
EXASOL
Last Updated:
Analyst Coverage: Andy Hayler and Philip Howard
Exasol was founded in 2000, entering the commercial market in 2008, coming to prominence in the same year, when it topped the TPC-H benchmarks for both performance and price/performance. It has continued to do so ever since, and it currently leads on this metric in all published results. The company is privately funded and has its headquarters in Germany. Further offices are in the UK, USA (where the company has multiple offices) and France.
The company targets three major use cases: data warehouse modernisation/replacements, for which Exasol offers pre-developed scripts; in-database data science; and BI acceleration. While the technology is applicable across all industries the company has had particular success in retail, financial, healthcare and sports analytics. It has more than 200 customers world-wide, many of which are household names.
Exasol
Last Updated: 1st July 2020
Mutable Award: Gold 2020
Exasol is a massively parallel, shared-nothing, columnar (with compression), in-memory data warehousing solution that is available on-premises, in the cloud (AWS, Azure and GCP) or in hybrid deployments. Three editions are offered: Exasol Community Edition, which is a single node, free to use solution supporting up to 200Gb of raw data (that is, before compression) with community support; Exasol One which also deploys on a single node but with up to 1Tb of data and standard support; and Exasol Enterprise Cluster, which is unlimited. There is also an ExaCloud private cloud offering.
In the early days of the company it used its own clustered operating system (based on Linux) but it now runs on standard versions of Linux and is based on the use of Docker containers. The company provides auto-indexing, auto-parallelisation of processes, automatic hot/cold memory management, a