
Curiosity Software
Last Updated:
Analyst Coverage: Daniel Howard
Curiosity Software Ireland is a software company founded in 2017 and based in Dublin. In principle its product areas centre around test automation, particularly what it describes as “test data automation”, but in practice, Curiosity Software’s offering extends beyond testing and into application assurance in general. Training and other culture-oriented assistance is available, and the company’s partners include Digital-Assured, Ostia, Micro Focus, Eggplant, Windocks, and Parasoft.
The company offers a variety of products designed to enhance, accelerate, and automate the testing process, including Test Modeller and Test Data Automation, solutions for test design automation and test data management respectively. It has also developed an open testing platform that acts as a collaboration hub for testing.
Robust synthetic data generation is included as part of Test Data Automation, while database virtualisation is offered via tight integration with Windocks. Data analysis capabilities are available in order to generate test data that accurately represents your real data, and the resulting traceability and relationship information can be stored and represented as a graph network using Neo4j.
Notably, although these capabilities are primarily concerned with testing and test data, in many cases they can also be applied to application development as a whole. Indeed, it would not be unreasonable to think of test automation as just one form of application development that Curiosity Software can address. We hope to see the company fully capitalise on this in the future.
Curiosity Software Ireland Test Modeller
Last Updated: 5th February 2020
bbTest Modeller is a test design automation product based on VIP, the Visual Integration Processor, a rapid application assembly framework developed by CSI. It provides functional, UI, performance, API and mobile testing via a model-based testing framework; advanced test data management capabilities, including synthetic data generation, allocation, subsetting, masking and cloning; and direct integration with a number of other testing products and vendors, including Eggplant, Tricentis, API Fortress and Parasoft. The product is entirely browser based, but can be deployed either in-cloud or on-premises.
Customer Quotes
“Gone are the days where you had to allot time for designing test cases. With modeller as soon as you create process model it automatically generates test cases using advanced coverage techniques.”
Information Technology & Services company
“Automated testing within reach and without writing the same tests scripts. VIP Test Modeller does enable an organization to seriously make a big left shift in their continuous development strategies.”
Transportation/Trucking/Railroad company
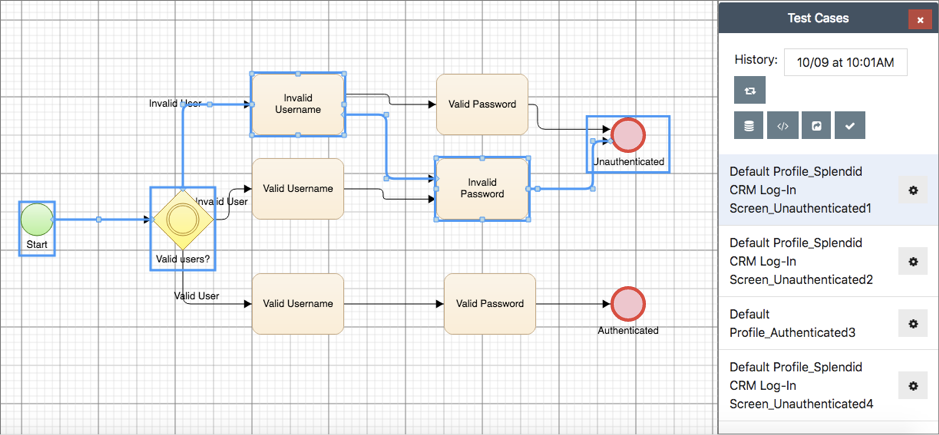
Fig 01 - A system model in Test Modeller
Test Modeller allows you to create a BPMN model for your system under test, as shown in Figure 1, which can then be leveraged to automatically generate testing assets. This model can be created manually using the built-in model editor, imported (for example, from a BPMN or Visio file), or built automatically using either existing testing assets, such as Gherkin feature files, or process mining via either Fluxicon or Dynatrace. Test Modeller also enables you to create user journeys by recording your interactions with your system. These are managed and analysed centrally and can also be used to automatically build your model. Furthermore, the tool can accelerate and guide model creation using its Fast Models feature, which automatically detects typical boundary values and valid and invalid test paths associated with an object under test.
