
TIBCO
Last Updated:
Analyst Coverage: Daniel Howard and Philip Howard
TIBCO was founded in 1985 and has been at the forefront of information bus technologies since its inception. Over 4,000 customers worldwide rely on TIBCO to manage information, decisions, processes, people, and data in real time.
During its life it has made a number of acquisitions, most recently Information Builders, preceded by SnappyData, Orchestra Networks, Scribe Software, and Alpine Data Labs. TIBCO has some 1,000 BPM customers, with heavy concentration in the financial, telecommunications and government sectors. Its customers include ADIS, BMO, BNP Paribas Security Services, Citibank Asia, First Citizens Bank, KPN, and Société Générale.
From October 2022, TIBCO became part of the broader Cloud Software Group, a portfolio of businesses including Citrix. This conglomerate now has eight semi-independent business lines, of which TIBCO is one.
TIBCO – The ready-made road to the Edge for enterprise users
Last Updated: 1st August 2023
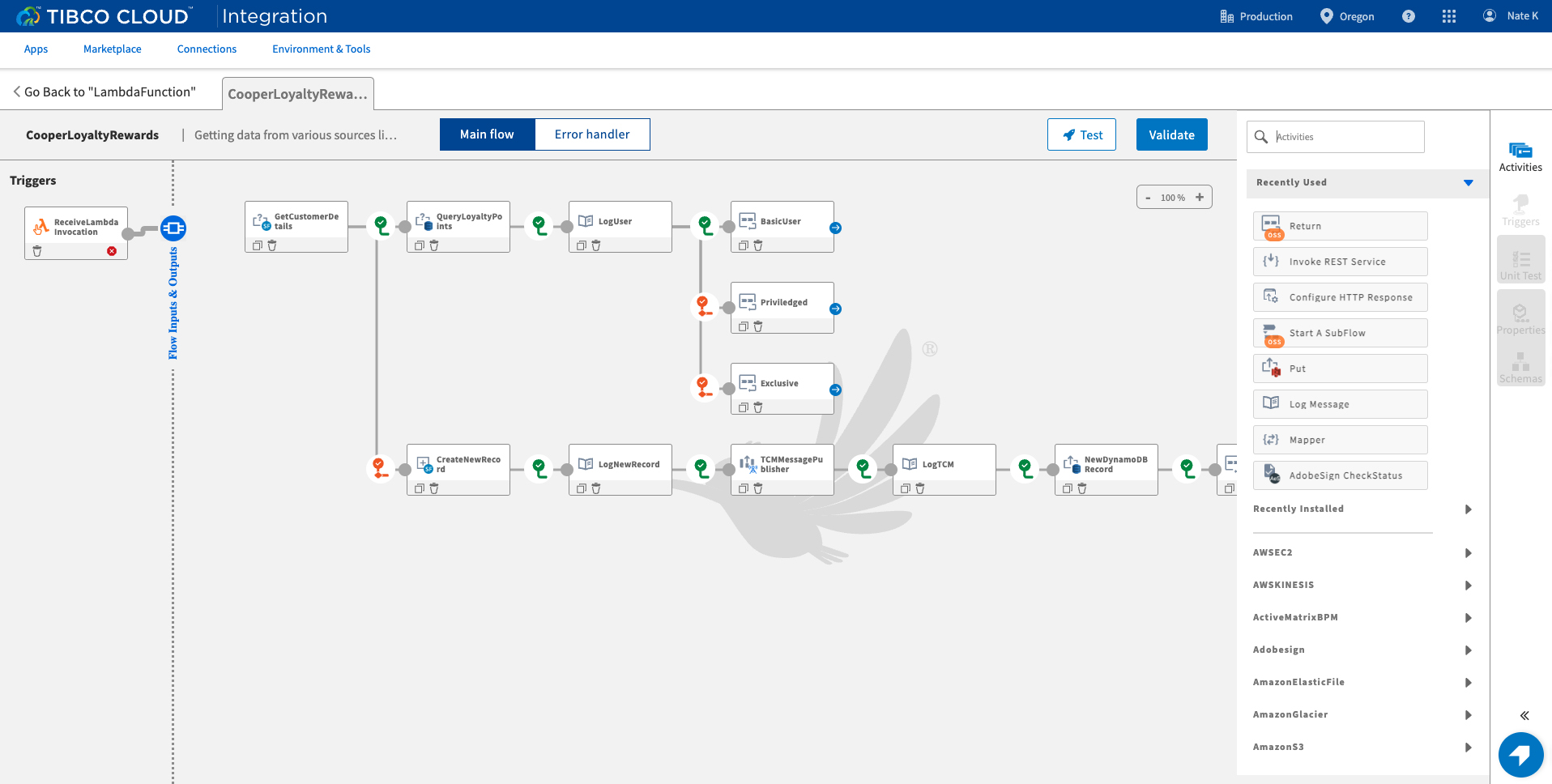
Fig 1 - TIBCO Cloud - Integration
TIBCO is not offering a product or point solution for use in building compute and data management services out to the Edge. Rather, it’s vision is to offer an environment capable of providing both the integrated connectivity and the management of the whole environment, and targeted at its existing customer base – the large, established enterprises. That does not mean it would automatically turn down a serious approach from a new customer, but it is the view of both TIBCO itself and Cloud Software Group that their existing customers will generate significant amounts of new business.