parallel loader, resource management and self-tuning. The last of these claims might be considered controversial but it is borne out by customer experience. Customer run benchmarks also bear out the TPC-H results mentioned above, with Exasol offering significantly superior performance versus Amazon Redshift, Snowflake, Oracle, Teradata and others, though it should be borne in mind that these are for specific use cases.
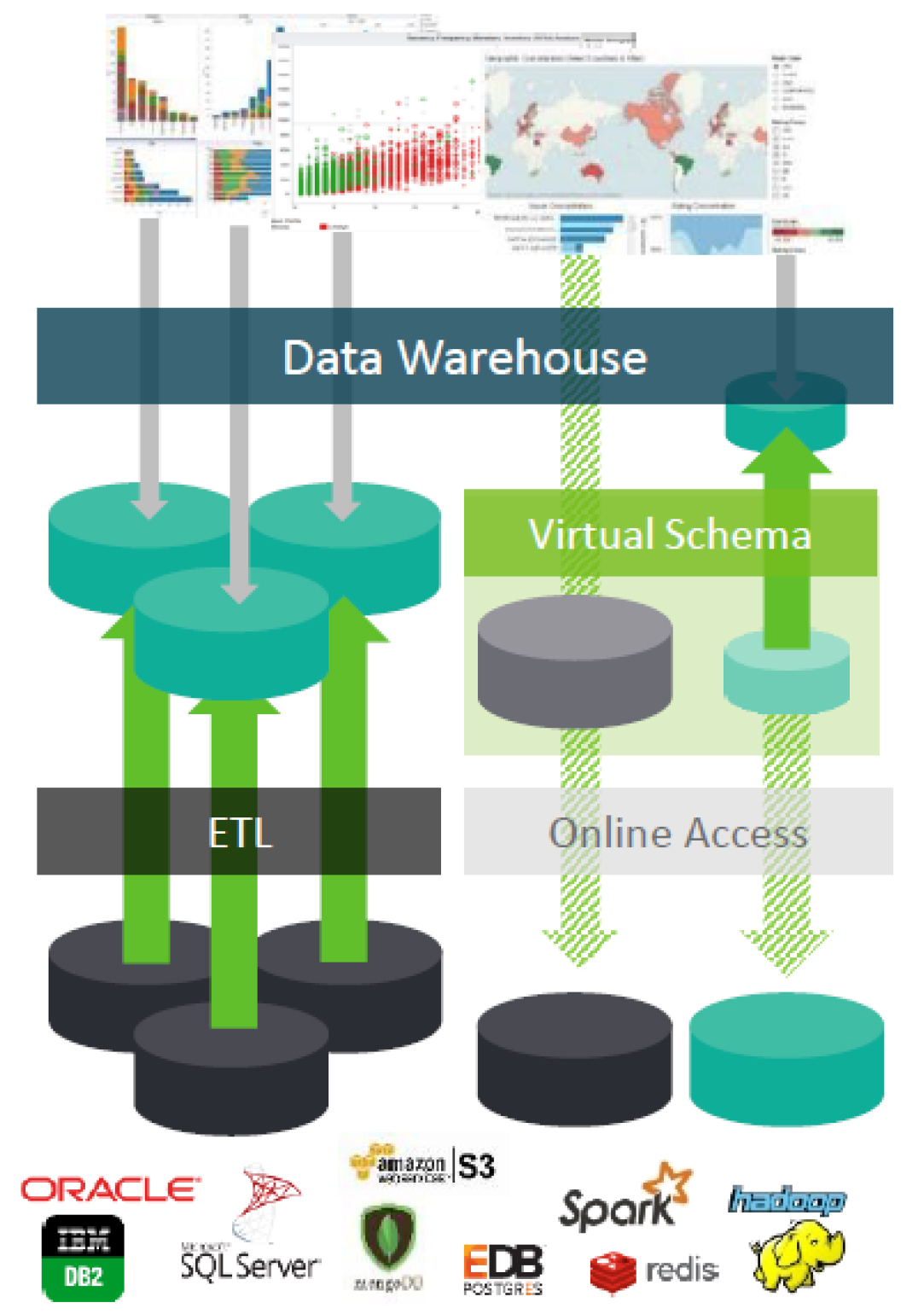
Figure 1 - Example of Exasol virtual schemas
A notable feature is the product’s use of virtual schemas, as illustrated in Figure 1, to support virtualised queries across multiple data sources. There are two things to note about this capability. Firstly, it is genuinely data virtualisation rather than data federation, in that it supports push-down query optimisation, with the database optimiser being aware of how to orchestrate the push-down. This is relatively rare: a lot of database vendors are adding query federation (without push-down) but not many support full virtualisation. Secondly, the range of third-party sources supported is more extensive than is typically offered by rivals who normally limit themselves to Amazon S3 and Hadoop and don’t support environments such as MongoDB and Redis. It is also worth remarking on the fact that there are facilities to create your own virtual schemas for other sources you may wish to support. These virtual schemas can also be used for loading data into Exasol.
Customer Quotes
“We are an extremely data-driven company and Exasol was a game changer for us. Queries that took hours now complete in seconds. People gain more trust in data when using it on a daily basis. Today, almost every department is relying on Exasol.”
Revolut
“With Exasol you can run anything. It handles MicroStrategy’s SQL with ease and its extensibility is impressive, we use it to run Python, Java and C++ right there in the database.”