Models can contain data variables, which will be found, parameterised, and populated with appropriate static data if your model was imported or built automatically. If not, you can add them manually. You can also opt to replace the static data in your model with dynamic synthetic data that will be generated automatically during test creation. Over 500 synthetic data functions are built-in, and you can create your own if necessary. Models can also be nested inside each other, enabling subflows. Importing models in this way is simple, and once a model is nested inside another, it is treated as if it were a part of that model. This makes managing nested models quite easy while creating a significant amount of reusability.
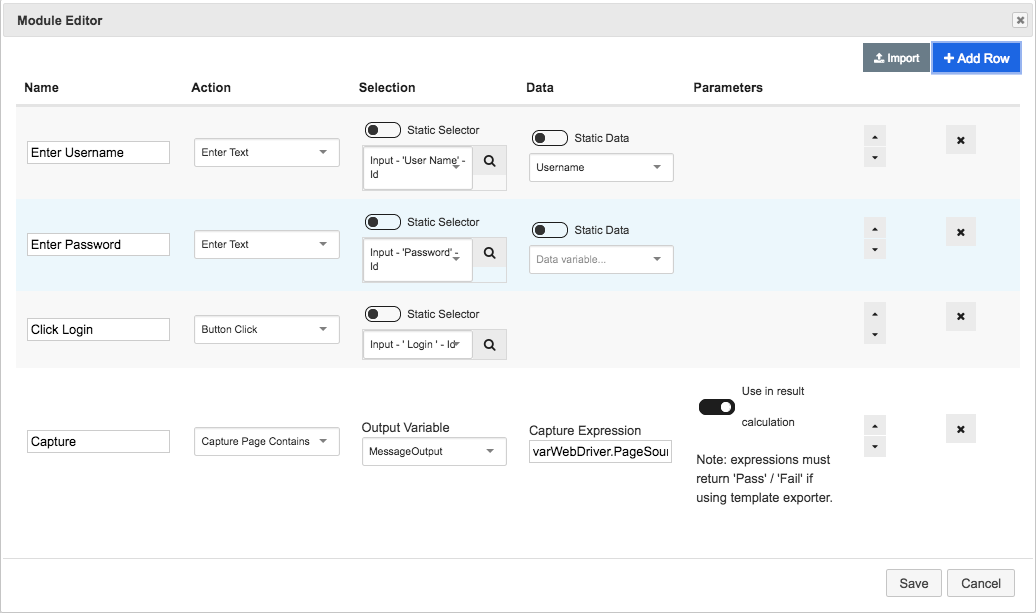
Fig 02 - The automation builder in Test Modeller
Models also contain an automation module for enabling automated execution. This is created automatically when a model is built, and otherwise can be created from scratch using the product’s automation builder (see Figure 2). This allows you to select which action to take, as well as which element to apply that action to, for each step in your testing process. Actions for Selenium, Appium, Parasoft, and a number of other tools are provided out of the box. You can also create your own, either manually or by using a code scanner (which are provided for Java, Python, C# and JavaScript) to automatically import any functions used by your existing test automation framework. Note that this will only work if your existing framework uses a Page Object Model architecture.
Once your model is complete, Test Modeller will automatically generate the minimal set of test cases for achieving 100% test coverage, as well as a corresponding set of executable test scripts. In addition, every part of your model can be tagged, and you can create coverage profiles for each tag in your model, enabling you to test different parts of your system with different levels of coverage. Test scripts can be executed within Test Modeller or exported into other products. Automated change management is also provided, and the framework can even “self heal” during test execution, allowing it to detect when something has changed, adapt, and keep your test(s) running. This enables highly resilient automation, particularly in regard to frequently changing UI objects.
Finally, for performance testing, Test Modeller integrates with Micro Focus LoadRunner, Apache JMeter, and Taurus. What’s more, it can implement performance testing actions from these frameworks as part of your existing model. Mobile and API testing work in much the same way, including integration with Appium, REST Assured, and the entire Parasoft stack.
