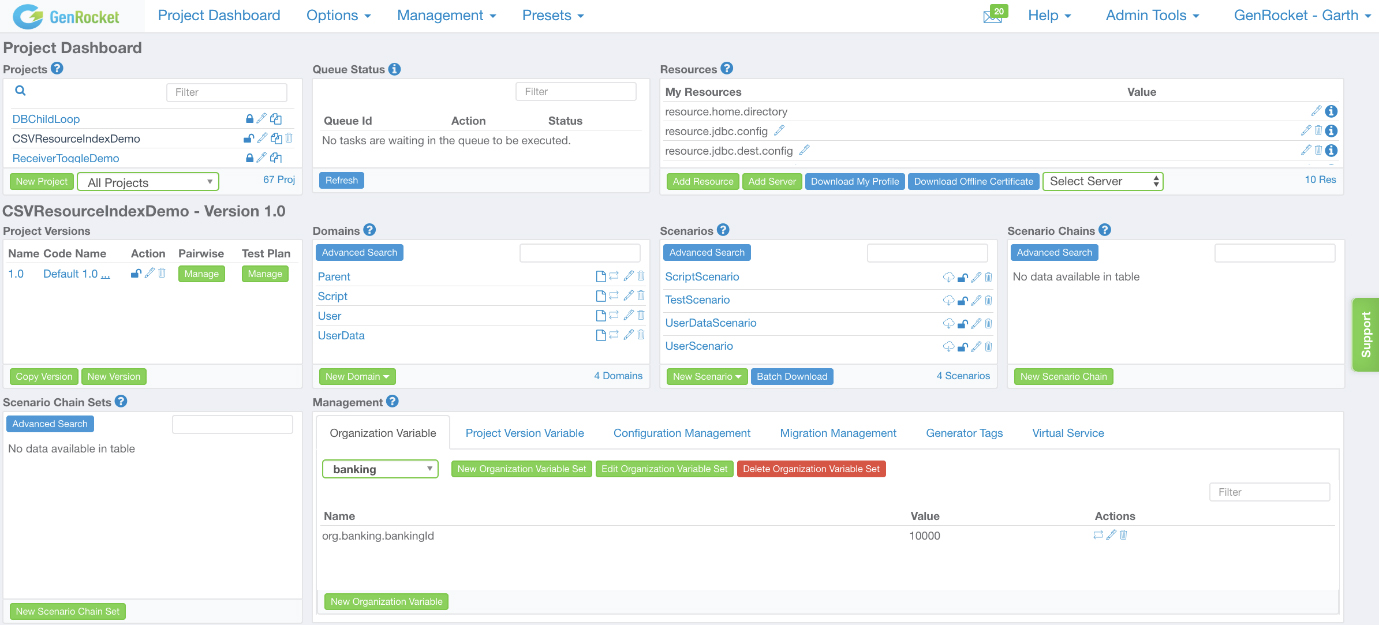
Fig 01 - GenRocket Project Dashboard
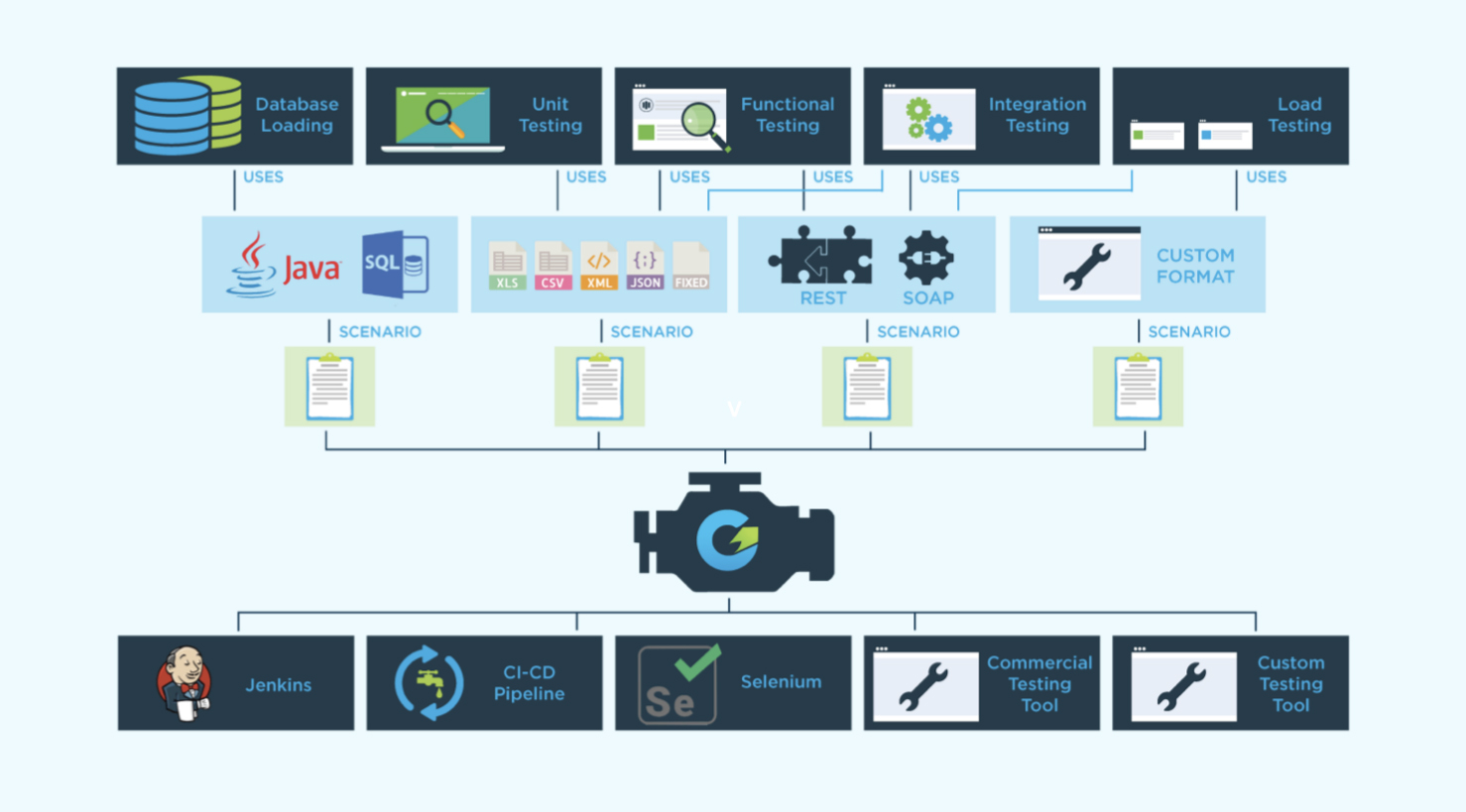
Synthetic data in GenRocket is generated using a model that consists of “domains”, “attributes”, “generators”, “receivers” and “scenarios”. Domains contain attributes, which are roughly equivalent to tables and columns respectively, and attributes are in turn equipped with one or more generators: methods for generating your synthetic data.
More than 650 generators are provided out of the box, many of which are customisable via built-in parameters. Notably, GenRocket provides several generators specifically to support machine learning via the creation of training data. It also has the ability to blend production data with synthetic data, as well as to generate synthetic data feeds. Generators can be linked together on an ad hoc basis, always create internally consistent data sets, and can even be assigned to your attributes automatically.
Each of your domains also has access to a variety of receivers, which determine the output format of your test data. Receivers exist for upwards of 70 different output formats, including such favourites as CSV, JSON, SQL, REST, SOAP and XML, and you can generate test data in several different formats simultaneously by attaching multiple receivers to a given domain.
Meanwhile, scenarios are sets of (configurable) instructions for generating your test data, created by combining domains, attributes, generators and receivers into a single specification. You can include multiple domains manually, or specify relationships that will allow GenRocket to bring in families of domains automatically. This guarantees referential integrity between those domains. You can also leverage rules-based validation to control the data (and thus the overarching structure of the data set) generated by your scenarios.
Scenarios can be grouped together into user stories, which can in turn be grouped into epics (a la Agile), all of which can be used (and reused) to repeatedly create test data via self-service, in real time, and on an essentially ad hoc basis. They can be executed centrally, facilitated by the GenRocket Multi User Server (GMUS) that allows large volumes of users to generate synthetic data simultaneously, but are also highly portable, and can be executed more or less anywhere (including on your local machine) via APIs or just by running the scenario file. Scenarios can even be modified in real time if necessary (perhaps as part of a dynamic testing workflow).
GenRocket also provides an XTS (Extract Table Schema) feature that will scan your database schema and automatically build out a test data model, including domains, attributes, generators and scenarios. Relationships between domains are established via a wizard, and you can proceed to either use the generated model as-is or customise it as you require. Similarly, GenRocket can automatically generate synthetic data for documents by leveraging a relevant XSD file.