
Data Governance
Last Updated:
Analyst Coverage: Daniel Howard and Philip Howard
Data governance has no authoritative definition, but in practice it is either the overarching process by which data assets are managed to ensure trustworthiness and accountability, or the highest level of said process, the one at which decisions are made and policy is created. This applies regardless of whether the data is in production, test or has been archived. The process as a whole can be thought of as having three ‘stages’: policy management, data stewardship, and data quality.
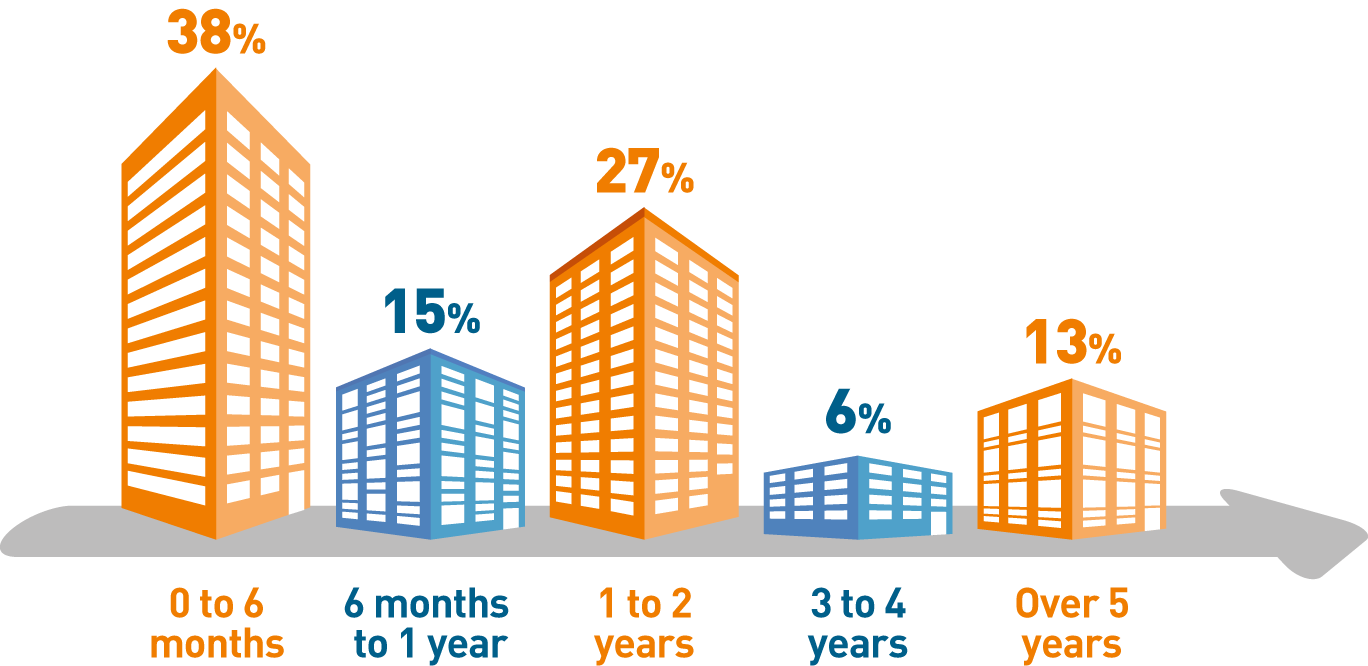
Figure 1 – Respondents to CIO Watercooler’s Data Governance Survey 2017 – How long has your organisation been implementing data governance?
Why is it important (hot)?
There are three reasons why data governance is hot. Firstly, it is more and more oriented towards the business and a top-down, business-led approach to managing and curating data. It is increasingly about improving productivity and driving business value. This is achieved through managing, enforcing and even automating business policy, to make policy creation and implementation faster, easier and more effective.
Secondly, it is hot because of increasing regulation, such as GDPR, the EU’s General Data Protection Regulation. New mandates have had a knock-on effect on data governance, and many vendors now provide pre-fabricated sets of policies that can be implemented and enforced immediately. Further, complying with regulations such as GDPR requires both the discovery of all relevant data and that you can ensure its accuracy.
Thirdly, just as GDPR requires high levels of data quality, so does the drive towards the “data-driven enterprise”. The intelligence upon which business decisions are based needs to be both reliable and trustworthy.
How does it work?
A complete data governance solution will consist of three fundamental capabilities: policy management, data stewardship, and data quality. Policy management encompasses both the formal creation of policy, the decision-making process that has led to your policy being what it is, and the management and, if needed, alteration of existing policy. Data stewardship is primarily the ability to monitor your data and ensure that it complies with the policies you have laid out. Often, this will involve moving from policy in the abstract to implementing concrete and enforceable business rules. Lastly, data quality is primarily composed of the implementation and enforcement of the rules created via data stewardship.