Test Modeller’s most significant strength as a model-based test design automation platform is that is easy – and therefore quick – to use and to implement. For starters, it uses BPMN, which as a standard format will likely be familiar to your users, particularly nontechnical users such as business analysts. Creating your model is relatively easy: automatically creating it from existing test assets is, of course, the easiest method if those assets are available, but if not then recording user journeys and objects and building it from them is not difficult, and notably does not require any coding. Nested flows are handled elegantly, and the ability to overlay performance, API, and other types of testing on top of your model makes it much easier to implement those forms of testing alongside your functional tests. Several of these advantages should also help to enable collaboration. Consider, for example, that user journeys can be recorded by anyone, not just testers or developers, without requiring any expertise to do so. This means that, in principle, anyone in your organisation can contribute to your testing efforts simply by recording their usual interactions with your system.
What’s more, Test Modeller is highly effective at coexisting with an existing test automation framework. Being able to scan your code for existing functions and import them into your model is a particularly significant feature in this regard. Combined with the ability to export your test scripts back into your original test automation framework, or even into Git, it becomes easy to leverage the product to generate test cases and scripts automatically – thus saving a significant amount of time and effort – without otherwise altering your testing process. In addition, being built on VIP is a significant advantage, allowing Test Modeller to integrate with a long and highly extensible list of third-party products.
The Bottom Line
Test Modeller is an easy to use model-based testing framework that integrates extensively within the testing space. It is certainly worthy of your consideration.

Curiosity Software Test Data Automation
Last Updated: 4th March 2024
Mutable Award: Gold 2024
Curiosity Software Enterprise Test Data (ETD) is a solution for test data management and automation. This means that it helps you to both create viable test data sets and embed (and thus automate) the creation and delivery of those sets into your testing processes. That said, Curiosity takes the approach that the point of testing, and therefore test data, is to enable you to build high quality applications. Accordingly, although ETD is principally concerned with the creation and delivery of test data, it does so with a holistic view of application quality. This manifests in a significant amount of functionality that is perhaps slightly tangential, but ultimately very complementary, to the core issue of generating test data.
For example, the product is highly concerned with understanding your existing data so that it can generate test data that accurately represents said data and meets your testing needs. As such, it includes various data analysis capabilities. This includes coverage and risk analysis, sensitive data discovery, and relationship detection, among other things. In addition, the resulting traceability and relationship information can be stored and represented as a graph network built using Neo4j. On the other hand, the product also devotes considerable resources to making sure that the test data it creates is available in the right place and at the right time. This means that it provides test data in a continuous, on-demand fashion that can be delivered to any number of consumers in parallel. At the same time, test data is kept up-to-date, and test data sets are kept as covering as necessary while minimising their overall size. On top of everything else, the product’s test data processes are highly automated to ensure good performance and avoid testing bottlenecks. Moreover, all of this is delivered as part of a single, integrated platform, offering all of the usual advantages that provides.
By itself, ETD provides a range of test data utilities, not least those mentioned above. Its repertoire for creating test data includes subsetting and masking as well as synthetic data generation. When used alongside its sister product, Curiosity’s Modeller, ETD can overlay onto a visual model of the system under test and generate test data at the same time as Curiosity’s Modeller generates your test scripts. ETD can also connect with a variety of environments and third-party products, and a partnership with Windocks (as well as tight integration with its solution) provides access to containerisation and database virtualisation.
Customer Quotes
“We found the software extremely flexible in allowing us to set up various techniques to automate our data generation. In fact we couldn’t find a use case that we couldn’t manage to cover. What most impressed us was the ability to access difficult mainframe data sources such as VSAM, IMS and DB2 and we were even able to generate data into a CICS program and an MQ queue. We haven’t seen that flexibility with other software.”
