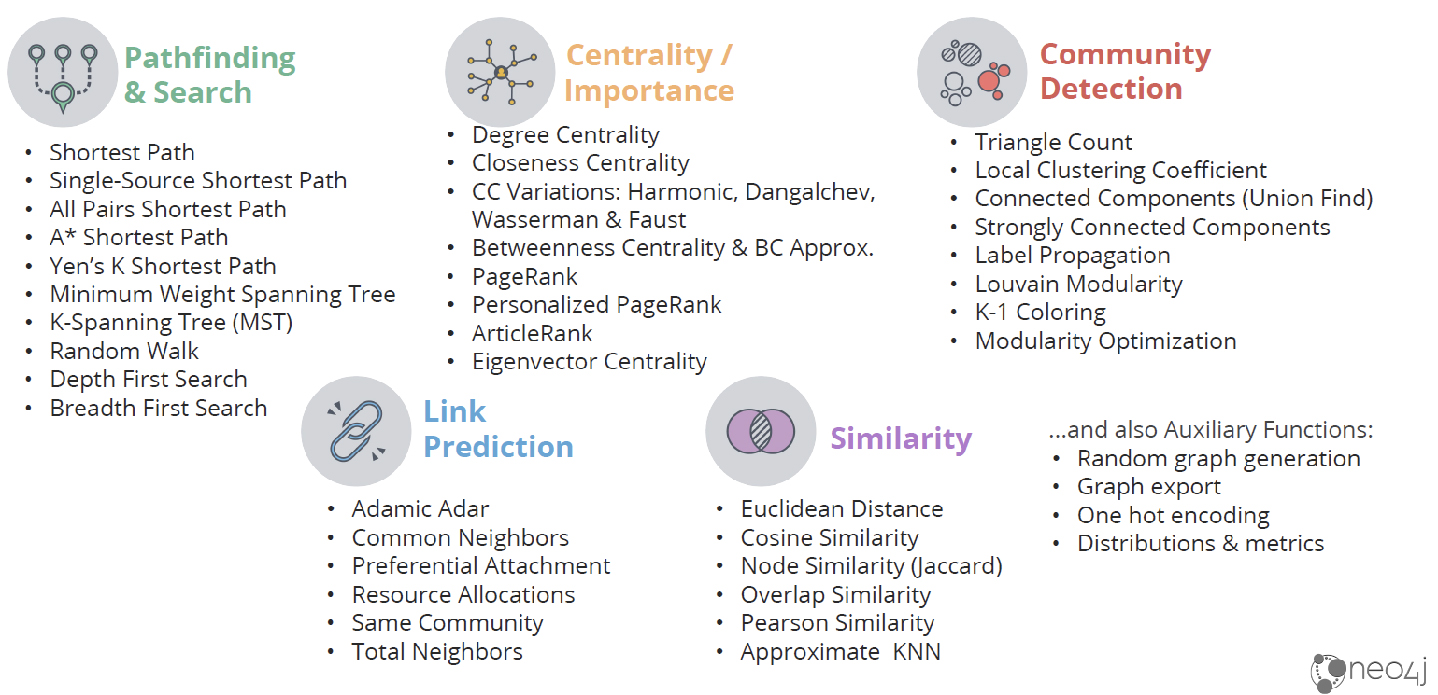
Neo4j Inc (previously Neo Technology) was first conceived in 2000 and was formally founded in 2007 in Sweden, although it is now headquartered in the United States. Outside of these two countries the company also has offices in the UK and Germany with additional sales and service personnel across the EU, Middle East and Asia Pacific regions. The company’s eponymous product is available in both Community and Enterprise Editions and is available both on-premises and via Google, Amazon and Microsoft Azure cloud platforms. Managed service options (Neo4j Aura) are also available, both in public and private clouds. The company also offers Neo4j Bloom as a visualisation engine and the Neo4j Graph Data Science Library.
The company has a significant partner base. Notable amongst these are Confluent (Kafka), Linkurious, Thales, Tom Sawyer, IBM, EY, GraphAware and NEORIS amongst many others.

Company Info
Headquarters: 111 E 5th Avenue, San Mateo, CA 94401, USATelephone: +1 855 636 4532

Solutions
Research

Graph Databases (2023)

Hybrid IT Infrastructure Management Market Vendor Landscape

Graph Database (2020)

Neo4j (2020)

Data Assurance

Hybrid real-time data processing

Neo4j (June 2019)