The principle idea is to take a top-down approach to governance. For example, suppose you have an idea for a new policy, possibly with respect to new product introductions or new customer onboarding. You can use your governance solution’s policy management capabilities to share this idea with other staff in your organisation, collaborating on the specifics and refining the policy, for example, via a workflow. Now a data steward can leverage your data stewardship capabilities to associate this policy with a selection of business rules, creating new rules if need be, and flag your data appropriately so that the correct data is associated with this new policy. All that’s left is enforcing data quality, as specified by your business rules.
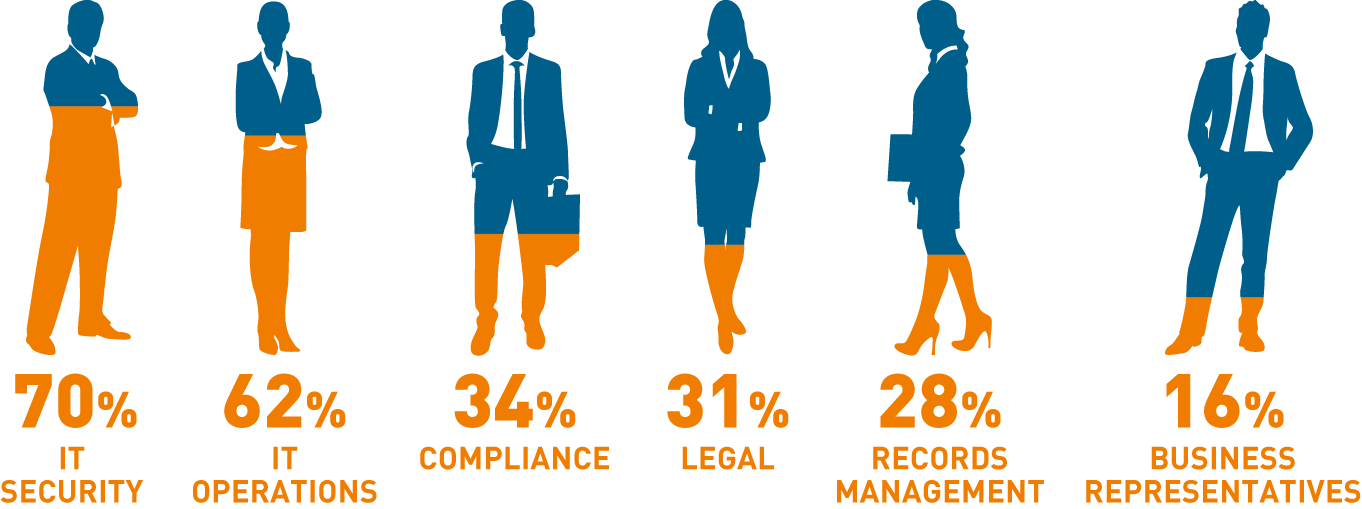
Figure 2 – Over three-quarters of organisations (78 percent) have a data governance team in place… organisations with data governance teams in place include a variety of stakeholders from across the entire business. Data Governance Inside the Enterprise, blancco, 2017
Policy-oriented data governance, driven by the business, is not just about data quality to support analytics and operation insight, and nor is it just about compliance and reporting. It is also about operational excellence. For example, ConAgra Foods has stated a “20% reduction in cycle times for new product introductions” thanks to business-value driven data governance. Similarly, Johnson Controls quotes a “50% reduction in project rework”, for the same reasons. More broadly, the CIO Watercooler’s Data Governance Survey 2017 found that the majority (54%) of their respondents cited “efficiencies in processes” as the key driver for implementing data governance.
On the other hand, the results of poor data governance can be dire. For example, in April 2017, British payday loan firm Wonga was stricken by a severe data breach that may have affected up to 270,000 current and former customers. The effect on their reputation (let alone their finances) has been palpable. To wit, in the two weeks following the breach, their YouGov “Buzz score” – which measures whether someone is more likely to have heard something positive or negative about them – plummeted from -13 to -24. Moreover, data governance may have helped to plug this leak. According to Blancco Technology Group, Richard Stiennon, the Chief Strategy Officer, former Gartner analyst and a data security expert: “a data governance program could have minimised the effect of the data breach.”
