
IRI Voracity and Test Design Automation
Published:
Content Copyright © 2022 Bloor. All Rights Reserved.
Also posted on: Bloor blogs

This is the first in a series of blog posts which will highlight the various data management capabilities provided by IRI Voracity across a range of contexts and use cases. At the highest level, Voracity is a data management platform that offers a wide range of data-oriented functionality, and that is accessed via IRI Workbench, a wizard-driven user interface backed by graphical modelling. To kick off this series, we’re starting with a topic that is near and dear to our hearts: test design automation.
For those of you who don’t know, test design automation is, philosophically, an advancement on test automation that emphasises the use of automation holistically and throughout the testing process, not just as part of test execution. The advantages therein are fairly obvious, largely consisting of making your tests far easier and faster to design, build and execute. In turn this allows you to test more thoroughly, maximise test coverage, and so on.
The trouble is that you really need every part of your testing processes to be automated to derive these sorts of benefits: execution, requirements, test design, test data, you name it. There’s little point in having a slick testing process that automates everything from test design to test execution if you have to generate and feed in your test data manually every time you run it.
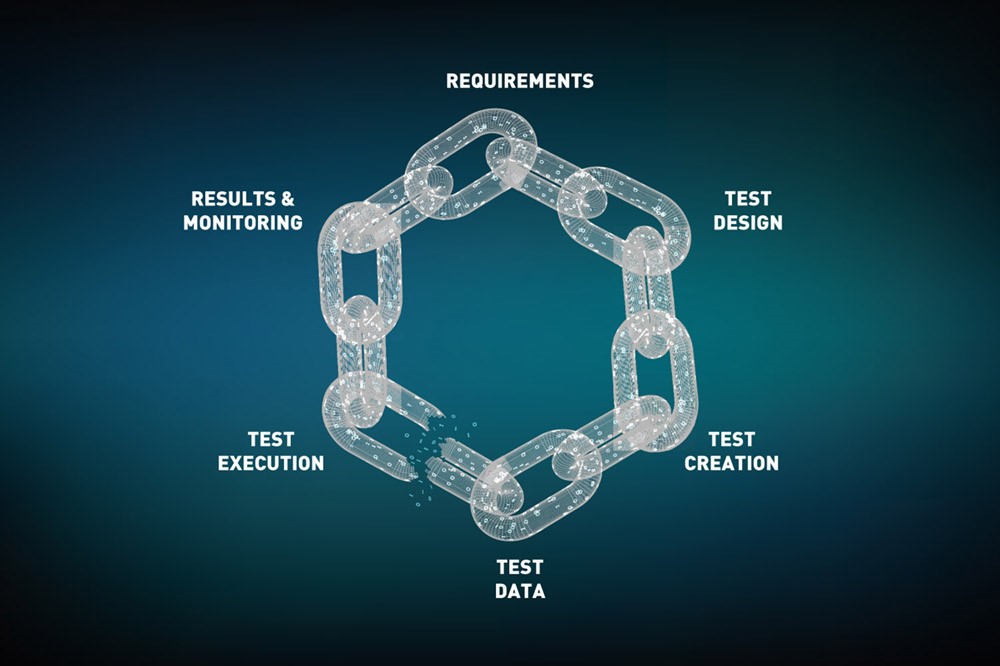
Fig 01 – A weak link in your testing lifecycle will often lead to bottlenecks (click image to expand)
Indeed, any weak link in the chain risks creating a bottleneck, and if that happens your entire testing process is going to come grinding to a halt with worrying regularity. “A chain is only as strong as its weakest link”, as the saying goes: lightning-fast, automated test design and execution means almost nothing if your test data delivery processes are slow as molasses.
Indeed, test data is infamous for causing these sorts of bottlenecks. It has historically been plagued by long delivery windows, particularly where sensitive data is concerned. And as you may have already guessed, this is the major area in which relevant tooling in Voracity can benefit test design automation. The robust, automated test data management and delivery capabilities it provides allow you to reap the greatest benefits from your test design automation by, at the very least, substantially ameliorating the test data bottleneck, if not removing it entirely.
Voracity provides all the data discovery, masking and subsetting capabilities that you would usually expect from a test data management solution. It also provides synthetic data generation, notably including the creation of representative data sets via analysis of your real data. By themselves, these capabilities are enough to make the creation and delivery of test data sets significantly speedier.
