TigerGraph
Update solution on September 11, 2020
TigerGraph uses a property graph paradigm and has been designed specifically to support real-time (less than one second) analytics. The keys to achieving this are parallelism, compression and the way that, in TigerGraph, graph edges and vertices are not just units of storage but also computational units. The engine supports the processing of these in parallel, and the product also includes a parallel loader, as the product’s architecture, shown in Figure 1, illustrates. Compression can be more than 10x, according to TigerGraph, and compression is also used as a part of the loading and transformation processes, to further improve performance. Also relevant is the graph partitioning, which supports application-specific partitioning as well as mixed partitioning strategies. This is all handled automatically within TigerGraph Cloud. There is also the ability to run multiple graph engines, with each engine hosting identical graphs with different partitioning algorithms tailored for different types of application queries. The front-end server will route application queries to the relevant engines based on the query type.
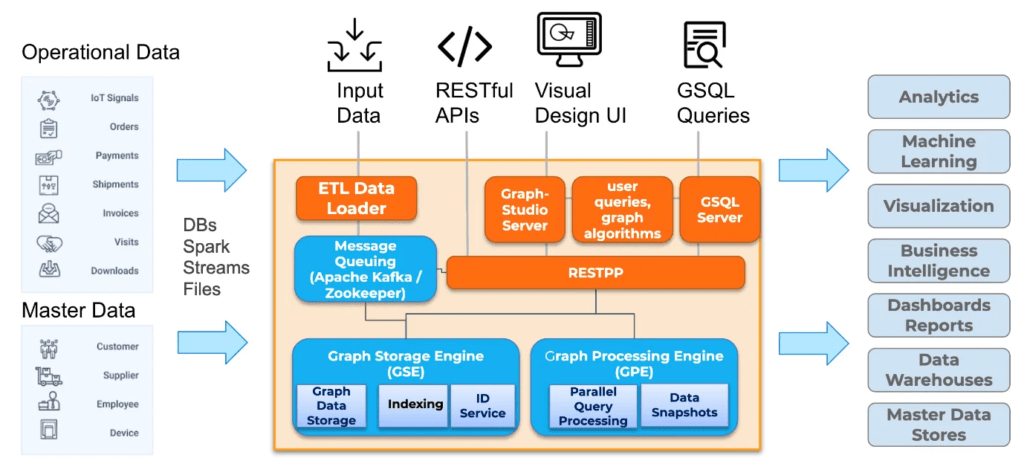
Fig 01 – Architecture overview
Other significant features include security (single sign-on, support for LDAP and Active Directory, encryption – both in motion and at rest – and role-based access control); more than 20 starter kits for TigerGraph Cloud (examples include data lineage, financial services fraud detection, and in-database machine learning for real-time recommendations); user-defined indexing; and a collaboration service whereby multiple groups can share a single master database, with each having their own view into the database. This has important implications for compliance (not least GDPR) because this service allows you to manage and monitor data access, data lineage and personal data. This includes where a point of data was first acquired, whether consent was given in obtaining it, where it moved over time, where it resides in each system, and how it gets used.
In the latest release (3.0) GraphStudio has been extended to provide a no-code migration capability from relational databases. At present this is limited to supporting PostgreSQL and MySQL, but this is likely to be extended. The company estimates that around 80% of the effort involved in migration will be automated through the use of this tool.
Customer Quotes
“We selected TigerGraph for its superior data warehousing speed and computational processing capacity, which improved performance by an order of magnitude.”
IceKredit
“Alipay streams 2B+ daily events in real time to a graph with 100B+ vertices and 600B+ edges on a cluster of only 20 commodity machines.”
TigerGraph is about real-time analytics for anomaly detection, pattern recognition, IoT applications, making recommendations (next best offer) and similar environments where low latency is required. It supports both supervised and unsupervised machine learning and a target market for the company is in leveraging its graph models to generate training data for machine learning purposes. TigerGraph also supports geolocation capabilities, which are important in many IoT and similar environments. However, it does not offer support for shape files and polygon processing, which is why we refer to it as supporting geolocation rather than geospatial capabilities.
