
Analytic Databases (Data Warehousing)
Last Updated:
Analyst Coverage: Philip Howard and Daniel Howard
Analytic databases are those that are specifically focused on queries, “analytics” and “machine learning” performance. They include what have historically been known as data warehouses, data marts, data lakes and data lakehouses and consist of a database implementation that supports the storage and analysis of historic data, either for the purpose of exploring what has happened in the past in order to understand that past, or as the basis for predicting what may happen in the future. We say “historically” because many of the distinctions between these types of implementations are increasingly redundant. In practice, there are really only two types of environment: what used to be known as an enterprise data warehouse (EDW) and everything else. The essential difference is that EDWs provide a “single source of truth” and are used not only to support various types of complex query processing but also simple look-up and similar queries that may be required to support call centres and the like. Non-EDW products typically focus purely on analytics and machine learning.
Whereas an operational database is essentially a write many times and read many times environment, analytic databases offer a write-once read-many times environment. There is therefore a particular emphasis on read performance. Analytic databases also differ from operational databases in that they typically store much larger amounts of data and therefore scalability is a much bigger issue. That said, hybrid databases merge the capabilities of operational and analytic databases into a single environment.
In practice, there are different types of analytic database implementation. Most organisations will have a so-called logical data warehouse where a central enterprise data warehouse (EDW) provides a “single source of truth” for important corporate data but data is otherwise distributed across multiple other analytic databases (data marts and/or data lakes), with query processing enabled through data virtualisation (see data in motion). In addition, some data may need to be replicated – again, see data in motion – across databases and there will also be a requirement to synchronise data where that is the case. Ideally, one would also like a tool that told you the best place to store particular data elements.
Analytic databases support the use of business intelligence, analytic, statistical and reporting tools that are either used to examine what has happened in the past or (increasingly) predict what is going to happen in the future. Often, a data warehouse will be designed to do both of these. In addition, an Enterprise Data Warehouse may support call centre and similar operatives who need to look-up customer information on a regular basis. This range of requirements puts an onus on the database to include features – known as workload management or, in some cases, workload isolation – that will allow all of these different functions to operate in an efficient manner.
Because of the complexity involved, some suppliers in this space do not target the whole range of data warehousing requirements but specialise in particular subsets thereof. In particular, some vendors focus on data lakes only and, in particular, on supporting complex analytics and statistics that go beyond normal run of the mill business intelligence environments.
Key elements for analytic databases are the ability to scale and performance. In the case of the latter, parallel processing capabilities will be required as will an efficient database optimiser. These work by examining SQL queries, re-writing them if necessary, and determining the best way (typically: in which order should joins be performed) in which to run that query most efficiently.
Finally, a key point about analytic databases, and EDWs in particular is in their creation: they need to be designed and loaded. In order to enable these functions data warehouse automation tools (see data in motion) can be used. These not only help with the design of the database schema but will also generate appropriate load scripts.
Anyone who wants to understand what has been happening in order to inform future strategy, to predict future trends or actions or those interested in detecting and/or preventing nefarious activity of various kinds. Relevant managers and C level executives in any of the following cross-industry areas (amongst many others) should be interested:
