
Gathr
Last Updated:
Analyst Coverage: Daniel Howard
Gathr is a next-gen, cloud-native, fully managed, no-code data pipeline platform that acts as an all-in-one solution for data integration and engineering. It offers ETL, ELT, reverse ETL, ingestion, CDC, streaming analytics, machine learning, DataOps, and more.
Gathr Data Inc. was founded by a team of industry veterans and visionaries from Impetus. It is based in Los Gatos, USA, with multiple development centres in India.
Gathr
Last Updated: 14th December 2021
Mutable Award: Highly Commended 2021
Gathr (formerly StreamAnalytix) is positioned as a self-service-oriented data pipeline platform, and more specifically, as an all-in-one platform for creating, managing, and deploying data pipelines. This includes data processing, ingestion, cleansing, transformation, blending, loading, preparation, integration, visualization, analytics, and more. Its analytics capabilities are particularly rich, and can be performed in real-time on streaming, batch, and micro-batch data. This is no surprise, considering the product’s origin as a dedicated streaming analytics offering. At the same time, the breadth of capability available explains the recent rebrand: ‘StreamAnalytix’ is too narrow a descriptor for what the platform has become.
Gathr’s streaming analytics capability is itself built on top of several popular and mature open-source technologies. Rather than trying to replace, say, Kafka, Impetus sells Gathr’s streaming analytics on the promise that it will save you the trouble of combining these technologies into a single offering yourself, while at the same time providing enterprise level scalability and support. It is available as a SaaS, on-premises, in-cloud, or as part of a hybrid solution. It includes multi-tenancy support, and is compatible with the “big three” cloud providers as well as Databricks.
Gathr is currently available in three editions: Gathr Unlimited is the full, but self-managed, package; Gathr Pro is the pay-per-use SaaS equivalent; and Gathr Free is a SaaS version with limited functionality (it is largely restricted to data ingestion). Note that at time of writing, Gathr Pro is significantly more limited in functionality than Gathr Unlimited (though not as much as Gathr Free). However, we are told that this will change in relatively short order.
Customer Quotes
“[Gathr] helped us replace 1.5M lines of code through its visual interface.”
Communication Data Analytics
“[Gathr] helped us build and make our use-case production ready in 2 weeks that would otherwise take us 3 months.”
Broadcast Media
“[Gathr] helps us identify anomalies in our incoming data in real-time. It helps us scan ~10k applications for any abnormal user behavior.”
Banking and Finserv

Fig 1 - Model training pipeline in Gathr
Gathr enables you to assemble, debug, and deploy data pipelines and applications using a low/no-code, drag-and-drop visual interface, shown in Figure 1. It will also present an automated, dynamic view of the schema and outputs of your pipeline as you build it: a useful sanity-checking measure. A variety of pre-built components (including more than three hundred ETL functions) are provided for your pipelines, and you can modify these or even add your own if necessary. Moreover, Gathr pipelines have a self-healing capability, and will hence automatically recover from failures whenever possible. Pipeline and data set management are also provided, complete with version control (either using the platform itself or outsourcing to Git) and data profiling.
The platform also features extensive support for machine learning. This includes model training, building, scoring, and deployment, as part of both real-time and batch processes and – in the latter case – via either the platform itself or a REST API. In fact, Figure 1 displays a model training pipeline. Gathr also supports a variety of machine learning algorithms, as well as SparkML, H2O, TensorFlow, R and Python. PMML (Predictive Model Mark-up Language) is also supported, providing model portability. A variety of model management techniques are also supported, including A/B and Champion/Challenger. It also offers hot-swapping and model versioning.
Aside from all this, the product also boasts data lineage, metadata management, data monitoring, alerting, and CDC capabilities (the latter on MySQL, MSSQL, PostgreSQL, Oracle and MongoDB), as well as over thirty connectors to third-party and open-source products. It supports Apache Storm, Spark and Flink as stream processing engines, but uses the same front-end for all three. In addition, you use Gathr apps in exactly the same way regardless of the underlying streaming engine. This makes moving from one engine to another a relatively easy task, since you won’t need to redesign your apps or get used to a new interface. Impetus also offers a migration utility to help you move from various competing platforms to Gathr.
Gathr has a number of strengths. Its breadth is perhaps the most apparent: it now stretches far beyond just streaming analytics. This both increases its overall value and applicability as a product, and makes it easier to integrate your streaming analytics with many of your other data integration and engineering needs, since they will be part of the same platform. It’s also easy to use, thanks to its low/no-code visual pipelines and consistent user interface, and provides impressive support for machine learning.
What’s more, by leveraging open-source technologies as part of an enterprise-grade solution, Gathr provides many of the advantages of open-source development (such as community-driven development, future-proofing and whatnot) without its most major drawbacks (such as lack of enterprise support, and the need to assemble your solution yourself, both of which are taken care of for you by Gathr).
Gathr Pro (the premium SaaS version of Gathr) is particularly interesting, or rather, it will be when its full intended functionality is available. At that point, it would give you a fully-managed, cloud-deployable solution that can start small, with a low cost and footprint, then scale up with you as you grow, creating a very “hands-off” data pipeline experience (and for streaming analytics in particular). Moreover, even without considering Gathr Pro, the scalability and cloud aspects of this already exist as part of Gathr Unlimited.
The Bottom Line
Gathr offers a wide-ranging data pipeline solution that is notably well-positioned to address streaming analytics. It combines the strengths of open source with the reliability and support of an enterprise solution, in the cloud, and at scale, while also offering significant ease of use, integration, and SaaS capabilities, among other things. In short, it is certainly worthy of your consideration.
Mutable Award: Highly Commended 2021