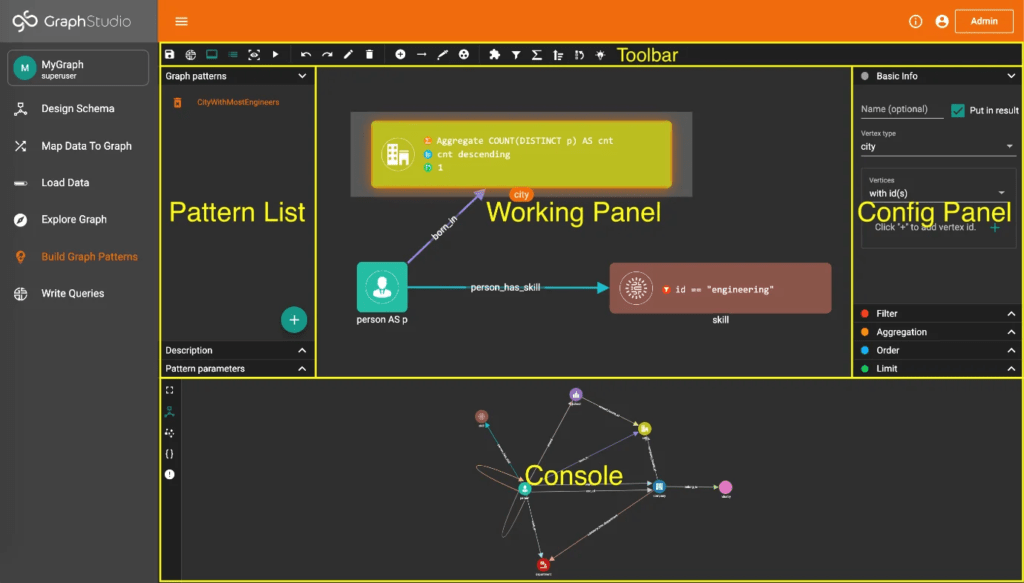
Fig 02 – TigerGraph’s visual query builder
You can access the database via GSQL. As its name suggests, this is “SQL like”. However, the company also offers a browser-based capability called GraphStudio that can be used to create graph models, queries and so forth. This has been built on top of GSQL to make the environment more user friendly, allowing ad hoc exploration of your data. Indeed, in the latest release TigerGraph has added a visual query builder – see Figure 2 – to GraphStudio, which means that anybody can build queries without having any knowledge of GSQL. We expect this to become the de facto standard method for working with TigerGraph.
In addition, a migration toolkit is provided to port queries from Cypher into GSQL, allowing you to easily reuse queries written in that language. There is also a GSQL software developer’s kit (SDK) that third party graph specialists could use to integrate with TigerGraph, and there is a RESTful API capability, which means that it should be relatively easy to integrate with third party tools such as Tableau. We would like to see the company supporting GraphQL as an alternative API. A user extensible library of graph algorithms is also provided. Several algorithms (such as PageRank) are available out of the box.
The key point about TigerGraph is its performance. Most other graph databases were built originally to support operational environments and were not intended to be used for complex large-scale and real-time analytics, though they may have been extended in that direction since they were originally designed. TigerGraph, on the other hand, was designed specifically for these environments.
We are also particularly pleased by the introduction of the visual query builder, which should help to democratise the use of TigerGraph by providing self-service capabilities for business analysts and others that do not, and do not want, to understand GSQL.
The Bottom Line
We should emphasise “complex, large-scale and real-time” as well as “analytics” from the previous section. Add in the ability to process operational data in real-time and you should understand where and why TigerGraph has significant advantages.
Related Company
Connect with Us
Ready to Get Started
Learn how Bloor Research can support your organization’s journey toward a smarter, more secure future."
Connect with us Join Our Community