Large enterprise infrastructures are now facing development out to the Edge at the same time as facing the situation where their work environments change continually rather than a series of episodic revolutions. In addition, the depth and breadth of data facing business users, where that data is generated, acted upon and stored is now a fundamental issue.
For many large enterprises the issue is no longer about databases or the technology underpinning data, it is about the data itself, wherever it is physically located, as an addressable, exploitable entity. TIBCO’s metadata database, Tibco Cloud Metadata, is designed to help users pull together radically different forms of data that pertain to a specific subject or project.
Most of the tools required already exist to provide services out to the Edge, but there is one that has been specifically engineered for the sector. This is TIBCO Flogo Enterprise, TIBCO’s fully supported implementation of the open-source Project Flogo Framework. Designed to allow developers to build ultralight, event-driven microservices, it uses browser-based flow design technology to allow users to start running logic and preferred browsers on any device that has a suitable processor chip on-board. This means that business process logic and system control functions can be distributed down to the very end point devices of the network.
The coming TIBCO management platform is envisioned as the key system that allows all the elements of Edge computing to become an integral component of the largest and most complex enterprise environment. This does not mean, however, that the company is pitching to be the provider of all the tools, applications and services that such companies will require, and certainly not as a ‘single SKU that is the universal answer to everything’. It definitely aims to stick with what it is best known for – tight integration of the elements such businesses need to exploit, and extending the full facility of them across the widest extremes of the corporate network, however far that is distributed and convoluted it’s connection requirements may be. The goal is to ensure that users can leverage their resources to best advantage wherever they, or the resources, are.
The key TIBCO contribution is that the Edge, at scale, becomes an integral and native part of the whole corporate infrastructure. This brings two specific advantages: one allows Edge devices, particularly as they develop from passive sensors to become small, duplex systems that can be re-programmable – in the field or via the Web – to accommodate changes in the tasks they are required to perform. The second is that the data flow of a business process can be layered and widely distributed, reducing the overall time and costs of excessive data movement. Individual devices can process local raw data into something of value, which in turn can be processed in departmental/regional hubs or nodes, which then provide data of immediate value to the business up the chain to the main data centres. Reports can then be sent to executives in formats suitable for a wide range of end user clients – from laptops to smartphones to Raspberry Pi-based devices.
An important factor here is the increasing penetration of 5G mobile communications, which TIBCO sees as offering the potential to make the Edge increasingly smart, which in turn is likely to have the effect of increasing the value and importance of the Edge, moving the Centre of Gravity of the whole corporate network down towards the highly distributed end.
This trend is only likely to increase as AI is added to Edge capabilities. For example, AI is already finding real-world applications in areas where only limited real-time choices and options are possible and the speed of decision making is the primary value, an application type that can be widely expected to be found in edge computing operations.
The company sees the potential for applications such as these to be able to perform detailed, in-depth forensics, in real-time and at the point of occurrence, as would be possible with a major forensic application running on the main back-end data centre – and providing not only a result but also actions based on that result, far more quickly. In applications where the action concerns the location of a shipping container speed may not seem overly relevant, but when the application is the safe management of a loaded highspeed train, getting a result and applying it can prove vital.
Another important aspect, especially when it comes to the development of Edge systems and services as a new part of established enterprise environments, is the provision of effective governance services. TIBCOs long track record with large enterprises means that it already brings extensive skills and capabilities in providing and managing governance services at both scale and complexity. Some smaller businesses may find this capability important to them as they break into new markets.