Badoo
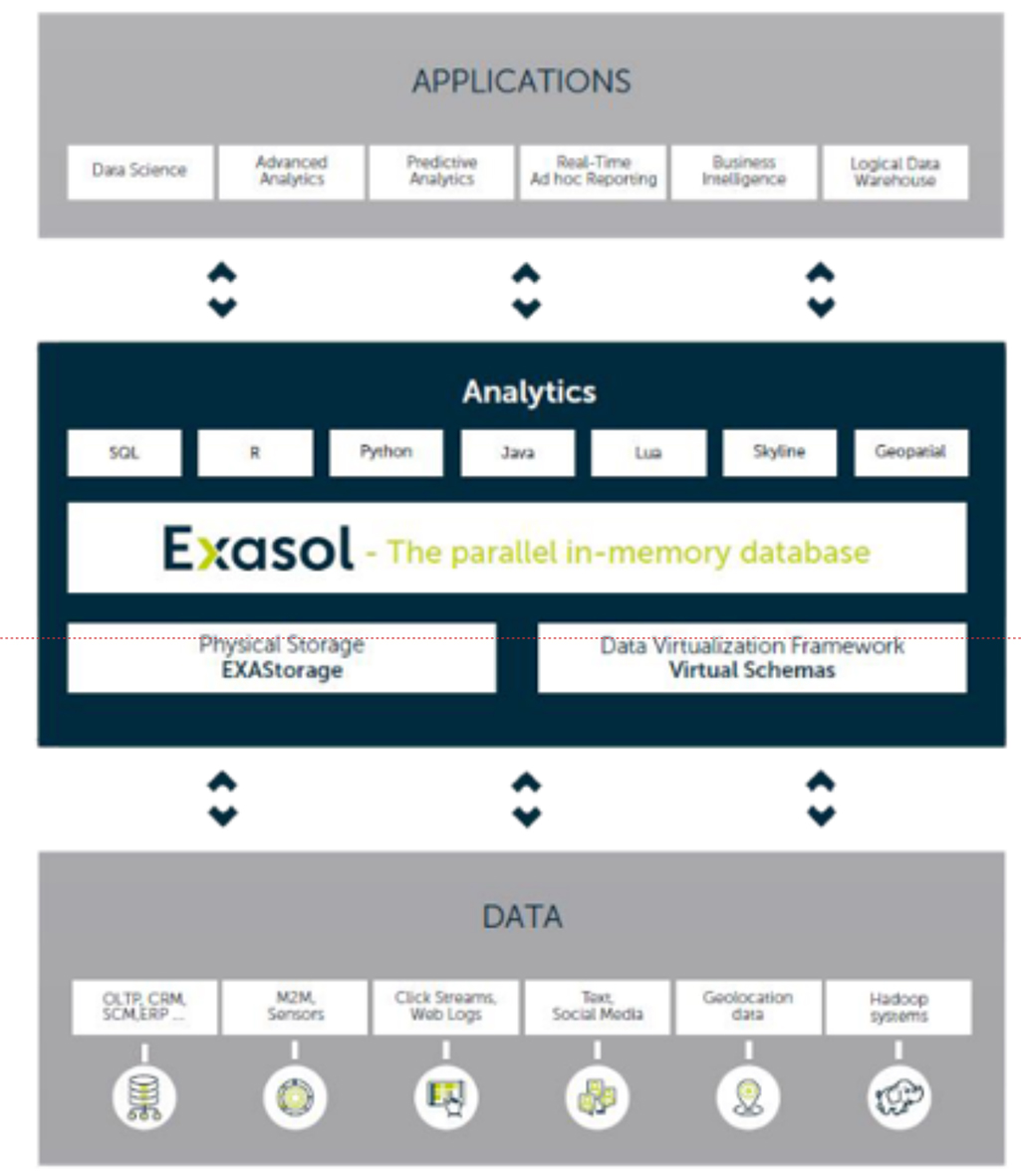
Figure 2 - The Exasol architecture
Figure 2 provides more explicit detail of the Exasol architecture. As far as data science is concerned, note the various languages shown. There is also an Apache Spark integrator and support for TensorFlow as well as open source integration for other languages such as Scala. All data science (and analytic) calculations are performed in-database.
Various Geospatial capabilities are provided, but not shown is the support for time-series, for which the company provides a number of capabilities, including generic functions for complex windowing, cumulative sums, moving averages and so forth. These capabilities will be especially important within Internet of Things environments.
Also not shown is support for streaming services such as Kafka.
From a more technical perspective, two notable features are planned for release in mid-2020. Firstly, the company will be offering compute scalability separately from storage scalability, as an option for cloud-based deployments. And secondly, it will be introducing support for graphical processing units (GPUs) to support machine learning algorithms that can benefit from this technology.
There are several reasons why you might choose Exasol. One is the product’s performance. Another is the broader sweep of capabilities when it comes to supporting third-party storage environments, which is more extensive than most other products we have reviewed. A third reflects the product’s strengths in supporting both machine learning and conventional business intelligence and analytics (all in-database), not least through its support for time-series and geospatial processing. While the latter is by no means unique, these capabilities are also lacking in a number of competitive products.
