
IRI Test Data Generation
Published:
Content Copyright © 2023 Bloor. All Rights Reserved.
Also posted on: Bloor blogs

We started this series of articles by talking about test design automation and the need to introduce automation throughout your testing processes. In this blog we come full circle to talk, once again, about testing.
Now, however, we are going to discuss test data generation specifically. This forms a significant subset of test data management, being that it is an integral part of keeping your test data secure while allowing it to retain the characteristics that are important to your tests. To wit, either you will want to find any sensitive data within the data you want to test, then replace much or all of it with masked data; or you will want to generate entire sets of synthetic data (which is to say, data that is realistic but not real) for testing purposes. Or, quite possibly, both. Regardless, you will need some degree of test data generation capabilities. For generating masked data, see the previous article in this series, in which we discuss this topic at length. For synthetic data generation, read on, although note that – at least in IRI’s case – the two can quite readily be combined together.
Synthetic data generation can either be thought of as an alternative to the traditional method of generating test data via subsetting and masking, or as an addition to it, in which it is used to generate the masked data that is used to replace your sensitive data. In either case, one of the most important aspects to understand about synthetic data generation is that it does not just generate random data. Rather, it uses sophisticated methods to analyse the structure of an existing data set, then produces a new data set composed of data that is entirely fake individually but that possesses the same statistical properties of the original data set when considered as a whole. This is sometimes referred to as “preserving statistical integrity” (in contrast to preserving referential integrity, which is vitally important for masking data consistently across relational databases while maintaining existing relational structures in the masked data). Thus, you end up with a selection of entirely safe data that cannot possibly be used to identify an individual but is still just as useful as the original, sensitive data set for the purposes of testing. That is the ideal, anyway – the degree to which various vendor offerings actually achieve this varies considerably.
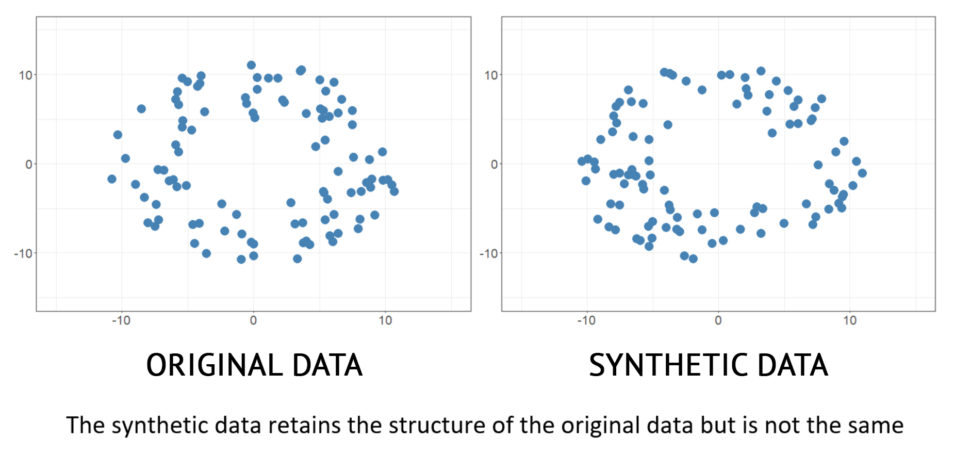
IRI Voracity – or, more specifically, IRI RowGen – is available for generating “realistic but not real” synthetic data. It places particular emphasis on test data customisation: on giving you fine-grained control over what data is generated, and moreover, how and where it is generated. For instance, at a basic level it can either generate test data based on available information provided to it or select data randomly from a “set file” that has been prepared ahead of time, either by hand or in IRI Workbench. These set files may themselves consist of synthetic data, or of real data that has been isolated from any associated data to the point that it is not identifying. Set files can also be simple lists or have multiple columns. The general idea is that multiple set files can be drawn from simultaneously to create a holistic data profile for a person or other entity that doesn’t actually exist, but that has realistic attributes drawn from your actual data.
Various generation functions are available for creating test data sets, including both the specific – say, national ID number generation – and the generic – such as generating data according to a predefined, weighted statistical distribution. There are multiple ways to customise the end results of these functions: test data can be generated in such a way that each value is unique, each value in a set file can be mandated to be used exactly once, and so on. You can even define your own compound data formats.
In short, whether synthetic test data is randomly generated or selected, its production characteristics – including original data formats and sizes, value ranges, key relationships, and frequency distributions – are preserved. Basically, there is a lot of customisation of test data available, and it should be obvious that this can be useful for tailoring your generated test data to your specific business needs. Moreover, this extends past just what data you are generating and also encompasses how and where you are generating it (which means that you could, for instance, generate data as part of a CI/CD pipeline). This adds further depth of functionality to the test data generation, and more specifically the test data customisation, offered by RowGen in particular and Voracity in general.