Different sectors of business will obviously have different requirements when it comes to the specific tools that are required, and TIBCO has a simple policy for such areas, its goal is to seamlessly integrate with the tools and platforms the customer selects or already uses, on the basis of: ‘why develop it when you can connect to it’.
TIBCO Data Science Model Operations
Last Updated: 17th January 2020
TIBCO Data Science is an analytics and data science platform with a notably broad remit. The product’s features include self-service data preparation, a wide range of functions for developing analytic models, natural language processing, in-database analytics, real-time scoring, a built-in rules engine, support for languages such as R and Python as well as PMML (predictive modelling mark-up language), robust visualisation capabilities and a large number of connectors (both to a variety of data sources and to other tools).
However, in this report we will be focusing on its support for model management. We are particularly interested in examining the product’s capabilities for scaling up from a mere handful of models to hundreds, thousands, or even tens of thousands; deploying, tracking, auditing and governing models across the enterprise; and exposing both data science modelling techniques and the models themselves to a wider audience in such a way that business users can take advantage of them, thus breaking out of the ‘data science silo’ and maximising the benefits of data science modelling to your organisation.
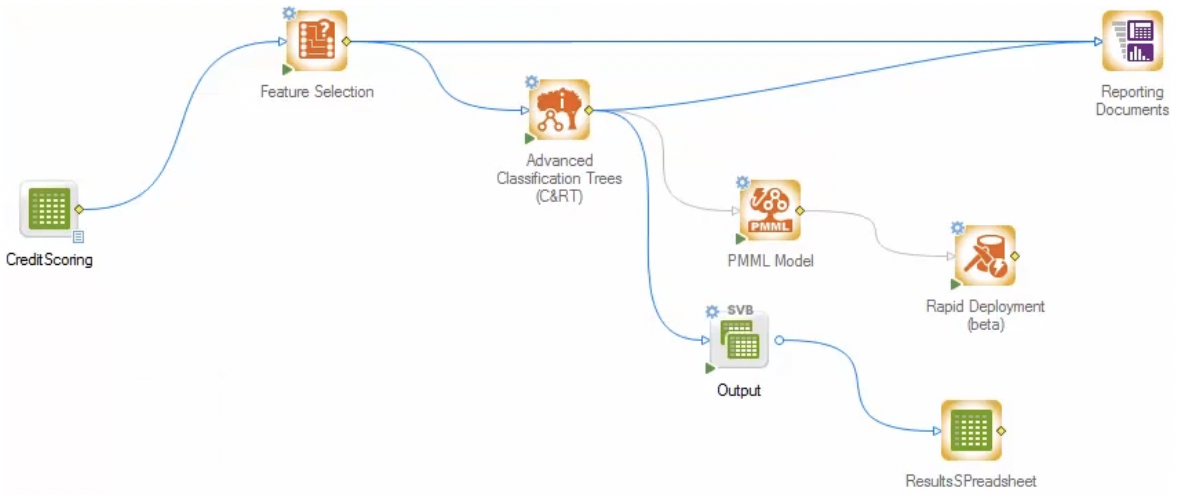
Fig 01 - A model flow in TIBCO Statistica
The core of model management in TIBCO Data Science is the model flow. As seen in Figure 1, this is essentially a form of workflow, created within Statistica, a component of TIBCO Data Science, using a no-code GUI. These flows contain data inputs, models and outputs (shown in Figure 1 in green, orange and purple, respectively) as well the standard flow controls. Business logic can be implemented within a workflow via a rules node, and the flows themselves can be saved as templates and reused inside other model flows. The latter capability is particularly valuable because it allows dedicated data scientists to create complicated, in-depth models and flows, before allowing business users to situate them within the appropriate business processes.
Models and model flows are centrally stored and managed within the platform and accessed via a file-tree structure. Models are versioned, with all previous versions stored within the platform, available to be accessed, deployed or reverted to, as necessary. Third party models (that is, models not created within the data science platform – all standard languages are supported) can also be imported into the platform.
Models and flows held within TIBCO Data Science can be deployed across the broader range of TIBCO products. For example, you could publish your models to the Artifact Management Server, a common model repository, to expose them to TIBCO Streaming (formerly known as StreamBase) for use with streaming analytics, or send them to Spotfire to drive data visualisations. You can also monitor and retrain models en masse via the Monitoring and Alerting Server (a component of TIBCO Data Science Operations), and models can be exposed for external use via OData.