Ostia
ETD offers a wide range of services through a web-based self-service portal. This includes an extensible library of hundreds of synthetic data generation and data masking functions, a data subsetting capability, and various test data utilities, such as data cloning, data ageing, data comparisons, and service virtualisation. The product’s synthetic data generation functionality is particularly sophisticated, and leverages machine learning-driven, multivariate pattern analysis to determine and replicate the distribution of your source data (this technique is also used in other areas of the product, such as sensitive data discovery). Other capabilities include the ability to create clustered synthetic data for the purposes of AI or graph database testing, as well as advanced support for generating message data (including time series messages) by working backwards from your desired outputs using a solving algorithm. It is also possible to create synthetic data using generative AI, generating data tables directly from your prompts. The product additionally provides a test data catalogue that centralises all of your test data related activities, including test data usage, requests for test data, and the fulfilment of those requests.
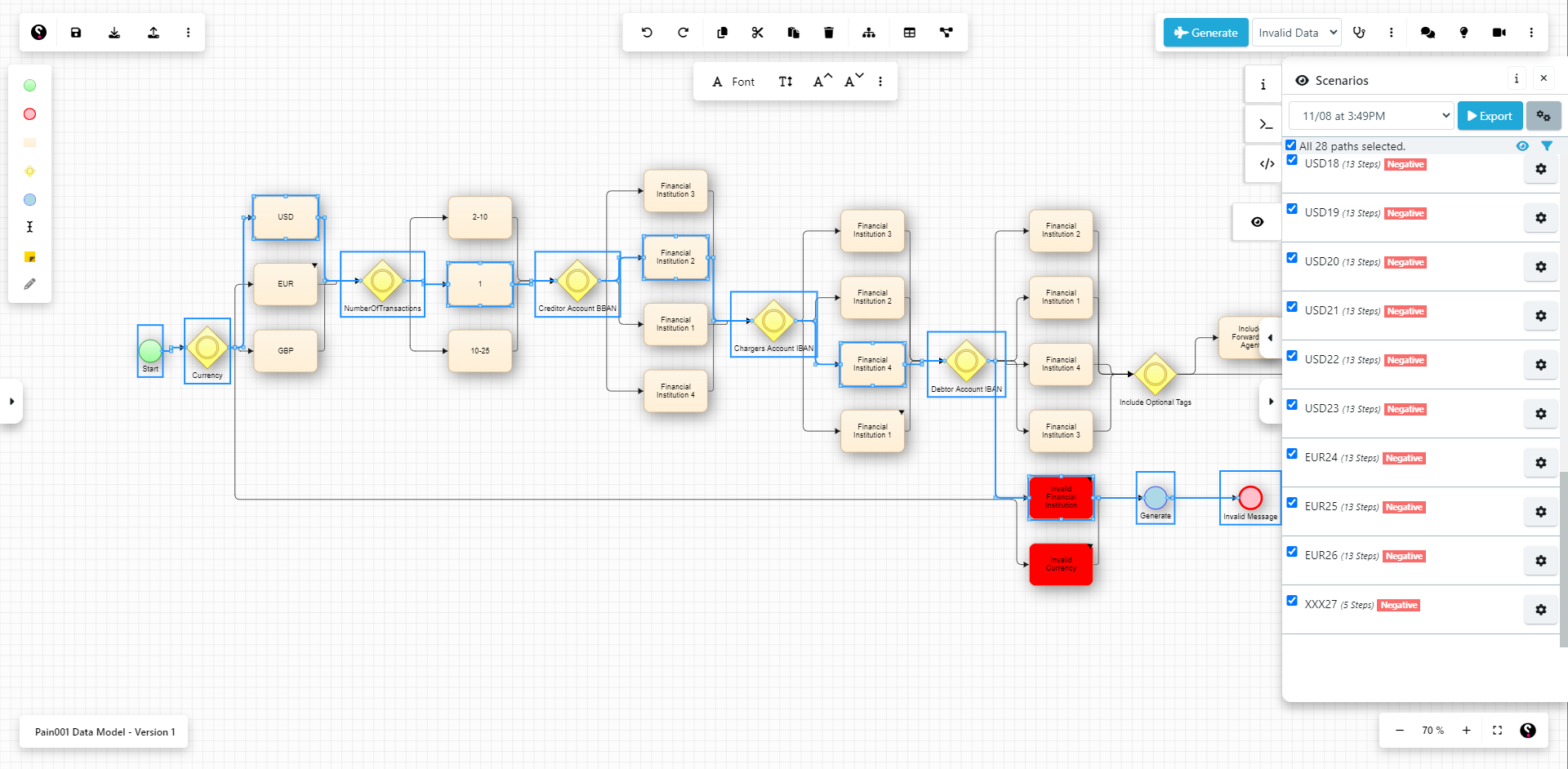
Fig 1 - Overlaying test data onto a model in Curiosity Modeller
Moreover, ETD working in concert with Curiosity’s Modeller is a powerful combination. Curiosity’s Modeller allows you to construct graphical models that mimic your production environment, then leverage those models to automatically generate a set of easily maintainable and maximally covering test scripts. ETD can overlay test data onto those models, as shown in Figure 1, meaning that whenever your test scripts are generated, they will gather whatever test data they need automatically. In other words, using ETD and Curiosity’s Modeller together intimately marries test data with your test automation