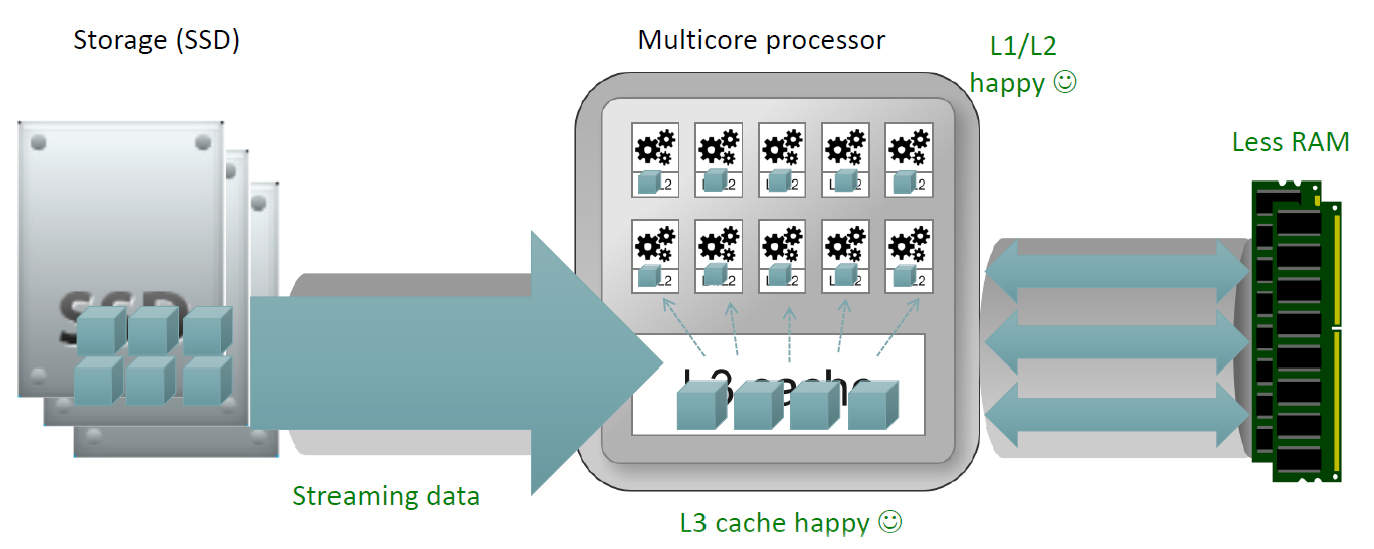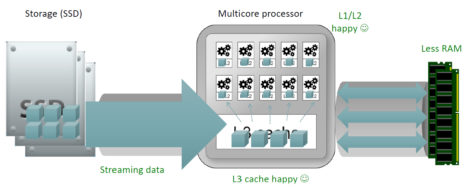
Figure 1 - The architecture of Yellowbrick Data
The fundamental principle behind Yellowbrick’s thinking is that traditional data warehousing architecture with spinning disks is simply old-fashioned. Its view is that even more modern, in-memory based systems with flash disks simply transfer bottlenecks to processing from disk to memory. In these architectures, incoming data goes to memory which, in turn, leverages, or tries to leverage, CPU cache. Yellowbrick argues that this is the wrong way around: that it is better for data to be directly processed by CPU cache (L1, L2 and L3: L3 in the first instance) with CPU cache and memory-based capabilities interacting, as illustrated in Figure 1.
The company also argues that the current trend towards separating compute from storage is an illusion. Certainly, there are environments where you do not have much in the way of seasonality – workloads are more or less consistent – where it does not bring any advantage. More specifically, Yellowbrick contends that, yes, it may be appropriate for some smaller environments and, yes, it may have advantages in cost terms when you can scale compute power up and down. However, its view is that the problem is that the interconnect is typically too slow and that the time needed to warm up caches means that performance is impaired. There is some truth in this argument and the desirability of separating compute from storage is not as clear cut as some vendors might have you believe. Indeed, even some of the suppliers that offer this approach do so only as an option.
