
IRI Data Masking
Published:
Content Copyright © 2023 Bloor. All Rights Reserved.
Also posted on: Bloor blogs

When it comes to protecting your data, there two processes that could be considered absolutely fundamental: finding out which of your data is sensitive and where it can be located, and then actually protecting that data*. The former is sensitive data discovery, which we have already discussed in previous blogs in this series. The latter can encompass a few different things, such as encryption, redaction, or the topic of this blog, data masking. Note that some vendors, including IRI, position encryption and/or redaction as part of data masking, so we will use the latter as a catch-all term – but be aware that sometimes there is a distinction.
Data masking, then, is the replacement of data (most often sensitive data) with desensitised, usually randomised data. The sophistication of this process varies dramatically. In a very basic form, you might just replace a piece of data with a string of X characters. This comes pretty close to just being redaction. Less rudimentary techniques might involve picking a random selection from a list (for instance, masking a name by randomly picking from a list of common names) or randomly generating a numerical entry in the same format (a credit card number, say). Really advanced solutions might use synthetic data generation to generate entire “fake” data sets that contain no sensitive information but that replicate the high-level statistical makeup of the original data set. The idea in general is to replace real, sensitive data with fake data that looks real, or at least close enough for development and testing purposes.
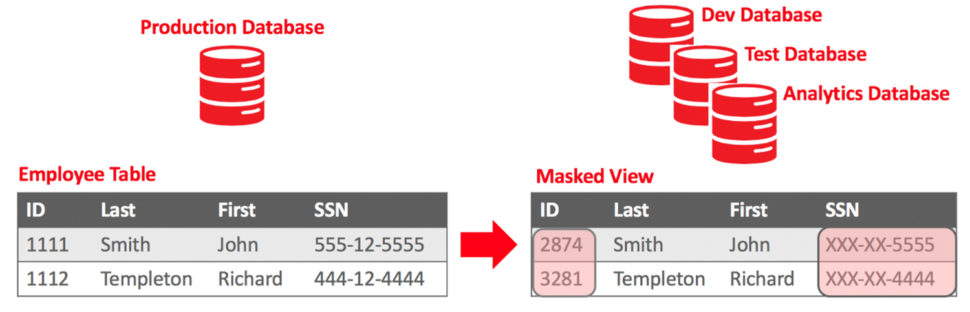
Fig 1 – Masking RDBMS data
Note that the methods discussed above largely concern irreversible, static data masking. Reversible masking is less secure, for obvious reasons, but allows you to revert to the original data if needed, while dynamic masking refrains from replacing the data at source in favour of altering the view of that data for any users who aren’t privileged enough to see what it really is. In either case, this is a way of protecting your sensitive data when replacing it in its entirety would be impractical.
There are a few obvious ways to judge data masking solutions. The first and second are the sophistication and variety of the masking techniques available: we have already described several. An additional facet of this that we haven’t mentioned so far is the ability to maintain referential integrity during the masking process, and thus mask consistently across an entire system. This leads into the third point, which is the variety of data sources that can be masked on. Although being able to mask on structured data sources such as RDBMSs is largely table stakes, masking semi-structure/unstructured data, whether on NoSQL databases or individual documents, spreadsheets, images and the like is very much not. Moreover, being able to mask consistently – and while maintaining referential integrity – across all of these sources at once, and thus over your entire enterprise, can be very important.
The latter is an area in which IRI’s data masking capabilities perform very well. Voracity provides a cornucopia of supported data sources for masking as well as for its other functionality, including both structured and unstructured data, and offers specialised products designed for managing structured data (IRI FieldShield), unstructured data (DarkShield) and Excel data (CellShield), which very much includes masking. Notably, DarkShield will allow you to not just detect and remove sensitive data from images and documents, but also to replace that data with new, masked data. This sort of functionality is usually reserved for relational data. It’s also worth noting that DarkShield has become something of a jack-of-all-trades product as far as masking is concerned, and it can handle structured data very capably as well.
IRI provides a variety of masking functions that can be leveraged inside masking jobs, that can themselves be created, executed and managed via IRI Workbench. In fact, in this instance Workbench is positioned as something of a centralised view into all of your masking functionality, across your entire environment. Referential integrity is always maintained within these functions via the generation of consistent ciphertext, and the complete list of functions includes character-level scrambling, blurring (which introduce random noise within a specified range to numeric values), hashing, encoding, (format-preserving) encryption, tokenisation, redaction, filtering, byte shifting, and more.
You can also build your own field-level masking functions externally and integrate them via an API. All masking functions can be applied conditionally via masking rules (associating specific masking functions to specific classes of data, for example) and you can combine two or more masking functions together and apply them simultaneously, effectively nesting one within the other and saving you from passing over all the applicable data multiple times. Finally, Voracity also provides synthetic (test) data generation, which can be used to generate replacement data alongside the platform’s more dedicated masking functionality. We will discuss this capability in more detail in the next blog in this series.
*We should clarify that a complete and effective data privacy solution will contain far more than just these two technologies, but while we can at least imagine such a solution without, say, policy management, we cannot say the same for either of these**. This is why we see them as fundamental, in the literal sense of the word.
**And to avoid any unhealthy implications, we should point out that IRI is not one such solution, and does in fact offer policy management (although we don’t discuss it here) in addition to data discovery, masking, and so on.