Gathr Data Integration
Last Updated: 3rd October 2022
Gathr is a unified self-service data pipeline platform, and more specifically, an extensible and universal platform for creating, managing, and deploying data pipelines. Its capabilities include data integration, processing, ingestion, cleansing, transformation, blending, loading, preparation, analytics, and more. It also supports multiple deployment modes:
- SaaS: Gathr is offered as hosted software as a service and licensed using a low-commitment, pay-as-you-go model based on compute consumption. Moreover, anyone can register and start using it in only a few minutes.
- Cloud: Gathr can be hosted in your cloud account, and supports leading cloud platforms like AWS, Azure, and Google.
- On-premises: Gathr can be hosted in an on-premises environment on enterprise servers or virtual machines leveraging existing infrastructure.
Customer Quotes
“Gathr helped us power “in-the-moment” actionable insights from massive volumes of complex operational and digital interaction data.”
United Airlines
“Gathr helped us unlock business use cases for upselling, cross-selling, and customer retention with speed and scale. With Gathr, we brought all data sources together, built pipelines in a true self-service way, and retired legacy data platforms.”
Truist
Gathr helps you collect data from multiple sources and transform it to create a single source of truth. This data can be further utilised for accurate and high quality and reporting and analytics.
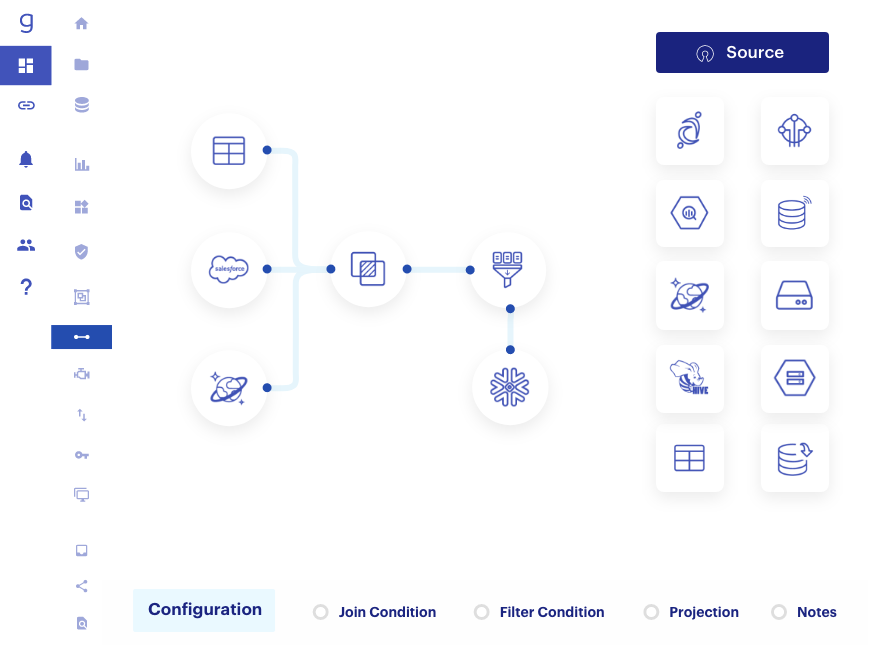
Fig 1 - Gathr data pipeline builder
More specifically, it enables you to assemble, debug, and deploy data pipelines using a low-code, drag-and-drop visual interface, seen in Figure 1. It automatically infers schema information, and is thus able to present an automated, dynamic view of the schema and outputs of your pipeline as you design it. A variety of pre-built pipeline components are provided out of the box, and you can modify these or add your own as necessary. Gathr pipelines have a self-healing capability and will automatically recover from failures when possible. Pipeline and data set management are also provided, complete with version control (either using the platform itself or outsourcing to Git) and data profiling.
The product offers a wizard-driven interface for data integration, as well as a drag-and-drop transformation builder with over 300 pre-built ETL functions. For simple ETL jobs, these will likely prove sufficient. For anything more complex, Gathr also provides a full-blown low-code environment for building ETL, ELT and Reverse ETL processes, in a similar manner to its data pipelines.
Gathr supports batch, micro-batch and streaming ingestion as part of data integration and can incorporate data classification into the ingestion process. Its transformation view (provided as part of its transformation builder) highlights all unique column values for you to operate on, as well as offering automated inspection functionality. ETL and other data integration jobs can be scheduled or triggered by a particular event, as you prefer, and lineage information for all executed jobs is available. Moreover, a built-in error search is available for each job.
The product also boasts data lineage, metadata management, data monitoring, machine learning, alerting, and CDC capabilities (on MySQL, MSSQL, PostgreSQL, Oracle, and MongoDB in the latter case). CDC in particular can be leveraged alongside data integration to capture and process data changes in real time. Finally, the company offers more than thirty connectors to various third-party and open-source products, and there is also a migration utility available to help you move over to Gathr from various legacy ETL platforms.
There are several reasons to care about Gathr as a data integration solution and as a data pipeline platform. Its analytic capabilities (especially streaming analytics) are well developed, including significant support for machine learning. It leverages a low-code, wizard-driven, highly visual development style that enables self-service and ease of use, with pre-built applications available for common use cases. It makes extensive use of open-source technologies, thus providing many of the attendant benefits with few of the traditional downsides (such as lack of enterprise support). Finally, it is lightweight, quick to deploy, and offers good time-to-value. At the same time, it is highly (and automatically) scalable, meaning that you can start small and scale it up as necessary. What’s more, built-in orchestration allows for multiple pipelines to be played one after the other based on preconfigured rules and triggers.
The Bottom Line
Gathr is a relatively broad platform-based solution that caters to data integration, pipelining, and engineering use cases in equal measure. Its support for (and use of) both batch and streaming analytics, as well as its ability to customise and use open-source technologies, are particularly appealing.