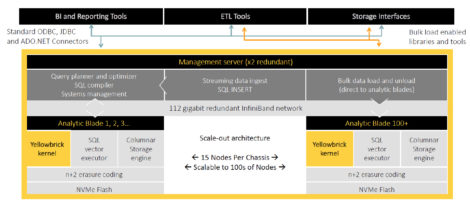
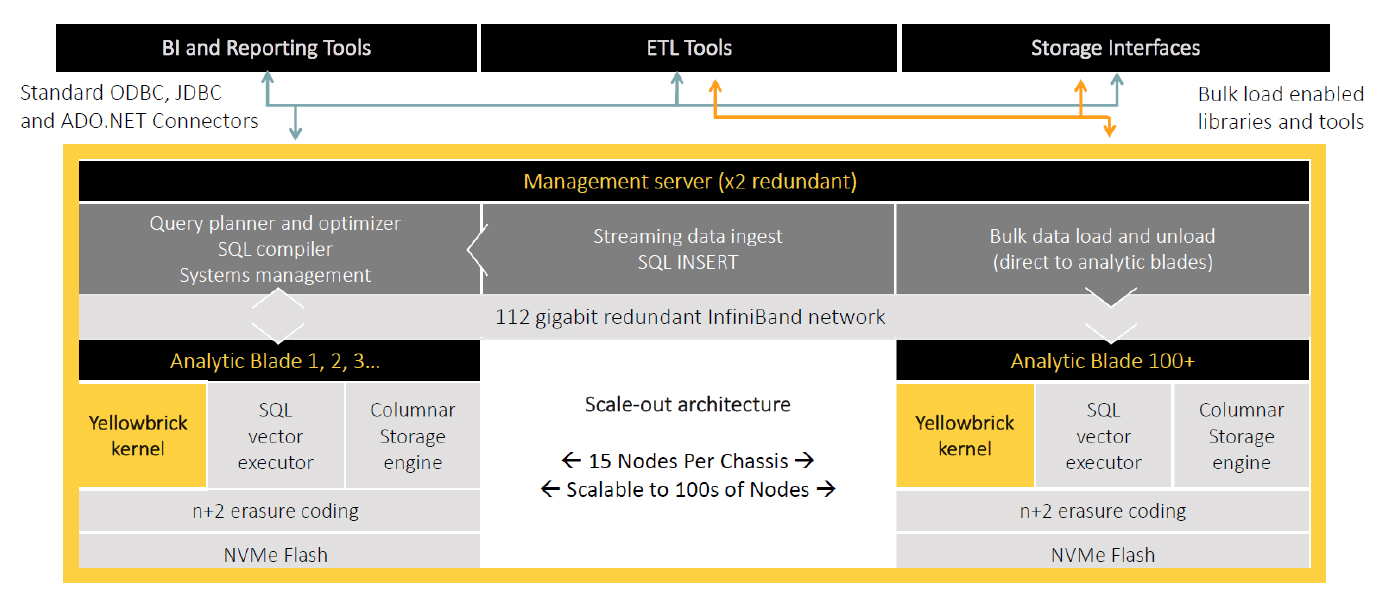
Figure 2 - Notable features of Yellowbrick Data
More generally, the broader architecture of Yellowbrick is illustrated in Figure 2 with notable features including parallel loaders, a fast row store as well as columnar storage, a cost-based optimiser, workload management, a system management console and a customised (vectorised) SQL processor. Note that in the latter case this replaces the standard PostgreSQL processor as Yellowbrick does not believe that that is fast enough. In the same context it is also worth commenting that as a product built on top of PostgreSQL you should be able to leverage the PostgreSQL extensions supporting geo-spatial and time series data, which will be important in Internet of Things environments. Not shown in this diagram is the fact that Yellowbrick offers asynchronous replication across Yellowbrick instances regardless of whether these are on-premises or in the cloud.