TIBCO Data Science also features a number of collaborative capabilities between data scientists and business users that come into play with model management. Models and model flows (as well as other objects, such as projects) can be shared and worked on collaboratively across the platform. Moreover, models and model flows can be parameterised and tailored to business users before being exposed to them. This might include only exposing a subset of the model’s parameters, renaming fields to make them more easily understood, setting default values, and so on. The aim is to expose all the functionality that a business user needs, and no more, thereby making their interactions with the model as simple as possible. Once a model has been tailored in this way, it can be saved as a template and shared as needed. This is also tightly integrated with TIBCO Spotfire so citizen data scientists can run data science workflows directly from a Spotfire dashboard.
TIBCO Data Science is a platform for analytics in the broadest possible sense. It’s undeniable that machine learning, AI and data science are becoming ever more popular and important parts of analytics, and as a result, if you are leveraging analytics you are almost certainly leveraging analytical models. The sheer amount of these models is growing: we expect large organisations to be utilising thousands or even tens of thousands of models in the near future, if they aren’t already. At that quantity, model operations and management is essential, and TIBCO provides it along with all of its other capabilities.
What’s more, as modelling becomes more common and more popular, data scientists will be more needed (and therefore more in demand) than ever. While TIBCO (or other product) can eliminate the need for data scientists, its collaborative capabilities do enable more effective and efficient use of the data scientists and citizen data scientists you have, by enabling business users to take a larger role in the modelling process. This maximises the value of your data scientists, while providing a measure of self-service for your business users.
The Bottom Line
Model management will soon be essential for any serious analytics solution. TIBCO Data Science not only has it, but integrates it with a wealth of other analytics tools and products.
TIBCO Spotfire (for time-series)
Last Updated: 28th February 2020
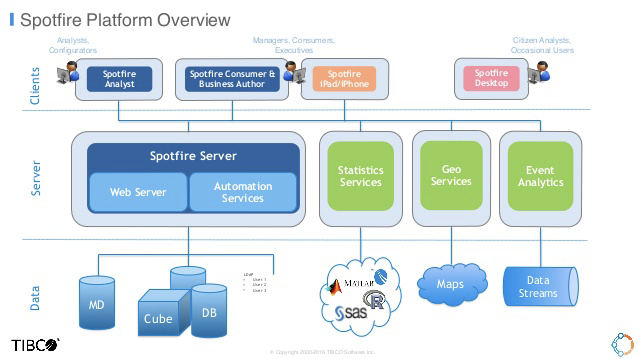
Fig 01 Spotfire marketecture
Spotfire is a broad, general-purpose analytics offering that encompasses data visualisation, business intelligence, analytics (including AI-based predictive analytics) and data preparation; running against historic and/or real-time (streaming) data. A marketecture diagram for the product is shown in Figure 1. However, in this InBrief we are concerned specifically with its time-series capabilities when analysis of historic data is required and, as a complementary technology, the ability to combine this with geo-spatial information.
The product is available both on premises and in the cloud and, in the latter case, a managed service offering is available. Pricing is by user persona and a free 30-day trial is available.
Customer Quotes
“We’ve reduced the time by over 50% that it takes to create usable information for hospital administrators. We don’t have to crunch all this data because it’s automated.”
BroadReach Healthcare
“We developed a vessel speed and route monitoring application that analyses the vessel’s speed and distance against a complex variety of factors. The application has helped ocean carriers reduce fuel consumption by up to 3.5% over the past two years.”
CargoSmart
From a time-series perspective Spotfire works on the basis of time windows (various options) that you define. Specifically, it provides high level operators called Aggregate, Pattern, Join, Query and Gather, which can be combined and sequenced as required. Some 58 aggregate functions are built into the product, including both basic analytical functions (mean, median, standard deviation and so on) and more advanced statistical functions (slope, intercept, correlation, exponential moving average and so forth). A Java aggregate function API is available for users to define their own aggregate functions, if desired.
The Pattern operator has its own sub-language for sequential, value-based and temporal patterns, to which Boolean logic may be applied. Patterns within streams may also be detected using one or more operators in combination. The Join and Gather operators join streams either as two-way or multi-way joins respectively. Finally, the Query operator allows you to join a stream against a relational table, so that you can combine real-time and historic data. Streams may be buffered in such a way that arrival order is not material to the results of the operation so long as emission order is not material either.

