
Striim
Last Updated:
Analyst Coverage: Philip Howard and Daniel Howard
Striim was founded in 2012. Originally known as WebAction, it was rebranded following a significant funding round in 2015. At time of writing, it has recently benefitted from another round of funding that has contributed to its rapid growth throughout 2021. Its offices are in Palo Alto, but it has a global presence, in part due to its robust (and growing) network of partners that includes both systems integrators and technology companies.
Striim
Last Updated: 14th December 2021
Striim is an enterprise-level platform that offers continuous, real-time data integration, Change Data Capture (CDC), and stream processing, including streaming integration and analytics. It particularly emphasises the use of integration and streaming activities to continuously deliver large volumes of data to various data platforms, most notably to cloud environments such as cloud data warehouses, in real-time. Thus, it enables and accelerates cloud migrations. Applying continual streaming analytics to those environments during and after the fact is the cherry on top.
Striim provides specific capabilities to support compliance with GDPR. For example, Striim can integrate and modify, and hence filter or mask, data in real time. You can use Striim to maintain a single customer view, to confirm compliance and/or detect breaches in real time, and to provide real-time monitoring. That said, these sorts of capabilities clearly have much broader applicability than just compliance: to the Internet of Things (IoT), to fraud detection, and so on.
Striim also boasts strong partnerships with Microsoft and Google, including a strategic migration partnership with the latter. It has a strong track record of integrating with new technology as it emerges, including major cloud technology for the three major public clouds (namely, Amazon Web Services (AWS), Google Cloud Platform (GCP) and Microsoft Azure), and it provides a selection of connectors to this end. It can be deployed to any of the aforementioned public clouds as well as Snowflake. Striim’s fully managed cloud service is currently in private preview for invited customers. Various standard-but-useful enterprise capabilities are also available, including a variety of security features, high availability, monitoring, alerting, and so on.
Customer Quotes
“Thanks to the Striim team, Macy’s was able to move to the GCP Cloud way faster than what was originally thought was possible.”
Macy’s
"Thanks to Striim we are accelerating our customer insights in Snowflake. Our legacy analytics platform used to take an hour per customer data load and weeks for each new deployment. With Striim we are able to transfer operational data to Snowflake in near realtime for all customers."
Inspyrus
"When we want to build new applications on Striim’s streaming data, it only takes a couple of days — as opposed to months — to deploy.
Ciena

Fig 1 - Striim user interface
Striim provides a web-based, graphical, partially wizard-driven, partially drag-and-drop development environment. Through this user interface, illustrated in Figure 1, you can capture data from many sources, such as databases via CDC (which is non-intrusive, and compatible with all past and future versions of any given data source), log files, message queues (Kafka, RabbitMQ and others), events, and so forth. You can then build transformation and analytics pipelines, and connect the results to dashboards, external storage, and messaging platforms, enabling data integration, data movement, and similar processes. A preview capability is provided for test and debugging prior to the deployment of the application on the operational platform.
Pipelines are built using Striim’s proprietary SQL-like language, TQL. TQL runs in-memory and, in addition to filtering, transformation and aggregation of data, can be used to enrich streaming data with reference data stored in the built-in distributed in-memory data grid. There is also a facility for users to add extensions written in Java, and the platform supports the import and export of Java analytic models. although not models using R or Python. Nor does the company support Predictive Modelling Mark-up Language (PMML). Tumbling, sliding, and session windows are supported based on record count, time or data attributes, with support for filtering and aggregation, joining streams and historical data, pattern detection, and there is a library of predictive analytics functions. A wide range of connectors are provided, although beyond MQTT and OPC UA (both IoT protocols) you may need to work with one of Striim’s partners for IoT sensor connectivity.
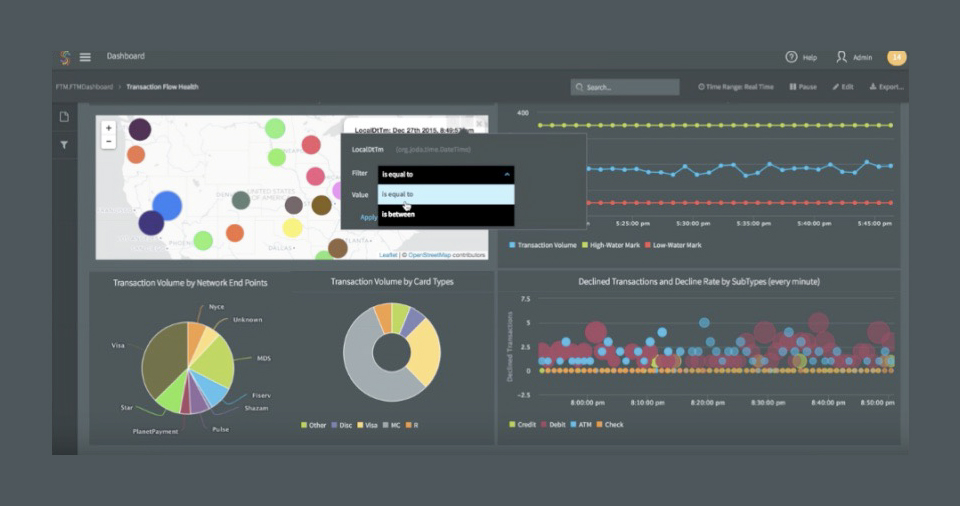
Fig 2 - Striim dashboard and charts featuring filter capabilities
As far as dashboards and visualisations are concerned, there are a number of noteworthy features. For example, Figure 2 shows the ability to filter real-time data, either by time or by field. The ability to rewind time-based queries to look at past data is also provided, as is page- and chart-level searching and filtering. Striim charts can also be embedded into other HTML pages.
The Striim platform is highly scalable and has an elastic architecture. The distributed execution platform combines a continuous query engine, an in-memory data grid, a high-speed messaging system, and a results cache built on Elasticsearch. Incoming data streams are sharded over the cluster for horizontal scalability, with checkpointing provided for recovery and restart from the last known good state, providing exactly once processing (E1P) guarantees. There are also significant integrations with cloud providers (including features such as multi-threading), notably with Amazon (AWS and Kinesis) and Microsoft Azure, and there are also specific facilities to monitor Kafka environments.
Striim is also planning to release Striim Migration Service (currently in private preview), a managed service designed to make database migrations faster and easier. Example (planned) features include a friendly graphical user interface and a built-in assessment of migration viability.
In addition to streaming analytics (anomaly detection, correlations, pattern matching and so forth), there are a host of applications that require stream processing and/or streaming integration, ranging from zero-downtime migrations through database integration and data modernisation, to data distribution, that much of the space of the streaming space has neglected to address. Indeed, Striim stands alone in its emphasis of these use cases. The fact that Striim reports that a majority of its customers deploy the platform for streaming integration in the first instance should speak to their importance.
At the same time, Striim does significantly more than just stream processing, most notably by incorporating streaming analytics as well. CDC is also a significant inclusion that can be essential, in particular for capturing and migrating changes that have occurred during the data migration process itself, thus allowing you to perform migrations without disrupting regular operations. In addition, Striim has gone to some lengths to ensure its CDC is reliable and secure, even across multiple streaming and non-streaming connections. It is also worth noting the platform’s support for machine learning, not just to deploy machine learning but also to use streaming data to train your model.
The Bottom Line
Striim continues to distinguish itself from its competitors by focusing on streaming integration – and thence cloud migration – as well as streaming analytics. Likewise, we continue to be impressed.

Commentary
Solutions
Research

Stream Processing

Streaming Analytics (2021)