StreamAnalytix
Last Updated: 11th December 2018
Mutable Award: Highly Commended 2018
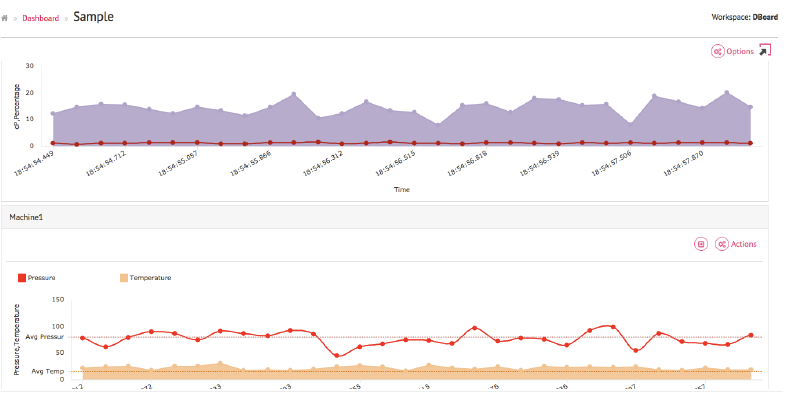
Figure 1 – A real time dashboard in SteamAnalytix
Impetus StreamAnalytix is an analytics platform for both real time, streaming data and batch processing. It operates on the principle that open source technologies in the streaming analytics space (for example, Apache Kafka and Apache Spark) are in many cases mature enough to offer significant advantages over proprietary solutions (such as future proofing and community support), but that orchestrating and integrating several of these technologies together into a complete, enterprise-ready solution is complicated, slow and expensive. Therefore, Impetus has chosen to build StreamAnalytix on top of popular open source technologies, combining them into a single offering within the product, and saving you the trouble. It does this while providing enterprise-level scalability and support. In essence, it is an open source powered, enterprise-grade platform.
More than that, StreamAnalytix is not just an analytics product. All told, it provides end to end, 360-degree data processing, including ingestion, cleansing, transformation, blending, loading and visualisation (via real time dashboards), as well as, of course, analytics. It is available on-premises, in-cloud, or as part of a hybrid solution. In addition to StreamAnalytix, a freemium offering, Visual Spark Studio, is also available.
Customer Quote
"StreamAnalytix enabled $5m annual savings in call centre costs."
Leading wireless & telecom services provider
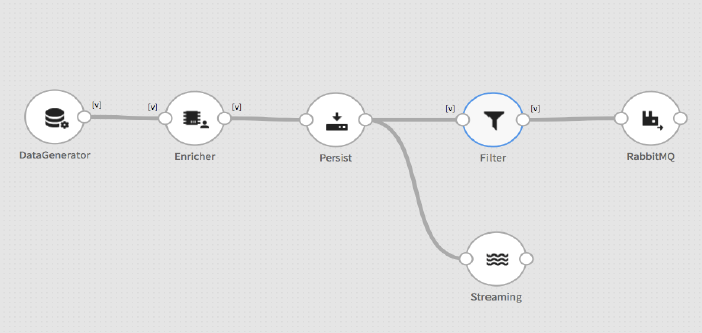
Figure 2 – Example data pipeline
StreamAnalytix allows you to build data pipelines and analytics applications using a visual UI (user interface) by dragging and dropping blocks of pre-built, integrated functionality onto a canvas and arranging them into a model. This process is very simple, and allows you to very quickly build out use cases into functional applications. It can be used to build batch, micro-batch, and event-based (in other words, streaming) analytics applications, and also features a built-in testing interface. Moreover, this UI, along with the streaming applications you can build with it, are treated by StreamAnalytix as abstractions on top of the underlying streaming engine you are using. This is important for two major reasons: firstly, it means that StreamAnalytix can support multiple streaming engines, presently including Spark, Storm and Flink; and secondly, and arguably more importantly, it means that the streaming engine you are using can be switched out without any change in either the front-end interface or your existing streaming applications. This makes it relatively simple and straightforward to change your streaming engine, and it enables you to do so without retraining staff to use a new interface or rebuilding existing streaming applications. Additionally, StreamAnalytix can be installed on and integrated with any existing streaming analytics deployments that you might have.
