
Streamlio
Last Updated:
Analyst Coverage: Daniel Howard
Streamlio provides an intelligent platform for handling data in motion (streaming data) that truly fulfils the needs of the market as the company sees it. This means that the platform should be unified and flexible, usable at the enterprise level, highly scalable and performant, and should not place unnecessary operational burdens or complexity on its users.
The company was founded in April 2017 by architects from Twitter, Yahoo and Google. The founding team included creators and co-creators of the open source technologies – Apache Heron, Apache Pulsar, and Apache Bookkeeper – upon which the Streamlio platform is built. Note that both Heron and Pulsar are currently incubating projects.
Company Info
Headquarters: 2225 El Camino Real, Palo Alto, CA, 94306Telephone: +1 650-382-3441
Streamlio
Last Updated: 11th September 2018
Mutable Award: One to Watch 2018
The Streamlio platform is a platform for handling data in motion. It is built on top of several open source technologies, all of which were created (or co-created) by Streamlio’s founding members, and in large part continue to be maintained by the company. These technologies, which are illustrated in Figure 1, consist of Apache Heron, an extensible, fully distributed real-time stream processing engine that can be seen as the successor to Apache Storm; Apache Pulsar, a messaging and queuing system (a next generation successor to Kafka); and Apache BookKeeper, a storage solution that is used for both (stream) state storage and message persistence. All of these technologies are proven, having been deployed in production for several years by a number of large organisations, including Twitter, Yahoo and Salesforce. The Streamlio platform itself wraps these technologies into a single, architected solution and delivers it as smoothly and painlessly as possible.
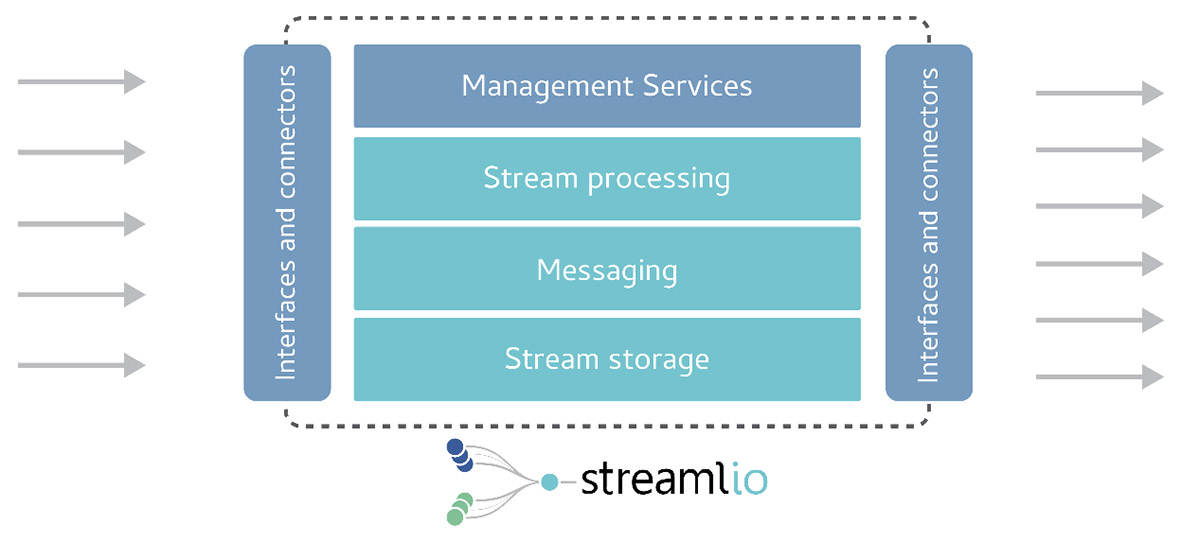
Figure 1 – Streamlio architecture
From an integration perspective Pulsar provides a Kafka-compatible API while Heron provides a Storm compatible API. Moreover, data can easily be routed to/from Kafka into Pulsar and/or Heron, and from Heron into Kafka. Streamlio can be deployed both in-cloud and on-premises. It is compatible with both Docker and Kubernetes, as well as Mesos and Nomad. It can also be deployed on the edge, in service to the Internet of Things (IoT).
Customer Quotes
“OpenMessaging benchmarks show that Pulsar has 2.5x greater throughput than Kafka, and up to 40% less latency.”
“Since adopting Apache Heron for real-time processing, Twitter has enjoyed a 3x reduction in core and memory usage, and a 90% reduction in production incidents.”
Streamlio as a whole, as well as Heron, Pulsar and BookKeeper in particular, is designed to provide high performance, at scale, while maintaining a light footprint. To this end, the entire platform uses a fully distributed micro-services architecture. In addition, the platform is designed to be multi-tenant throughout, in order to serve multiple teams, jobs and applications from a single Streamlio instance.
The stream processing itself is truly event-based (and emphatically not micro-batch). Moreover, Streamlio offers two distinct methods for processing streaming data. First of all, there are Pulsar stream-native functions. These are relatively simple, but lightweight functions that are managed by Pulsar. Secondly, there is Heron. Heron provides fully-fledged real-time processing, and although it is not as easy to set up or use as Pulsar functions, it offers much more complex processing functions, including multi-stage processing. Heron also features resource isolation, an extensible stream engine (which includes support for other technologies, such as Apache Storm, Apache Beam, and so on, via APIs), and intelligent self-regulation (that provides, for example, automatic flow control).
