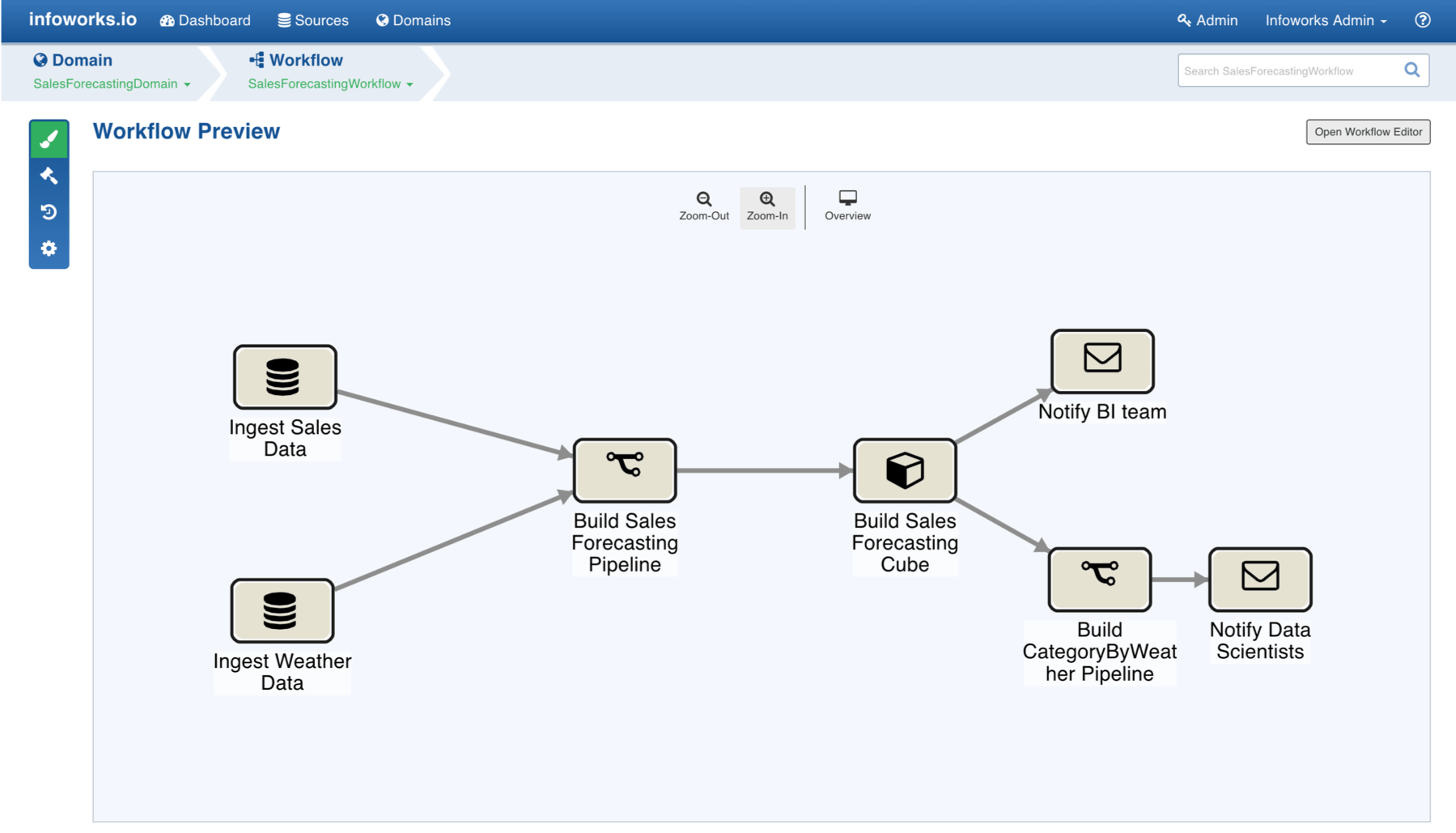
Figure 1 – Infoworks workflow
Figure 1 illustrates an Infoworks workflow and it is easiest to describe how the product works by reference to this diagram. In this example, analytics are required that relate product sales to weather. Sales data is extracted from a source database via a crawler that runs on that source, accessing the database catalogue and leveraging a native connector built by Infoworks. A number of these are available and the company plans to introduce an SDK so you can develop your own connectors. Weather data is ingested from the Internet. Static data is loaded in parallel and in batch mode, but rapidly changing data can be loaded incrementally (via a schedule that you define) using change data capture. High speed merge capabilities are provided.