processes, enabling much more effective overall test automation. Note as well that test data attached to Curiosity’s Modeller is delivered “just in time” to ensure that it is always as up to date as possible when it is leveraged in your tests. Curiosity’s Modeller’s value also extends into several other areas adjacent to TDM, including collaborative requirements engineering, test case optimisation, and risk/change management. All of this combined should allow you to shift your TDM efforts significantly to the left.
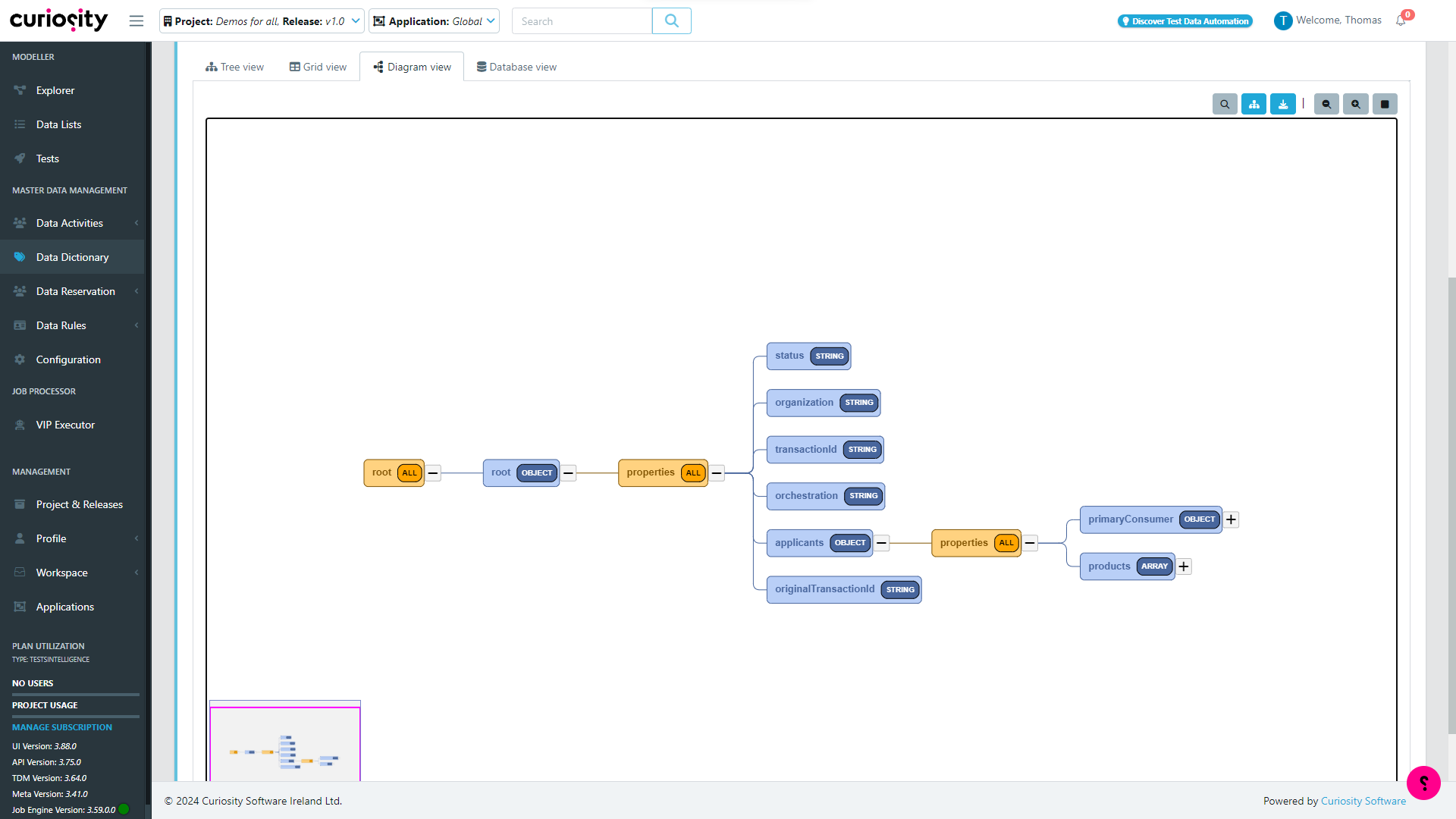
Fig 2 - Visual representation of a data structure in Enterprise Test Data
In addition, production messages, APIs, and databases can all be analysed to identify and visualise key characteristics and trends within your data. This analysis can then be used to ensure that your test data accurately represents these trends and characteristics. This process is dynamic and runs in real-time, meaning that it can execute automatically whenever you create your test data. In this way, it can be used to ensure that your test data is, and remains, meaningfully representative of your production data. This analysis even extends to such areas as master data management (MDM). The most relevant capability in this regard is a catalogue of data structures (including their lineage) that can be populated automatically via AI-driven analysis of your data (or, alternately, by importing Swagger files). Each such data structure is captured as a visual pipeline that can be used for driving test data creation (see Figure 2).
What’s more, as part of its efforts to accommodate an extremely wide set of data sources, and to generate sets of test data from the same, ETD offers something akin to a lightweight data integration/ETL capability. This feature allows you to build “minidbs”, that are accessed and managed within the ETD platform, by collating data from a multitude of different sources. The structures