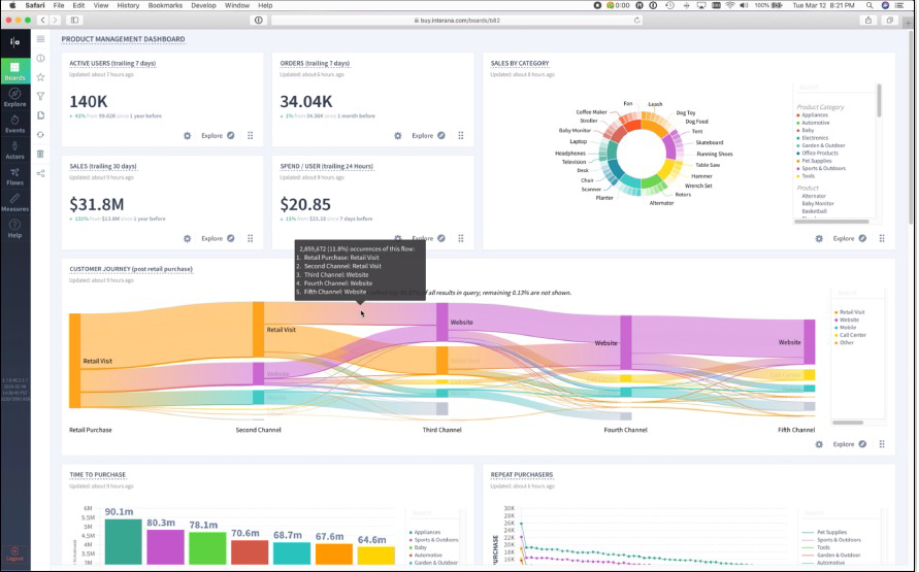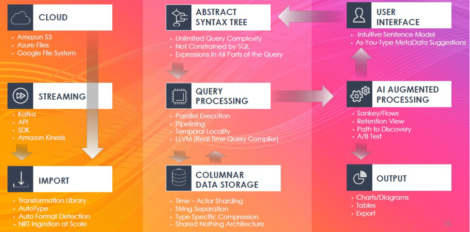
Fig 01 Interana architectural elements
Figure 1 shows a lot of the functionality of Interana, which we do not need to repeat. However, one point in particular is worth commenting upon. Firstly, note that Interana includes columnar data storage. This is sensible as time-series data is well-suited to columnar storage. However, this does make the product more than just your average analytics tool, most of which rely on third party database storage. Conversely, it means that you are less likely to use Interana with a database that has its own time-series capabilities.
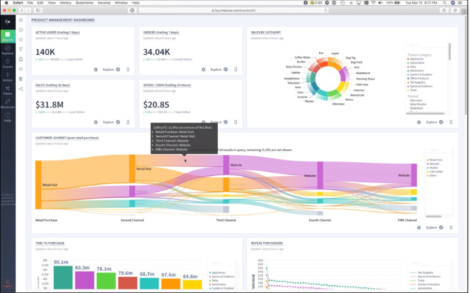
Fig 02 Query results using Interana
The major feature of Interana not illustrated in Figure 1 and introduced in the most recent release of the product, is the graphical query builder. This is shown in Figure 2. The most notable feature of this is that it does not require any knowledge of SQL or any other programming skills, with queries being compiled on the fly and under the covers, while the product will automatically discover relevant dimensions for query purposes. The resulting dashboards allow ad hoc exploration of the data – following a train of thought – as well as drill-down. Moreover, the platform has machine learning built into it (leveraging patterns of events over time) so that the software can make recommendations as to what you might do next. In other words, Interana is not just about discovery but also has prescriptive capabilities. It treats the underlying data (which may be sampled or used in toto) in terms of events, actors and flows and this allows you to customise queries so that you can, for example, query across (marketing) channels within a defined lifecycle. Users also have the ability to enrich their queries, for example, by classifying customers into relevant buckets, for instance by frequency of engagement.
Finally, we should mention performance and scalability, both of which are foci for the company and of which the company is especially proud. Several features that lend themselves to this – for example, parallelism, compression and the use of streaming data (no ETL) – are mentioned in Figure 1. The company uses SSDs rather than spinning disk for storage, for exactly the same reason. The company claims the ability to process trillions of data points per day and cites one user that had previously been running a Spark-based query that took three days to run, reduced to
25 seconds with Interana.