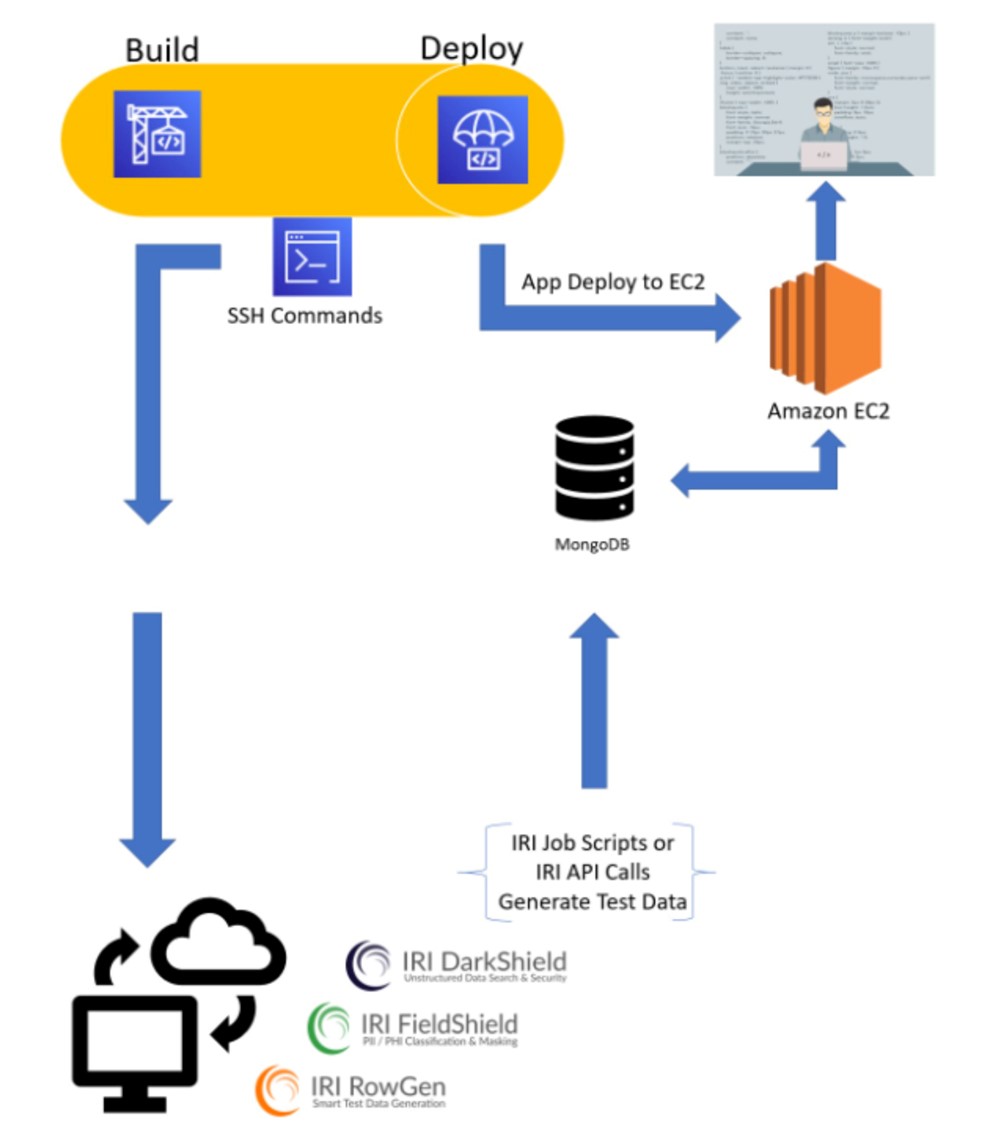
Fig 02 – Sample IRI architecture in AWS CI/CD Pipeline (click image to expand)
Moreover, these functions, including masking, subsetting and synthetic data generation, can be invoked directly from within your CI/CD platform processes, either on-premises or in the cloud. This means they can integrate with GitLab, Amazon CodePipeline, Azure DevOps, and Jenkins, all of which speak to real, ongoing examples of the product in use, and which in turn work as illustrative examples of how to use Voracity to automate the production and consumption of test data through these pipelines.
In addition, IRI has partnered with Windocks, a specialist database virtualisation company. This Voracity-Windocks combination delivers your test data in on-demand, self-service, containerised, and virtualised repositories.

Fig 03 – How IRI and Windocks fit together (click image to expand)
Essentially, the tools work simultaneously and together to create sanitised clones of your production data that can be delivered via self-service and then accessed and leveraged extremely quickly. In the context of test design automation, support for RESTful API calls allows you to slot this solution directly into your test pipelines, and hence benefit from similar speeds as well as automated delivery.
In short, if you want to automate your testing in general you will need to automate your test data management operations in particular, and IRI does the job well, particularly when its test data generation processes are integrated into fit-for-purpose test data delivery and provisioning solutions.