In addition to these technical benefits, Exasol also claims significant cost of ownership benefits. This is partly based on performance considerations – you need less hardware to get the performance you need – and compression; on the self-tuning nature of the database, meaning that administrative costs are reduced; and, not least, by the fact that Exasol licences its product by volume rather than by usage.
The Bottom Line
We have a lot of time for Exasol and we believe that it should be better known than is actually the case. It is difficult to imagine a use case for which you should not be at least considering Exasol.
Mutable Award: Gold 2020

EXASolution
Last Updated: 7th March 2013
EXASolution is flexible enough to be suited to a number of user environments that vary from departmental installations up to corporate-level implementations, and ranging from conventional business intelligence environments to real-time analytics. However, EXASOL is currently focusing on environments where there is a need is to run complex, analytic queries in a timely manner. In these sorts of environments EXASolution has a number of potential advantages over its rivals, which range from ease of implementation to performance and from low cost of ownership to rapid time to value.
EXASOL is fairly agnostic with respect to industry verticals although it has enjoyed success in the online gaming and new media sector, manufacturing, telecommunications, market research, financial services and retail sectors.
The most notable of its publicly named customers are Xing, Adidas, Groupon, Olympus, The Co-op, Webtrekk and Sony Music.
EXASolution from EXASOL is a massively parallel database management system especially developed for data warehousing applications, which is available as a hosted service (EXACloud), as a software only solution or as a pre-configured appliance running on commodity Intel-based hardware. EXASolution runs on its own operating system, EXACluster OS, to underpin EXASolution, with a single install for the entire environment. EXACluster OS is an application layer that sits on top of a standard Linux distribution and offers a number of advantages when compared to conventional approaches to clustering (on which EXASolution is based) particularly with respect to cluster management and installation.
As of the time of writing, EXASolution 4.0, running on Dell hardware, holds the performance records for the TPC-H benchmark at every level up to 10Tb as well as having the best price/performance records at each of these levels. This doesn't mean that EXASolution isn't capable of supporting more (much more) disk than this but that TPC-H benchmarking is only competitive up to this level (there is only one published figure that is larger than this and that was published in 2007). The one caveat we would make to this otherwise impressive set of results is that benchmarks do not necessarily equate to the workload of any particular company. Nevertheless, EXASolution can provide answers to queries (particularly complex queries) much faster than by means of conventional data warehousing. There are a number of technical reasons for this, including the use of column-based storage, in-memory processing and automated index creation.
In practice, the scalability of EXASolution is dependent on memory rather than disk capacity because the product makes extensive use of in-memory processing. The company has successfully tested warehouses with up to 5Tb of memory, which would equate to anything between 50 and 200Tb of raw data, depending on usage. The other important aspect of scalability is the number of users that can be supported and the number of concurrent queries. Existing EXASOL customers have as many as 3,000 of the former running up to 150 concurrent queries at peak periods. Another important aspect of the product is its self-tuning concept. Customers don't need to bother with schema design constraints, indices or other optimising processes. The Engine takes care of all these tasks automatically.
An additional product, EXAPowerlytics, is available and offers customers the ability to implement their own parallel algorithms within the EXASolution cluster, natively integrated into normal SQL processing. This framework also includes "R" as a programming language, Map/Reduce capabilities and the processing of unstructured data which can be dynamically loaded from external sources like through the Facebook API or Hadoop clusters. We understand that further integration with Hadoop will be a major feature of the next product release.
EXASOL provides the sort of services one would expect: consultancy, support, training and so forth. Service partners such as SSH Viveon, Logica and The Intelligent Edge Group provide additional support.
Yotilla
Last Updated: 31st January 2024
83%* of companies are dissatisfied with their data warehouses. To a large part this is due to the data warehouses failing to keep up with the rapid pace of business change. Reorganizations, mergers and acquisitions all cause conventional data warehouses to need changes, as well as breaking the data load routines, transformations, data marts and links to analytic tools. All these structural changes need weeks or months to fix. Frequent changes means that data warehouse is rarely fully up to date, eroding customers trust in it, and reducing its business value.