Quotes
“Almost three quarters of our survey respondents (72%) agree that data quality issues impact consumer trust and perception, with 64% reporting that inaccurate data is currently undermining their ability to provide an excellent customer experience.”
Consumer expectation versus business reality, Experian 2017
“Accessibility, security and governance have become the fastest growing areas of concern year-over-year, with governance growing most at 21%.”
Big Data Maturity Survey 2016
“While an overwhelming majority of executives highlight data governance as being important to Big Data business adoption, a notable percent (21.3%) cite a lack of data governance policies and practices as an impediment to adoption.”
Big Data Executive Survey 2017, NVP
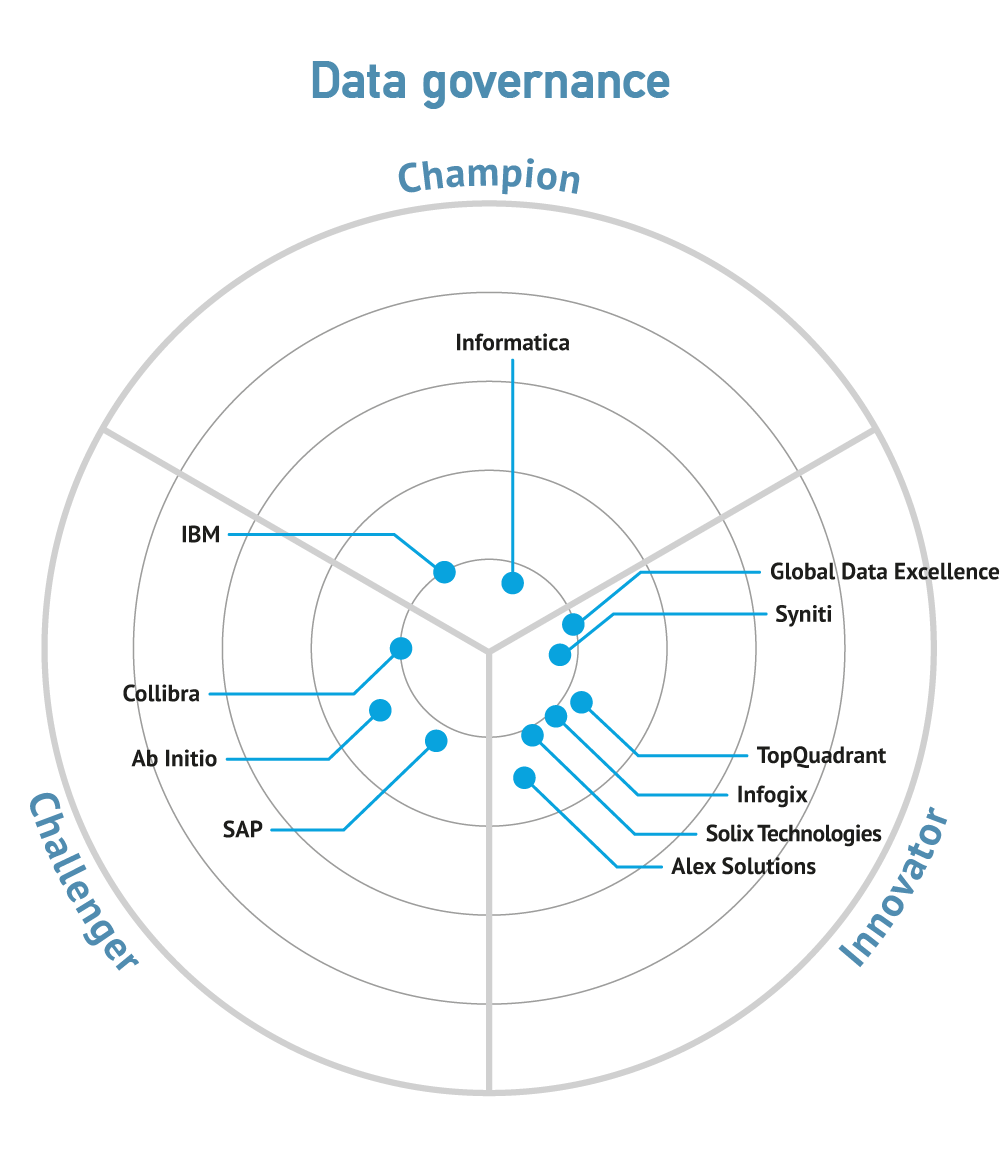
There are relatively few data governance vendors that have embraced policy management as a primary focus. These include IBM, Infogix, Informatica, Global Data Excellence, BackOffice Associates, Collibra, DATUM and TopQuadrant. Others worthy of consideration include Global IDs, SAP and ALEX Solutions.
While all of the vendors listed provide data stewardship capabilities, only IBM, Informatica and SAP provide free-standing data quality solutions, although Global Data Excellence has some built-in data quality capabilities. Other vendors with data quality products include (but are not limited to) Talend, Syncsort (Trillium), Oracle, Experian, Pitney Bowes, Atacama, Uniserv, Datactics, and iWay.
Master data management is a complementary technology provided by IBM, Informatica, SAP, Oracle, Semarchy, Reltio, Riversand, Orchestra Networks, Stibo and others. There are also a variety of specialised governance products (for example, security analytics and monitoring) that fit well with a general governance solution.
The Bottom Line
Every organisation creates policy. Data governance will help you create that policy quickly and enforce it effectively.
{kind=link}
Commentary
Solutions
These organisations are also known to offer solutions:
- BackOffice Associates
- Broadcom
- Celaton
- Changepoint
- Collibra
- Datactics
- Datum
- Diaku
- Embarcadero
- Global Data Excellence
- Ground Labs
- iWay
- Magnitude Software
- Rocket Software
- SAS
- Syniti
Research

Discovering Sensitive Data (2022)

Master Data Management (2022)

Global IDs Data Lineage

The ethics of sensitive data and Solix Technologies

Master Data Management (2021)

Federated Master Data Management (MDM)

Data Monetisation and YourDataConnect 2021