Streamlio’s messaging and queuing system is based on Pulsar. Its major features include the ability to handle many operational management issues during messaging (thereby removing the need for streaming applications to do the same), built-in support for geographically distributed apps via geo-replication, guaranteed, asynchronous data protection and replication, and a unified messaging model that supports both queuing and publish-and-subscribe semantics within a single model. It is compatible with Kafka, and supports Java, C++, Python and WebSocket API clients.
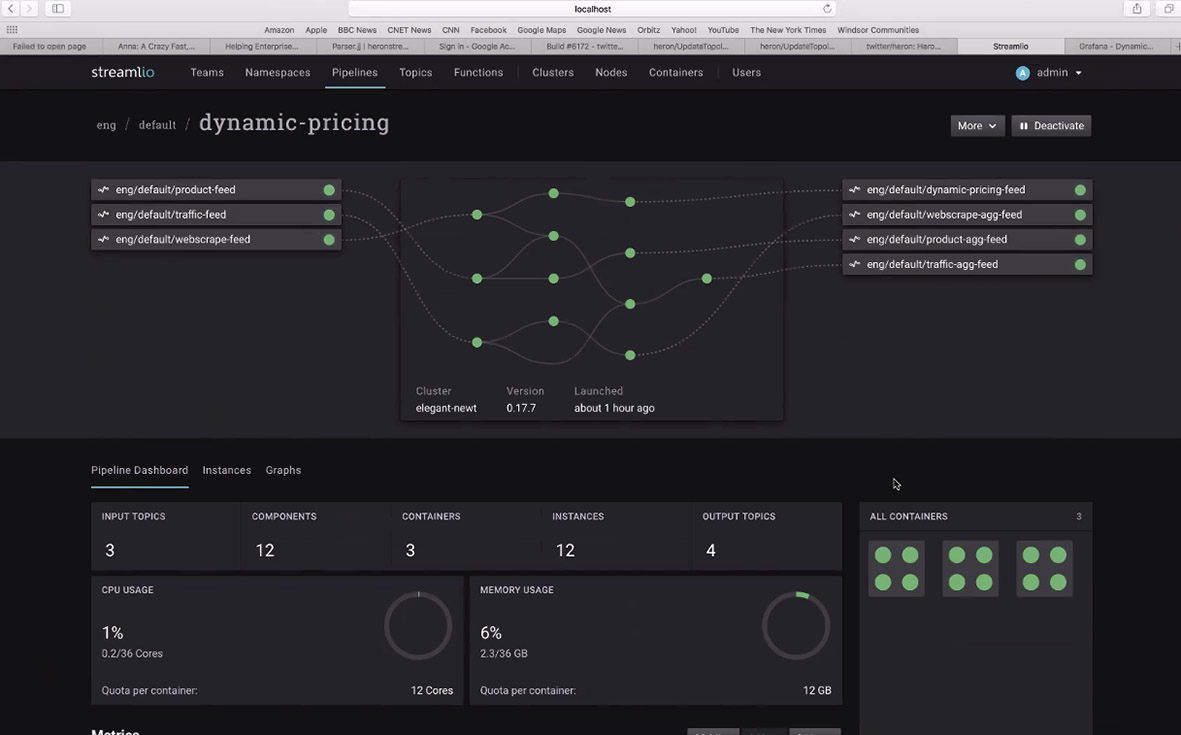
Figure 2 – Pipeline monitoring using Streamlio
Streamlio’s storage is built on BookKeeper and is used by both Pulsar (for message persistence) and Heron (for state storage). It uses an append-only approach and, importantly, it is entirely decoupled from the stream processing, via its segment-based storage architecture. This architecture allows logical partitions to be broken up and stored as (multiple) segments that can be distributed as needed among your physical systems. This stands in contrast to the traditional stream processing storage architecture, which requires copies of each partition to be stored on any given physical storage location. As a result, the Streamlio storage architecture is much more scalable and flexible than the traditional approach. The Streamlio platform also features performance isolation, realised via intelligent resource management.
Finally, the features described are made available through a web-based dashboard interface. This interface provides management and monitoring (including usage statistics) of your streaming processes, as well as data pipelines and processing flows through your system, with these capabilities being visualised and displayed in real-time. An example of pipeline monitoring is shown in Figure 2.
Historically, stream processing (analytics on real-time data) has largely been treated as distinct from batch processing (analytics on historic data). You end up with two distinct architectures. The Kappa architecture has been proposed as an alternative that does not suffer this flaw, but, in Streamlio’s opinion, it does not go far enough to remedy this issue. Streamlio offers a third option that strives to make it easy to develop a robust, extensible processing solution within a single environment. Moreover, the platform is well-suited to a variety of use cases, including just-in-time transformation, real-time analytics, monitoring and alerting, and Internet of Things applications.
The Bottom Line
Heron, Pulsar and BookKeeper offer substantial improvements over their older counterparts (particularly in the areas of scalability and performance) and are certainly worth considering when building your stream processing system. Furthermore, if you want to leverage these technologies, Streamlio is the obvious choice of product: not only is the Streamlio platform built around them (while providing a host of benefits, not the least of which is ease of use and deployment), but it’s clear that the company also possesses the lion’s share of expertise in regards to these technologies.
Mutable Award: One to Watch 2018
Commentary
Coming soon.
Solutions
Research
Coming soon.