You cannot stop business changing, but you can speed up the processes that need to be done when a data warehouse has to be amended. Ideally you would operate from a high-level model, making changes to that model to reflect new business hierarchies or data sources. Wouldn’t it be great if a software tool could translate these model changes into new logical and physical database design, as well as regenerating the necessary load routines, transformations etc that flow from these changes? What if these various changes could be automatically generated and applied, with no need for manual code amendments to load routines, transformation scripts or database schemas? In this way even quite significant data warehouse changes could be implemented quickly.
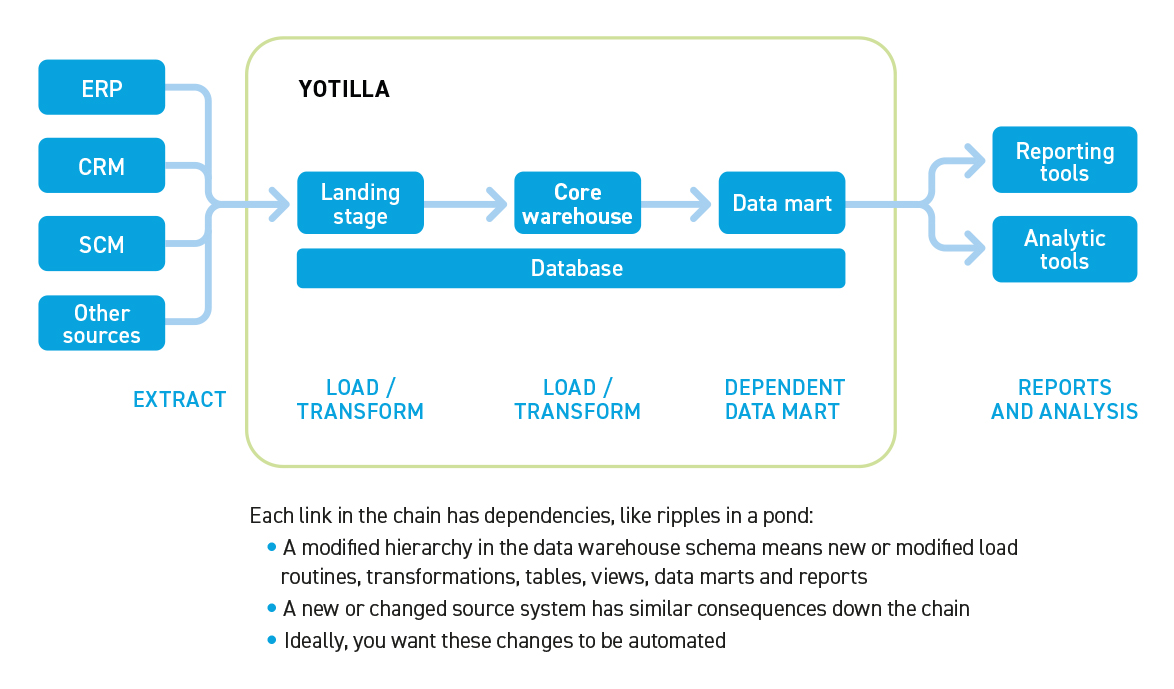
Fig 1 - Automated Architecture
Yotilla is a data warehouse automation product that allows you to design a data warehouse in the form of a high level conceptual visual model that business users can understand. Yotilla generates and manages all layers of the data warehouse, including a data mart that can be directly used by analytic tools. Crucially, it generates the necessary load routines, logical and physical data model, database schema, transformations etc automatically from a conceptual model using business language. It runs on Exasol, Snowflake or on Amazon Redshift as you prefer. It is a modern, serverless, cloud-native product that you can find in the AWS Marketplace. Yotilla greatly speeds up the processes of deploying and changing a data warehouse, significantly reducing operational support costs and risk and the time to respond to business change. You can now have a fast, rapidly changing data warehouse, all based on rock solid German engineering. Yotilla makes your data warehouse flexible and enables it to better provide business value.
Solutions
Research

Analytics for Environment Social and Governance (ESG) Data

Yotilla - Automating Your Data Warehouse

Options for analytic databases and data warehouses (2022)

Options for analytic databases and warehouses (2020)