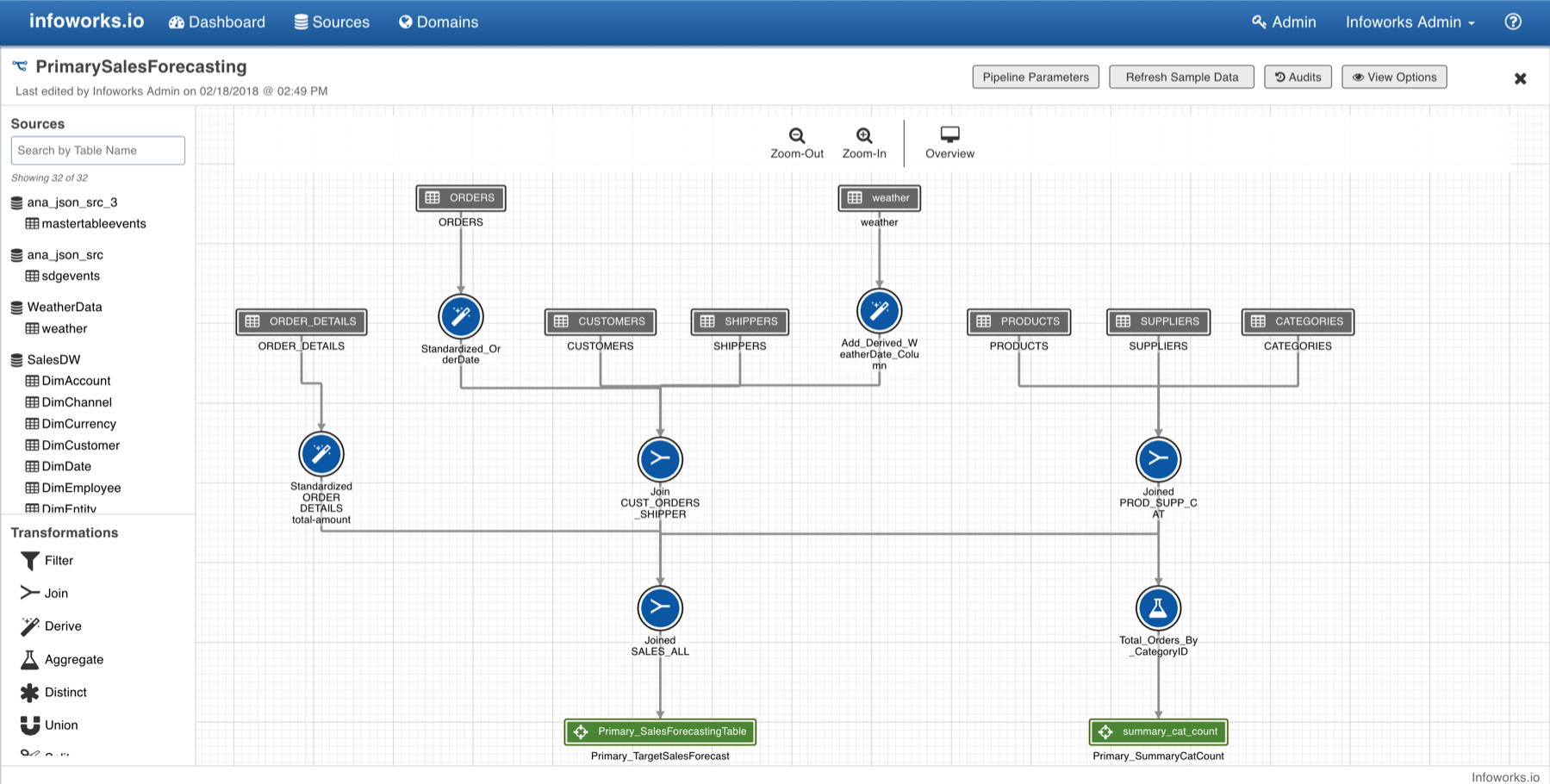
Having defined your source data and how you want to load that data, you select the Hive schema (in the case of a Hadoop environment) that you want this to be to be mapped to and define the location of the HDFS cluster. The software automatically normalises the data for you to match this schema. It also automatically parallelises the ingest process and handles the merge of change data onto the cluster (something that Hadoop does not do natively). You can then prepare the data and there is data profiling built into the product. Data blending and other transformations are defined by dragging and dropping widgets onto your canvas, creating what the company calls “pipelines”. An example of this is shown in Figure 2, where the grey boxes represent input data, the blue circles transformation widgets and the green boxes output data. If all you were doing was to migrate data from a warehouse into Hadoop, or if you were just creating a data lake, you might stop at this point.
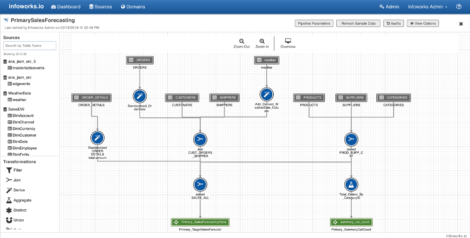
Figure 2 – Infoworks pipelines
To support business intelligence and analytics a further step is provided whereby you graphically create your fact and dimension tables, either for a star or snowflake schema. From this you can generate relevant OLAP cubes that can be visualised using your choice of front-end tools. ODBC and JDBC connectors are supported so that you can use Tableau, Qlik, MicroStrategy or any other appropriate tool. Alternatively, you may wish to create a predictive model rather than simply report on sales by weather. In this case you select an appropriate algorithm, again represented as a widget, and generate the appropriate data which, again, you can visualise in the tool of your choice. Infoworks supports the Spark ML library for these predictive models but you could also use others or add your own. Once development is completed, Infoworks has notification capabilities built into it so you can notify business analysts or data scientists when a new cube or model is available.
Finally, Infoworks provides automated facilities to push pipelines into test and then production with a mouse click. Orchestration and monitoring facilities are provided for the live environment. Fault tolerance is built-in and role-based security (by domain) is provided, along with integration options for products such as Apache Ranger.