Fig 02 Mapping the human body
Of course, for many IoT and industrial applications support for time-series analytics is not enough: you also need to combine this with location intelligence and Spotfire provides significant capabilities in this regard, supporting both geographical and non-geographical (see Figure 2) maps. Multi-layer mapping lets you zoom into successive levels of detail, for example, from the country to the state, county, city, neighbourhood, and house level. Moreover, you can choose to see whatever associations are relevant to you, with data specific to the level you are working at. The product provides worldwide address-level geocoding as well as route calculations with step-by-step directions.
More generally, the product uses native connectors, not just for its analytics but also for data preparation (TIBCO calls it wrangling) so that you can connect to and blend data from a variety of relational and NoSQL databases; and to cloud environments like Amazon Redshift, Databricks, RDS, Microsoft Azure SQL Database, Google Analytics, and Salesforce.com. You can also build your own custom connectors. Natural Language Query capability – which is used throughout the product – lets you search for any data or connector.
From a more general standpoint, Spotfire supports AI/ML and predictive models developed in other TIBCO tools such as Statistica, as well as supporting languages such as R, Python and Java, and models developed in third party environments such as Spark MLlib or H20 models, or which can be imported via PMML (predictive modelling mark-up language). These can be scored on streaming data by operators in Spotfire. Also notable is the TIBCO Artefact Management Service, which supports governed deployment for these models. Once approved, then can be pushed out to Spotfire applications, or the applications can be set up to query for updated models at regular intervals, or under certain conditions. These models can be updated at runtime without requiring any application downtime.
Spatial analytics is commonplace and all the providers of streaming analytics platforms have the ability to process streaming data via time windows, in some sort of similar fashion to TIBCO Spotfire. In addition, there are lots of products that enable you to visualise time-series data. What is rare – even to the point of almost non-existence – is to find an analytics platform that has any sort of sophisticated functions for analysing historic (stored in a database) time-series data, whether as a stand-alone function or in conjunction with real-time data. There are specialised tools that focus only on time-series data but we know of no other general-purpose tool, apart from TIBCO Spotfire, that has this ability.
The Bottom Line
TIBCO Spotfire appears to be unique. Not only have we been unable to find any product with comparable capabilities but none of the database vendors with time-series capabilities could point us in any different direction. We don’t think anything more needs to be said.

TIBCO Streaming
Last Updated: 14th December 2021
Mutable Award: Gold 2021
TIBCO Streaming is a streaming analytics product (and the successor to TIBCO StreamBase) that strives to help you to better connect, understand, and interact with your streaming data. Moreover, it does not stand alone: it is a part of TIBCO’s broader suite of analytics – or, in TIBCO’s parlance, ‘connected intelligence’ – offerings that, taken together, provide an end-to-end solution for enterprise analytics and BI (Business Intelligence). This ties neatly into the company’s approach to streaming analytics as a whole: specifically, that it is best treated as one part of an encompassing, holistic analytics infrastructure, and one part of the broader analytics story, than as a single, perhaps even siloed, capability.
Major features include the on-demand delivery of streaming services suitable for consumption by any type of user, regardless of technical expertise, thus democratising streaming data; significant support for integrating machine learning with your streaming data, with additional support planned to further enable streaming data science; a cloud-native architecture that includes elastic scaling, automated recovery, and support for Kubernetes; consumption-based pricing; and, of course, the product’s signature visualised streaming analytics. A variety of deployment options are available, including cloud environments (notably AWS, Microsoft Azure, GCP, and OpenShift, as well as TIBCO Cloud) and as a Docker image.
Other TIBCO products contribute to the company’s streaming analytics offering by adding other types of analytics – predictive analytics, embedded analytics, complex event processing, and so on – to the mix. TIBCO Spotfire, which is frequently delivered alongside TIBCO Streaming, works particularly well as a BI platform that provides simultaneous (and, on your part, almost effortless) access to both historic and streaming data via a friendly user interface.
Customer Quotes
“We automated the Melbourne Airport with TIBCO [Streaming] in 12 weeks with 6 people, and release new innovations every 2 weeks.”
Melbourne Airport
“We’ve been able to take our 500 million messages and cull them down to 1,000 meaningful alerts a day that can be managed very efficiently and proactively. That is not something we could have done previously.”