- Customer acquisition and retention
- Customer up-sell and cross-sell
- Supply chain optimisation
- Fraud detection and prevention
- Telco network analysis
- Marketing optimisation
The biggest trend within this space is towards cloud-based deployments. A variety of offerings are available, whether for private, public or hybrid cloud environments. In some cases, managed services are offered.
Another major trend is the separation of compute from storage, the idea being that neither should be a bottleneck but that you shouldn’t have to pay for extra storage if all you need is more processing power, or vice versa. Moving to a container-based architecture, typically within the context of Kubernetes, is a further significant move that many vendors are taking.
Other trends include the use of time series databases to monitor the performance of your analytic database in real-time; the emergence of data fabrics (and meshes) to enable query processing across distributed environments in order to minimise network traffic (see data in motion); and the implementation of direct support for machine learning algorithms. In respect of this last point it is worth noting that these algorithms include those graph algorithms that can be usefully parallelised. There are a significant number of such algorithms that cannot be parallelised (especially when self-joins are required) and if you need any of these you should consider use of a graph database.
Finally, some queries lend themselves to a row-based underlying capability (for example, look-up queries) while others lend themselves to a column-oriented approach (for instance, “who are our customers in Wisconsin?”). Increasing numbers of vendors are offering both, either by not using a relational paradigm at all, or by offering both row and column storage. The latter tend to be focused on the hybrid database market.
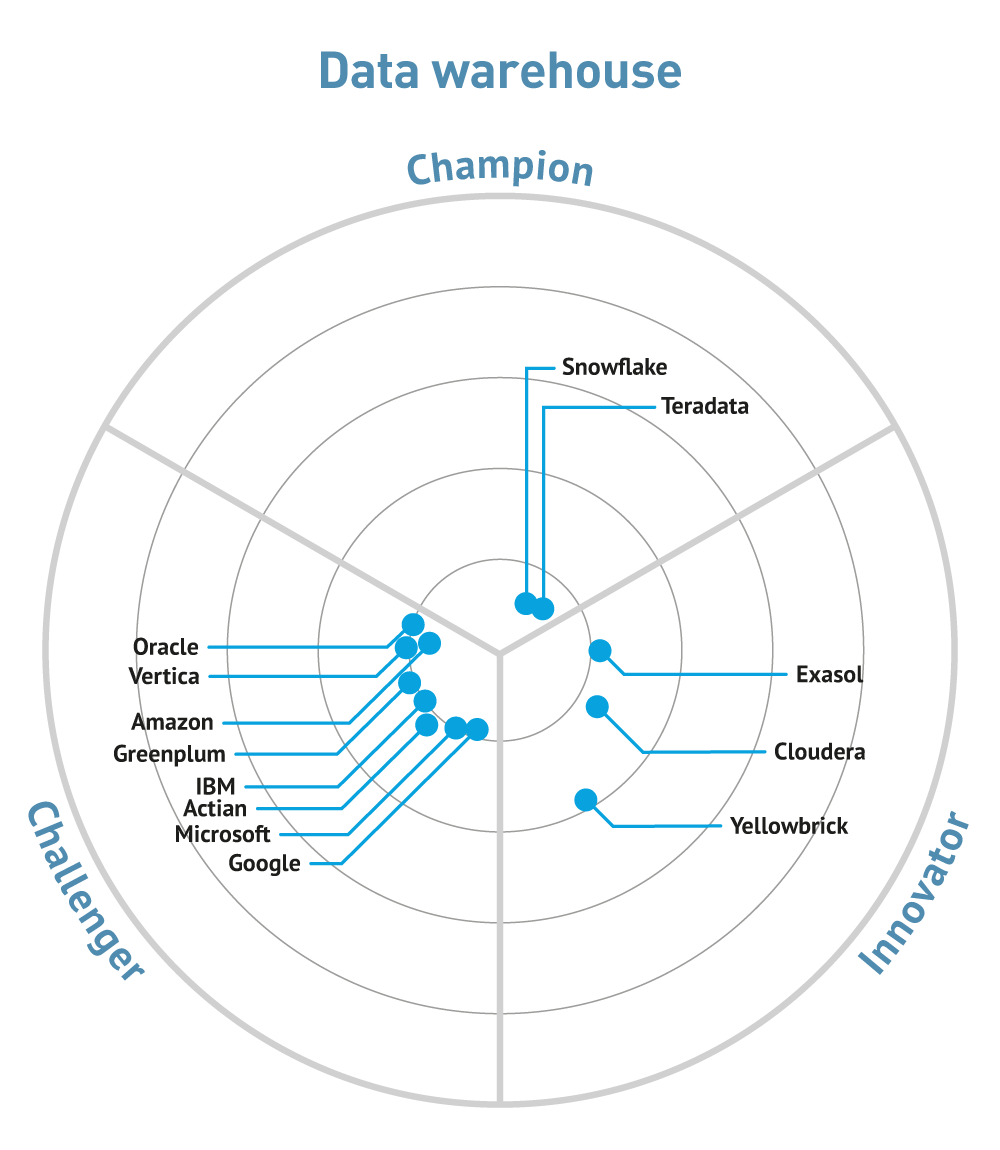
The data warehousing market periodically suffers from disruption and (cloud-based) solutions from companies such as Snowflake and Yellowbrick (which also supports on-prem and hybrid deployments) are doing just that. The first of these, in particular, has gained significant traction though the traditional vendors in this space all offer cloud-based implementations now. For example, Teradata is partnering with Microsoft Azure, while Exasol has announced a SaaS offering on AWS. Also in the analytic database space, multiple smaller companies have announced partnerships with Snowflake. Similarly in-database machine learning is becoming common, most notably with MariaDB (which is in the process of going public) partnering with MindsDB, and Oracle introducing MySQL Heatwave.
Another important partnership announcement is Yellowbrick’s with Nippon Information & Communications Corporation for the former to target the Japanese market. Meanwhile, Databricks has announced a lakehouse platform for the healthcare and life sciences industries. It has also acquired the German start-up 8080 Labs, to support moves into supporting low-code/no-code development. Starburst, meanwhile, has bought Varada (data lake analytics accelerator) and announced partnerships with both Immuta (security) and Aerospike, which itself has announced native support for JSON data models. MarkLogic has acquired SmartLogic (metadata management), and Atlassian has recently introduced the Atlassian Data Lake. For details of recent developments in the graph database space see graph databases.
Downloads
Commentary
Solutions

These organisations are also known to offer solutions:
- 1010Data
- Amazon
- BIReady
- Broadcom
- Calpont
- Databricks
- Dataupia
- Fivetran
- Incorta
- Infobright
- Informatica
- InterSystems
- Kalido
- Kognitio
- Matillion
- Micro Focus
- Microsoft
- OpenText
- Pivotal
- Sand Technologies
- Snowflake
- Tokutek
- VectorNova
- XtremeData
Research

Yotilla - Automating Your Data Warehouse

AI and Generative AI within an Enterprise Information Architecture - Solix and The Operating System for the Enterprise

Data Fabric and the Future of Data Management - Solix Technologies and The Data Layer

Denodo and data governance

Teradata ClearScape Analytics

Teradata VantageCloud Lake

Options for analytic databases and data warehouses (2023)