StreamAnalytix also features extensive support for machine learning and predictive/prescriptive analytics. The platform allows you to train your machine learning models using either batches of historical data or in real time via streams, then deploy those models in real time to drive analytics and scoring for both batch and stream processing. StreamAnalytix supports a variety of model management techniques, including A/B and Champion/Challenger testing. Moreover, it also offers support for ‘hot swapping’ of models, meaning that whenever a model in training becomes more effective than a model in deployment, the two can automatically be switched over, so that the model that’s in use is always the most effective model you have. The product supports a variety of machine learning algorithms, including SparkML, TensorFlow and Python models. PMML (Predictive Model Mark-up Language) is supported for model portability.
In addition to StreamAnalytix, Impetus also offers Visual Spark Studio. This product is a freemium, stripped down version of StreamAnalytix proper, suitable for building creating, testing and running Spark applications. It is freely available for a single server or desktop.
The streaming analytics space is all about speed. By making the analytics process faster, organisations seek to make more responsive, more effective and more timely decisions, ultimately trying to react in seconds, not hours, to the data that is entering their system. This is necessary not just to meet the demands of your consumers, but also to compete with other organisations who are meeting those demands.
This need for speed has led many vendors in the space to adopt either micro-batch or event processing, and in the process move away from old batch processing methodologies. However, as it turns out, many organisations still want and need batch or micro-batch processing in addition to event processing. Accordingly, Impetus has chosen to offer all three as part of StreamAnalytix. Moreover, they do so via a unified platform that can manage all three options under one roof. In fact, this is one of the major strengths of StreamAnalytix: the ability to interact with a multitude of different types of analytics (event, batch, micro-batch) and streaming engines (Spark, Storm, Flink) using the same interface and applications.
This inclusiveness might lead you to think that StreamAnalytix isn’t fast. However, this is far from the case. In fact, the product has been benchmarked and tested at one million events processed per second. Additional features are also in place to ensure this performance is maintained, such as alerts that fire if processing speed falls below a certain threshold.
The Bottom Line
StreamAnalytix provides an excellent solution for streaming analytics that combines the strengths of open source with the reliability, manageability and support of an enterprise solution. Together with the end to end data processing, machine learning and batch processing capabilities it offers, it is a powerful solution not just for streaming analytics, but for analytics as a whole.
Mutable Award: Highly Commended 2018
Commentary
Research

Top data integration qualities to watch out for in 2023

Gathr Industry Impact Study: Telecommunications

Gathr Industry Impact Study: Financial Services

Gathr Industry Impact Study: Automotive Insurance

Data Integration: Fivetran, Gathr, Informatica, Matillion

Gathr Data Integration

Streaming Analytics (2021)