Convergex
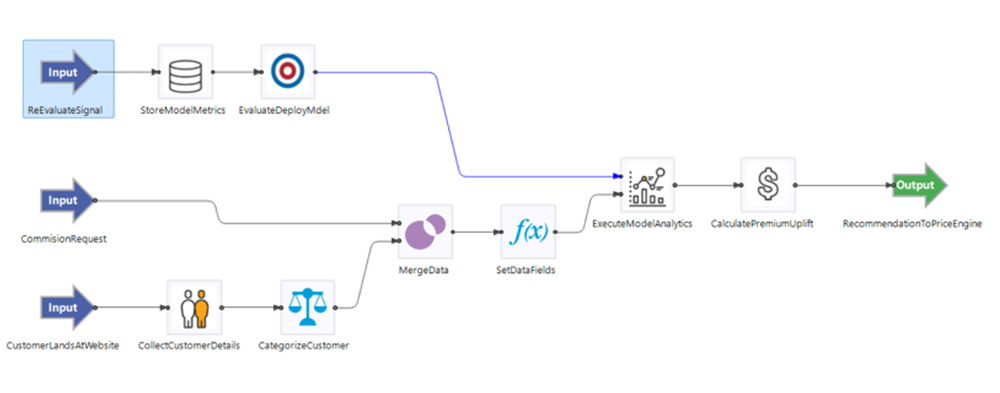
Fig 1 - Creating an app in TIBCO Streaming
Streaming is a high-performance platform for rapidly building and deploying real time streaming analytics applications. It enables a variety of different user personas, ranging from professional developers to highly knowledgeable but non-technical domain experts, to build these applications using a browser-based, low/no-code visual interface, as shown in Figure 1. The ease of use this approach provides allows all of the aforementioned personas to leverage self-service streaming data as part of their analytics projects without undue difficulty, thus creating additional value from your data, reducing the time spent developing apps, and democratising your streaming capabilities.
A wide variety of accelerators for Streaming are freely available via the TIBCO community. Each one consists of a collection of pre-built components that have been optimised for a particular use case. Examples include financial fraud, case management, and insurance pricing. Notably, a number of accelerators are built to support the Internet of Things (IoT), including the Connected Vehicles Accelerator, and the IoT Drilling Accelerator. Combined with the embedded BI and analytics capabilities TIBCO provides, and the option to deploy on the edge, this allows Streaming to perform well in IoT environments.
Although Streaming integrates with several other TIBCO products, its integration with Spotfire, TIBCO’s general analytics platform, is particularly strong. For instance, Spotfire offers a shared environment for storing, managing and deploying assets across both products. Notably, this includes the application of predictive, machine learning models to streaming data, deployed within Streaming itself. On that front, Streaming supports models written in Java, Python and R (the latter via an accelerator), as well as PMML (Predictive Model Markup Language) and SparkML.
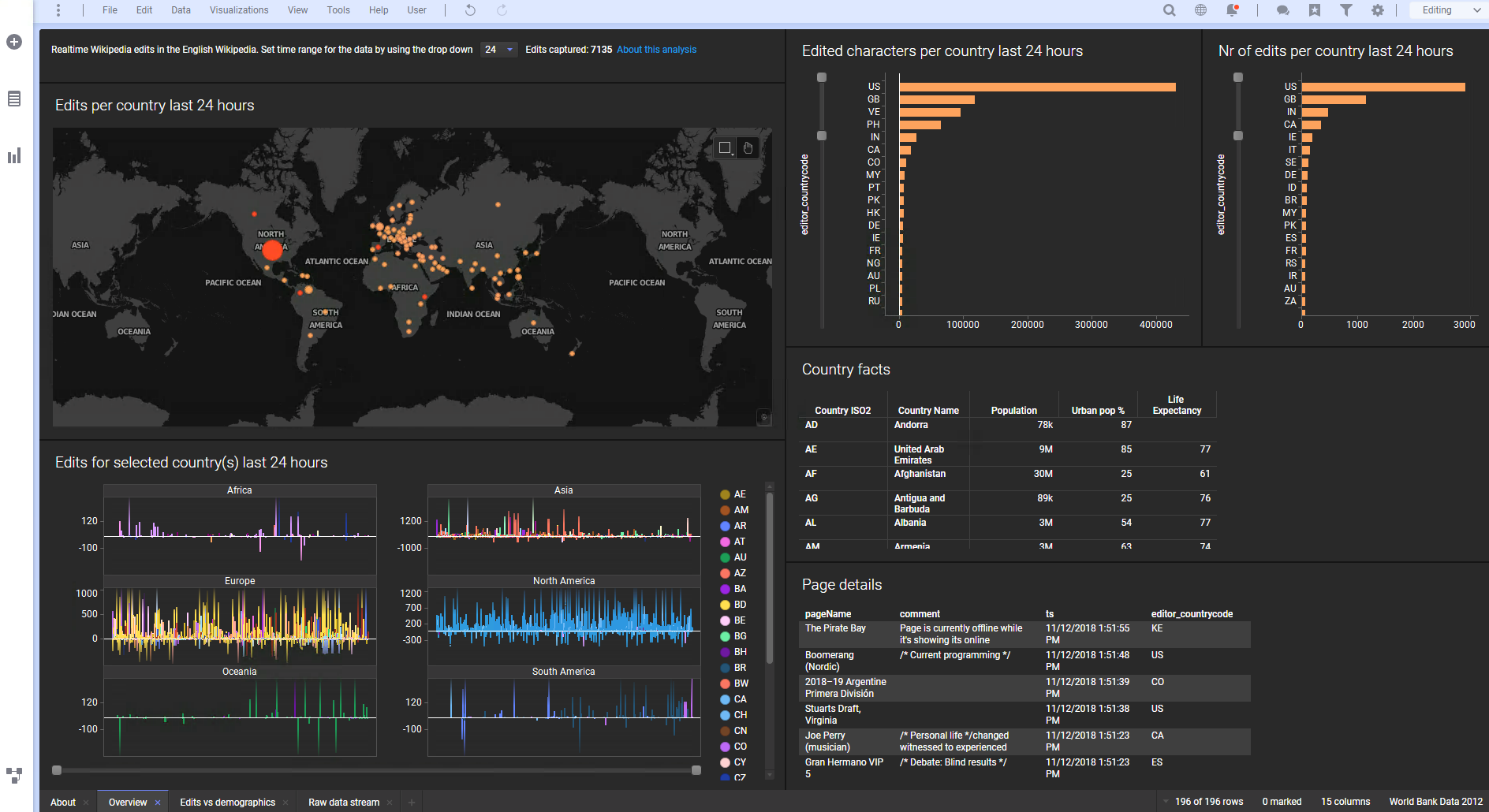
Fig 2 - A Spotfire analytics dashboard
For a further example of this integration, Live Datamart, previously a separate product but now part of Streaming, is an in-memory data warehouse equipped with a continuous query processing engine that drives alerting, user actions, and decision rules that can automatically take action under specified conditions. More to the point, it also provides live, real-time visualisations of your streaming data that can be accessed and assembled into dashboards using Spotfire (see Figure 2).
