
Data Masking
Last Updated:
Analyst Coverage: Philip Howard
Access controls are used, possibly in conjunction with encryption, to prevent users from seeing information that they are not authorised to view. However, frequently, applications have not had role-based security applied to them. Also, there are many environments where it is necessary both to hide the data and to use that data for processing purposes. The most common example is in development of new or updated applications or in retro-fitting security controls to existing environments. Developers may not be allowed to see detailed personal information but at the same time they may need that data, or its equivalent, in order to test the application they are developing. The technology, or technique, used to enable this functionality is known as data masking.
There are multiple ways to implement data masking, depending upon requirements. As an illustration: if you need to mask a postal code then you could simply randomise the data. However, if your application needs to be able to recognise that this is indeed a post code then you will need to ensure that the randomisation creates the right format or, indeed, that it generates a (theoretically) valid post code. In addition, where you are masking the same data in different places you may need to be able to ensure that the same result is produced in both cases and, going still further, you may need to be able to ensure referential integrity during the masking process. Thus multiple ways to mask the data are needed to suit different scenarios.
There are essentially three types of data you might want to mask. The first is data about individuals, which includes credit card numbers, social security numbers, health and medical information, address and postal details and so on. This is generally referred to as personally identifiable information (PII) or, in the case of healthcare, personal health information (PHI). The main reason for masking such data is to comply with data privacy regulations but also to avoid the sort of bad publicity and costs associated with data breaches caused by hacking and other cyber attacks. One complication is that different jurisdictions have different data privacy regulations. Not only does this mean that you may need to apply different approaches to masking in different countries but also there are cross-border considerations, as some countries have strict controls about securing data that is moved outside the country. This may mean two levels of masking: one for local use and one for overseas use. This may have particular significance where software development is geographically dispersed (for example, a joint development between an in-house team and an outsourcer).
While you must obfuscate private data in order to comply with regulatory requirements there are two other classes of data that you may choose to mask. The most obvious of these is financial data. You would not want, for example, your financial results to be leaked to the market (or to individuals) prior to your official announcement of those figures. Similarly, you would not be happy for detailed financial information to be made available to competitors. Secondly, there is intellectual property. If you are Coca Cola, for example, you would not want the formula for Coke to become public knowledge or have it leaked to your competition. The need to mask data is also commonly a requirement when archiving data if the archival system has different security controls from the source system, which is often the case.
While the need to mask these various types of data is more or less obvious there is one further type of masking that may be required. Suppose that you have a fully masked database on a laptop and this gets stolen or left behind in a taxi. Then it is still possible to determine trends within the data, which may have commercial value. Special techniques are required to hide this sort of information.
In some cases, especially in healthcare, it is important to be able to use collected data for research purposes. In such instances there needs to be a balancing act between privacy and menaningful statistics and special features of data masking products need to be available to attain this balance.
