
The IRI Platform
Published:
Content Copyright © 2023 Bloor. All Rights Reserved.
Also posted on: Bloor blogs

Over the course of this blog series, we’ve described a number of data management capabilities, as well as why those capabilities are important and worth caring about. We’ve covered testing, both in terms of test design automation and test data management, data governance and data masking, data migration and modernisation, and data quality and improvement. More to the point, we’ve discussed IRI’s data management offerings – and more often than not, IRI Voracity’s specific functionality – in the context of those capabilities. But this sort of piecemeal examination does not really tell the full story for IRI Voracity, or indeed IRI in general.
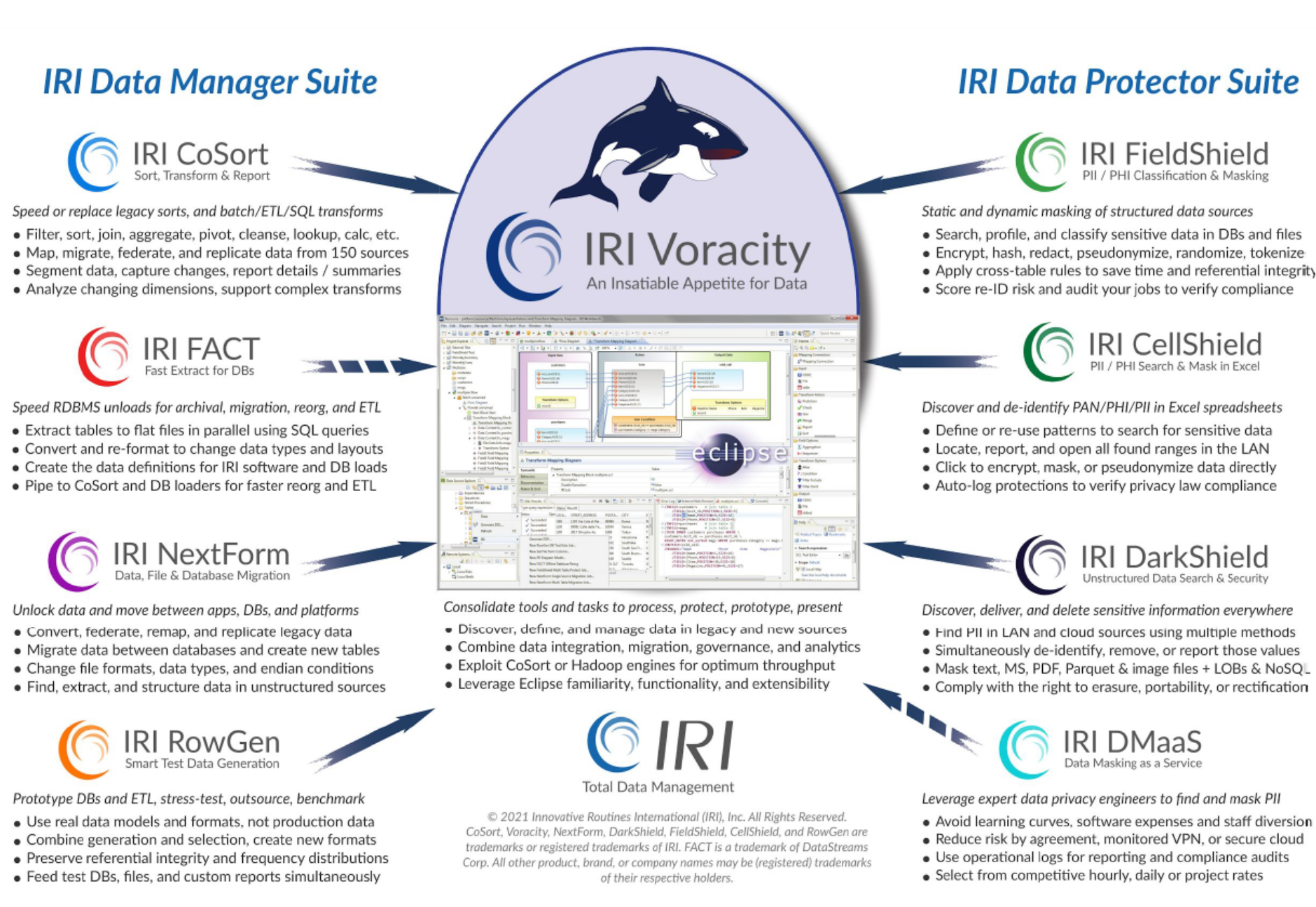
The IRI Platform diagram (click to expand)
As a data management platform, one of Voracity’s keys strengths is its ability to not just deliver all of the functionality we’ve described above, but to deliver it within a unified, centralised, integrated platform supported by a common engine. Platform solutions in general are measured by how well they achieve this – after all, without this sort of cohesion they are just a collection of products – and we are pleased to say that IRI does not disappoint. Voracity delivers all of its functionality at speed and at volume, enterprise-wide and at enterprise-scale, with built-in logging and reporting at every step of the way. It also offers far more functionality than we’ve been able to cover in this series, both in terms of depth and breadth: we’ve really only been able to scratch the surface.
That said, it is clear that data integration and transformation lie at the heart of the platform, largely owing to IRI CoSort and its 40-year lineage. What’s more, technologies of this type might as well be essential for building data lakes and data warehouses, performing analytics, moving data out of legacy tools or into the cloud, and accomplishing the vast majority of whatever other data manipulation initiatives you can think of. Thence IRI is well-positioned to address all of these various use cases while operating at big data scale and speed.
In addition, functions like cleansing, masking and wrangling can be performed in combination, achieving multiple positive outcomes with only one pass over the data. Moreover, we have repeatedly mentioned IRI Workbench throughout this blog series, and for good reason: it acts as something of a central hub, and a common graphical user interface, for actioning almost any particular task within Voracity. Although perhaps it is not the flashiest tool, or the easiest tool to use from the perspective of a business user – after all, it is still ultimately built on Eclipse – it is extremely well suited for its intended purpose of providing developers with a single point of entry to a wide range of IRI functionality. When seen from this perspective, we would consider it a significant and notable win for developer ease of use and productivity.
The long and the short of it is that Voracity is well-positioned as a holistic platform for data management. It has its weaknesses, much like any product, but IRI is working to address them, and when taken as a whole its strengths as a platform are considerable.