of your minidbs are generated automatically, and if any data in them is modified it can be published back to the original data source. The essential point of this exercise ties into the product’s data analysis capabilities: by moving data from many disparate sources into a single, controlled location, it becomes much easier to analyse it holistically, and thus generate an appropriately covering and representative set of test data.
Finally, thanks to the robust capability for building integration pipelines that underpins Curiosity’s offerings, ETD (and for that matter Curiosity’s Modeller) benefits from a huge variety of prebuilt connectivity and integration options. For APIs in particular, you can import Swagger/OpenAPI JSON specifications, along with the endpoints they contain, to leverage in your models. Past that, Curiosity’s integration with Windocks (one of the company’s partners) is particularly notable for providing containerised database virtualisation that can be executed within ETD.
ETD offers a number of standout features that we have already described. That said, there are two key points that distinguish ETD from its competition. This first is that it offers a wide-ranging test data solution, equipped with a wealth of capability derived from the comprehensiveness of Curiosity’s vision, within a single, integrated platform. This sets it apart from the various point solutions available in the space. The second is that despite the quantity (and quality) of capabilities that the product offers, the company is always striving to add more, to increase the breadth of the product and more fully realise its vision of holistic testing. In short, despite the success Curiosity has achieved with ETD and its other products, it continues to innovate and disrupt rather than rest on its laurels. On top of all of this, the product is highly visual, easy to use, collaborative, and promotes shifting left in the testing process.