As a streaming analytics solution, Streaming is remarkable for two core reasons. First, by adopting low/no-code design principles and a friendly user interface, it makes the development of streaming apps faster, easier, and above all, more accessible. This enables self-service streaming app creation, in particular for business users and domain experts, who would otherwise typically have to go through a lengthy back-and-forth with IT to get a new streaming app built (by which point the window of opportunity for the original use case may have closed). In turn, this should allow you to analyse and react to streaming data with much greater agility.
Second, TIBCO places the emphasis not (or at least, not entirely) on streaming analytics as a solution in and of itself, but as one part of a comprehensive analytics suite. This is supported by the company’s other products, many of which tightly integrate with Streaming. As already discussed, Spotfire is particularly notable in this regard. This is a good approach: ultimately, analytics is about generating actionable insights, and it stands to reason that a more comprehensive and connected analytics pipeline is going to generate more useful, more complete, and more accurate information from which to generate those insights.
There are other reasons to care about TIBCO’s offering, of course: these are merely the most major. Other notable advantages include the product’s support for machine learning, its suitability for deployment to the edge or the cloud, and its range of accelerators, which frequently enable significantly greater time-to-value.
The Bottom Line
TIBCO Streaming makes it easy to build streaming applications. It is a complete streaming analytics platform, and together with the rest of the company’s ecosystem, can play an integral part in a comprehensive and holistic analytics solution. In short, it is certainly worth your consideration.
Mutable Award: Gold 2021

Research

Master Data Management (2023)

TIBCO - The ready-made road to the Edge for enterprise users

Understanding data virtualisation

Master Data Management (2022)

Streaming Analytics (2021)

TIBCO Streaming

Master Data Management (2021)
