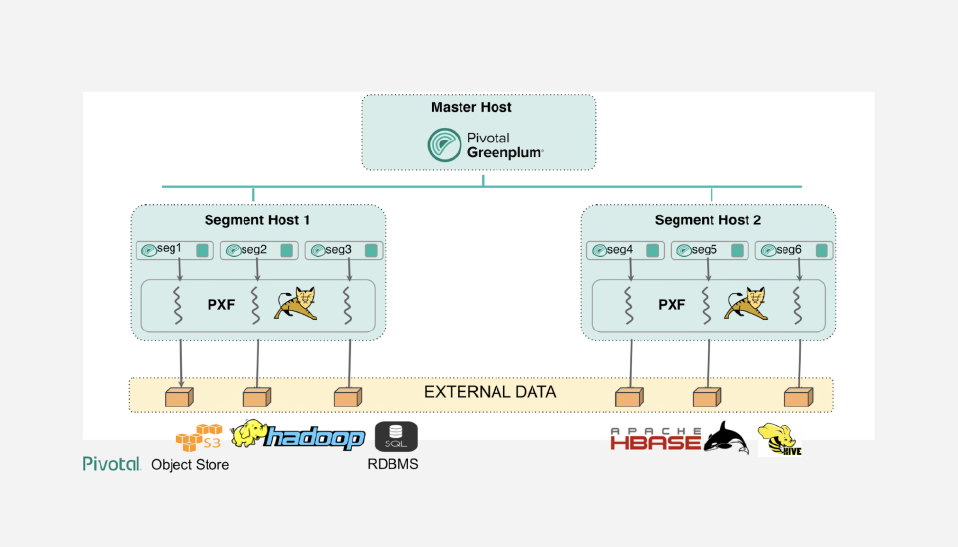
Figure 1 - Greenplum's Platform Extension Framework (PXF)
Figure 1 illustrates Greenplum’s Platform Extension Framework (PXF), the product’s architecture. The warehouse offers what the company calls “polymorphic storage” by which it means that data is stored in row and/or column format, or in external tables in HDFS or Amazon S3, depending on the queries you want to run. Row-based data is indexed for faster access, while columnar storage leverages Standard compression.
But query capability is extended beyond these confines as illustrated, so that you can federate queries across multiple data stores, with queries either running in the source system, or you can pull data into the warehouse. The company’s “next generation” cost-based database optimiser, called Orca (see Figure 2), introduced in 2017, knows about the location of relevant data and in federated environments can use both push-down filters and column projection to improve performance. The database employs the concept of slices, which are used in parallel for the execution of scans, joins, sorts, aggregations and so forth. A variety of indexes types are supported, including specialised ones for geospatial and text data.

Figure 2 - The architecture of Greenplum
Looking into the architecture shown in Figure 2, in more detail, the key to Greenplum’s performance is in the way that it distributes data, using a combination of vertical partitioning and segments, where segments also support redundancy for failover purposes. The product also features dynamic pipelining, in-memory query processing, workload management (significantly enhanced in the latest version, which is 6.0), automatic elastic query execution (where you spin up more resources, as required), and dynamic cluster expansion/shrink capabilities when the product is deployed in
the cloud.
Other noteworthy capabilities include the fact that Greenplum is ACID compliant and supports two-phase commit (with major performance improvements in the latest version of the product), connectivity with both Spark and Kafka (mapping Kafka topics to Greenplum tables on a continuous basis, with exactly once delivery), the Greenplum Command Center for database administration and management (significantly enhanced in the latest release), high availability, snapshotting to support disaster recovery, write ahead logs for improved (in version 6) stability and fault tolerance. In the latest release, the company has also made a concerted effort to reduce the need to move data. For example, it has introduced a replicated tables capability and, when querying across a third-party environment such as Amazon S3, you now only have to move required data into Greenplum rather than having to do so in bulk.