It is also worth noting that Curiosity has implemented generative AI capabilities into its testing suite, over and above what we have already mentioned. This allows you to, for example, create and/or edit test models via an AI copilot driven by a large language model of your choice.
The bottom line
Enterprise Test Data is an effective and innovative test data solution that is characterised by the scope of Curiosity’s vision and the continued expansion of its capabilities in order to meet that vision. It offers both an excellent solution now and the promise of an even better solution in the future.
Mutable Award: Gold 2024

Visual Integration Processor
Last Updated: 9th November 2018
Mutable Award: One to Watch 2018
Visual Integration Processor is a .NET based rapid application assembly framework for integrating software. It acts as ‘software glue’, allowing you to very easily assemble existing applications and other software components into a single, automated business process or application. Its chief gain to efficiency comes in its ability to eliminate the need to write large quantities of generic ‘plumbing’ code that is normally needed to pipe software together, opting instead for a user-friendly, drag-and-drop flowchart model that is vastly quicker and easier to use.
Although VIP is a low-code product in the most literal sense – it dramatically reduces the amount of code you need to create software applications – it diverges significantly from much of the low-code market. Where many low-code products focus on customer facing applications, VIP instead emphasises its ability to quickly create and automate business processes. Moreover, it does so without being married to an all-encompassing Business Process Management (BPM) suite.
VIP is available on-premise and in the cloud. It is distributed in packages, with each package providing a ready-made set of connectors that allow you to easily leverage products and tools common to a particular use case.
Customer Quotes
“After evaluating a number of Robotic Process Automation platforms, the UK’s largest house builder decided to go with Visual Integration Processor to undertake their Digital Transformation as it was the only toolchain that was able to fuse workloads from legacy Enterprise IT platforms together with our modern Enterprise Resource Management platform.”
Digital-Assured
“We have found that VIP gives us the flexibility and the range of functionality to tackle any process our customers ask us to automate no matter how complex.”
Ostia Solutions
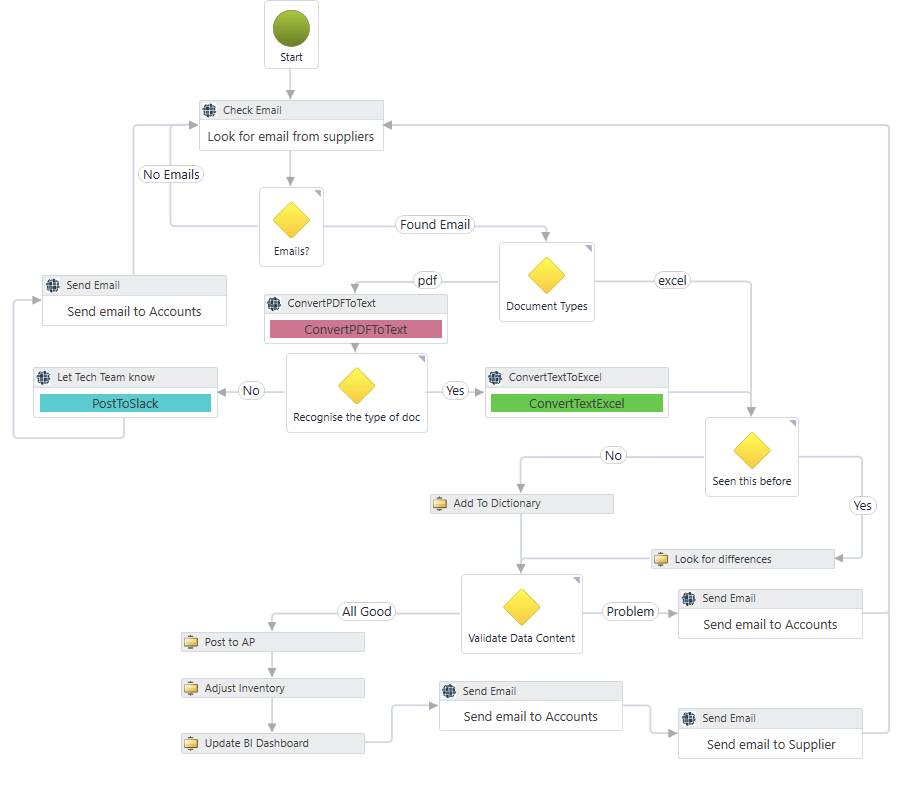
Figure 1 – A flowchart in VIP
VIP allows you to create software applications, including automated business processes, by building flowcharts. These flowcharts are created by dragging and dropping a) connectors to existing software and b) ‘core components’ (basic flow operations such as branching) into a model. This allows you to create sophisticated flows between your different software applications and data sources. An example can be seen in Figure 1. Flows in VIP can be exposed as self-contained components and reused in other flowcharts, allowing for nested flows. It is also possible to include loops in your flowcharts.