Data masking is going to be of primary concern for the chief security officer and the CSO should be able to mandate the use of appropriate data masking techniques for all relevant projects. In addition, data governance policies may require that certain data (such as financial data) is masked even where that is not required by law. Thus data masking will be of concern to the data governance council, data stewards and all others that have responsibility for data. Further, those responsible for developing, testing or migrating applications should be aware of the need for data masking when relevant data is being used. This especially applies when development is outsourced and companies will need to practice due diligence to ensure that partners are masking the data in an appropriate fashion.
Note that for compliance purposes it will be important that you are able to audit what you have masked: to prove that you have masked what you said you were going to mask.
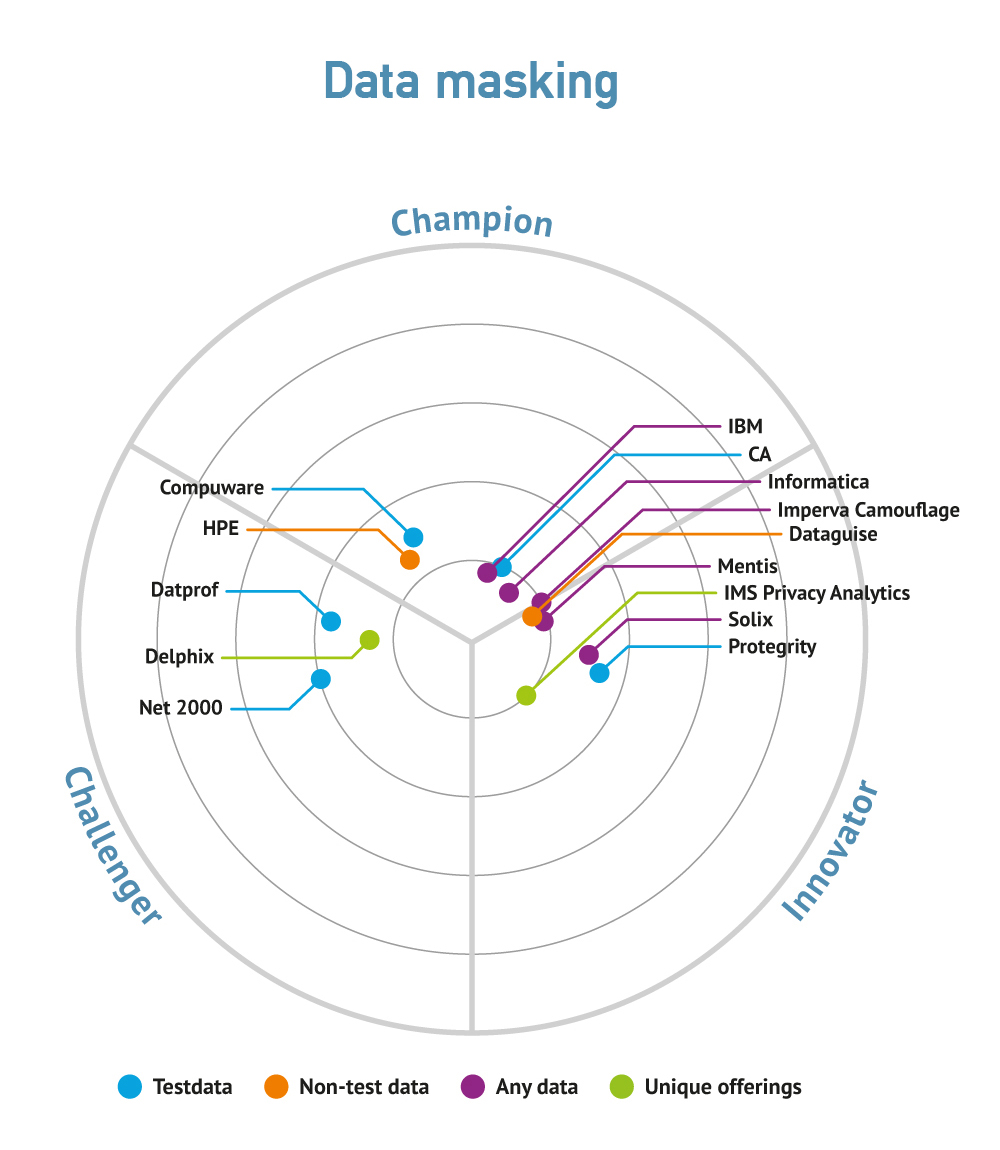
There are a large number of companies that provide data masking technology. However, data masking is not a standalone function. Before you even begin to mask you will need to be able to discover where sensitive data resides within your environment and for this you will need data (profiling and) discovery capabilities. There are, of course, various independent tools that can do this and using these in conjunction with data masking will be a perfectly acceptable approach. However, the trend is likely to be towards vendors providing integrated capabilities that do both of these things.
It is also worth noting the synergies between data masking and test data management and, given that service virtualisation is also moving closer to test data management we can begin to see the emergence of suites of tools that have a data focus for application development and testing, to complement traditional tools that have a more application focus. In the case of test data management, if that product supports synthetic test data generation then you do not need data masking.
One significant growth area is in dynamic masking. Static data masking is used in test and development environments which we have largely been describing, while dynamic data masking is used in conjunction with operational data in real-time, although we are also aware of companies using it in development environments. As understood by most of the market this involves dynamically intercepting requests to the database (SQL in the case of relevant sources but whatever is relevant in the case of, say, Hadoop) and masking any sensitive data. This is complementary to, or a replacement of, the sort of role-based access controls that are in use in many environments to prevent, for example, HR employees seeing the salary levels of executives.
Data masking remains an emerging market. When Bloor Research conducted its most recent survey of the market for Data migration in 2011 it found that only a minority of projects that required data masking were actually using tools for this purpose. As the complexities of data masking become more familiar to both organisations and developers alike it is likely that this market will grow significantly.
In the short term this will probably mean that more suppliers appear within the market but in the medium to long term we are likely to see consolidation. Currently, there are lots of products from lots of companies, many with only limited capability that purely address data masking or with products that are limited to only a relatively few sources (for example, being SQL Server specific). The more advanced products tend to come from companies that also offer test data management and these are the ones most likely to survive.
More specifically, dynamic data masking is gaining more interest, with Informatica joining IBM in making a major push into this area. Privacy Analytics, as its name implies, specialises in masking in such a way that you can still do statistical analyses on the data. We are aware that IBM is looking at this possibility. Also, there is a growth in support for synthetic test data generation with GenRocket, Informatica and Rever all joining Grid-Tools in this space. IBM is also interested in this approach.
Commentary
Solutions

These organisations are also known to offer solutions:
- BMC Compuware
- GenRocket
- Global IDs
- Ground Labs
- HPE
- Imperva Camouflage
- Net 2000
- Orbium Software
- OriginLab
- PKWARE
- Privacy Analytics
- Protegrity
- Rever
Research

Collibra Data Quality and Observability

Ataccama and Data Quality

DATPROF (2024)

Broadcom Test Data Manager (2024)

AI and Generative AI within an Enterprise Information Architecture - Solix and The Operating System for the Enterprise

IRI information privacy compliance

Data Preparation Challenges in Healthcare and Voracity from IRI