The various model components available have a variety of configuration options. Chief among these is the ability to detect variables exposed in any of your connected software components, allowing them to be leveraged and acted upon either by the model itself (for instance, as part of a branching decision) or another software component. Moreover, VIP keeps track of your data as it moves through your flow and allows that information to be accessed at any time. This can be helpful for setting up rules engines or predictive analytics that may be able to act on or derive useful insights from the movement of your data.
A variety of connectors are available out of the box, although the specifics may vary depending on your chosen package. This includes spreadsheets such as Excel and Google Sheets; APIs, including SOAP and REST (specifically, OData); popular data formats, such as XML and JSON; test automation, including Selenium and Parasoft; ‘ChatOps’ integration with Slack and Facebook; and a number of other popular products such as Git and JIRA. Additional, pre-configured solutions are available to enable chat bot integration with Slack, sentiment analysis, and integration with Eggplant Functional. The creation of connectors and solutions is primarily user-driven, and CSI promise to build any additional connectors or solutions that you need.
It is also possible to include software in your model even if it does not have a connector. This includes your own in-house and legacy software. Moreover, if the software in question is written in a .NET language, such as C# or Visual Basic, you can effectively create a custom connector by building the application and placing the resulting DLL file in a pre-specified location for VIP to access. For software where this is not possible, you can leverage test automation products (such as Selenium) to create scripts that automatically interact with your software, then include those scripts in your flowchart. These scripts interact with your software just as a user would, before extracting and relaying any relevant information back to your model.
There are two major use cases for VIP. Firstly, it allows you to easily and quickly create new software applications by stringing together existing software applications and products. Secondly, it allows you to automate your existing business processes, or create new, automated processes, by incorporating actions that would normally be done manually into a flowchart. For example, a very simple flowchart might automatically convert newly uploaded documents into a PDF format, where previously you were having to save each document as a PDF by hand. In this case, the flowchart only represents a small saving in cost. But across an enterprise, those savings can add up rapidly. In addition, VIP supports a model in which your business processes can be automated gradually, starting with the most mundane and repetitive tasks. You do not need to automate everything in one go (or, indeed, at all).
Both of these use cases are enhanced by the fact that creating flowcharts in VIP is easy and intuitive, even without a background in software development. Moreover, the visual models used by VIP are very easy to understand. This is helpful for enabling collaboration between developers and business users (for example, when designing a business process). Finally, it’s worth noting that VIP makes it easy to integrate new technologies into your business processes: all you need to do is add the appropriate connectors. This provides a measure of future-proofing that many organisations sorely lack, particularly in the current climate of extensive (and in some cases recurring) digital transformation.
The Bottom Line
VIP is a lightweight, easy to use product for assembling disparate software into a single application or automated business process. It allows you to automate as much, or as little, as you like, and can interface with a large variety of testing products, data types, and APIs out of the box. All in all, it is an effective point solution for automating your business processes. If that is your interest, we wholeheartedly recommend adding it to your shortlist.
Mutable Award: One to Watch 2018
Research

Test Data Management (2024)

Curiosity Software Test Data Automation (2024)

Test Data Management (2021)

Curiosity Software Test Data Automation (2021)

Application Quality Assurance

Test Design Automation
