Global IDs Enterprise Data Automation
Update solution on March 29, 2021
Global IDs does not see data quality as an isolated set of functions. In fact, the company’s methodology is illustrated in Figure 1, and as can be seen, data quality is actually step nine of ten. Specifically, it leverages earlier steps and particularly the discovery, profiling, classification, lineage, and catalog (the platform includes a data catalog) functions to establish effective quality controls, though it can be deployed without all of these previous steps. These all do much as you would expect them to do – or perhaps more – in terms of functionality but what really sets the whole Global IDs environment apart is its emphasis on data management at scale or, as in this case, data quality at scale. As an example of this, one of the company’s clients has two thousand applications, ten thousand databases, ninety thousand schemas, twenty million tables, and two hundred and thirteen million columns under management using Global IDs’ software. And this isn’t even its largest customer, which has five hundred million columns under management.
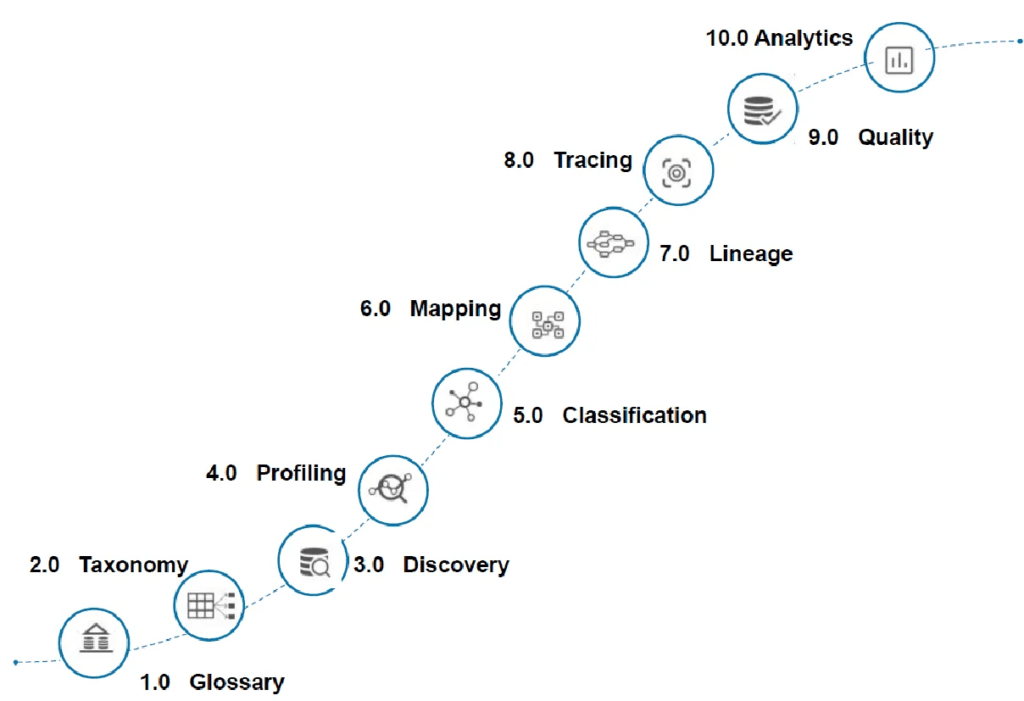
Fig 1 – The Global IDs methodology
As a precursor to data cleansing operations, the Global IDs data profiling capability provides the sort of histograms and analysis that are commonplace for these sorts of tools. As far as data quality itself is concerned the company takes two approaches: rules-based data quality and machine learning based data quality, with the former applied to single and/or multiple columns and/or rows, while the latter is only used against single columns. In the case of multiple columns these are categorised by semantic domain (for example, checking the format and consistency of email addresses across multiple physical columns). More generally, data quality checks are used for completeness, conformity, consistency, integrity, and timeliness. While there is no match engine per se, rules can be used to check the uniqueness of any particular physical row to identify duplicates.

Fig 2 – Profiled UK postal code results based on the domain rule generator
Global IDs provides a domain rule generator. For example, Figure 2 shows an example of profiled results for UK postal codes.
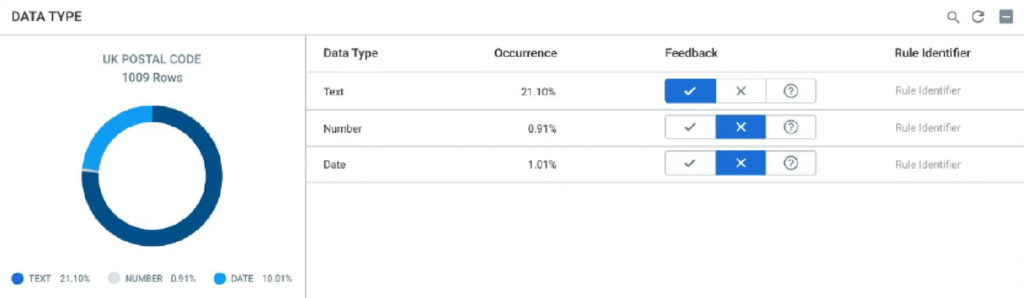
Fig 3 – Selecting datatypes in the domain rule generator
In the domain rule generator, you select the datatype – see Figure 3 – then the format (length plus pattern) using a similar clicking of the appropriate box and finally a word analysis, again based on the profiled results. The rule is then generated for you.
As far as machine learning is concerned, although its data quality use is confined to single columns it can be used in conjunction with classification to, for example, determine that a particular domain contains sensitive data. When running machine learning for data quality the software will make predictions about expected values along with confidence levels.
Other notable facilities include reconciliation analyses that compare source and target records. Needless to say, the company provides a data quality dashboard so that you can monitor data quality over time.
We have made much of the fact that Global IDs is focused on data management at scale. However, we should note that what the company means by “at scale” is an order of magnitude greater than what most other vendors mean when they talk about scalability. For instance, Global IDs will currently admit that its row-based data quality is not “at scale” to the extent that it would like. But it’s probably already comparable to other tools in the market. However, running at scale causes other problems because it makes visualisation, in particular, difficult. The company therefore partners with Neo4j so that it can represent relationships in the data as a graph, as illustrated in Figure 4.
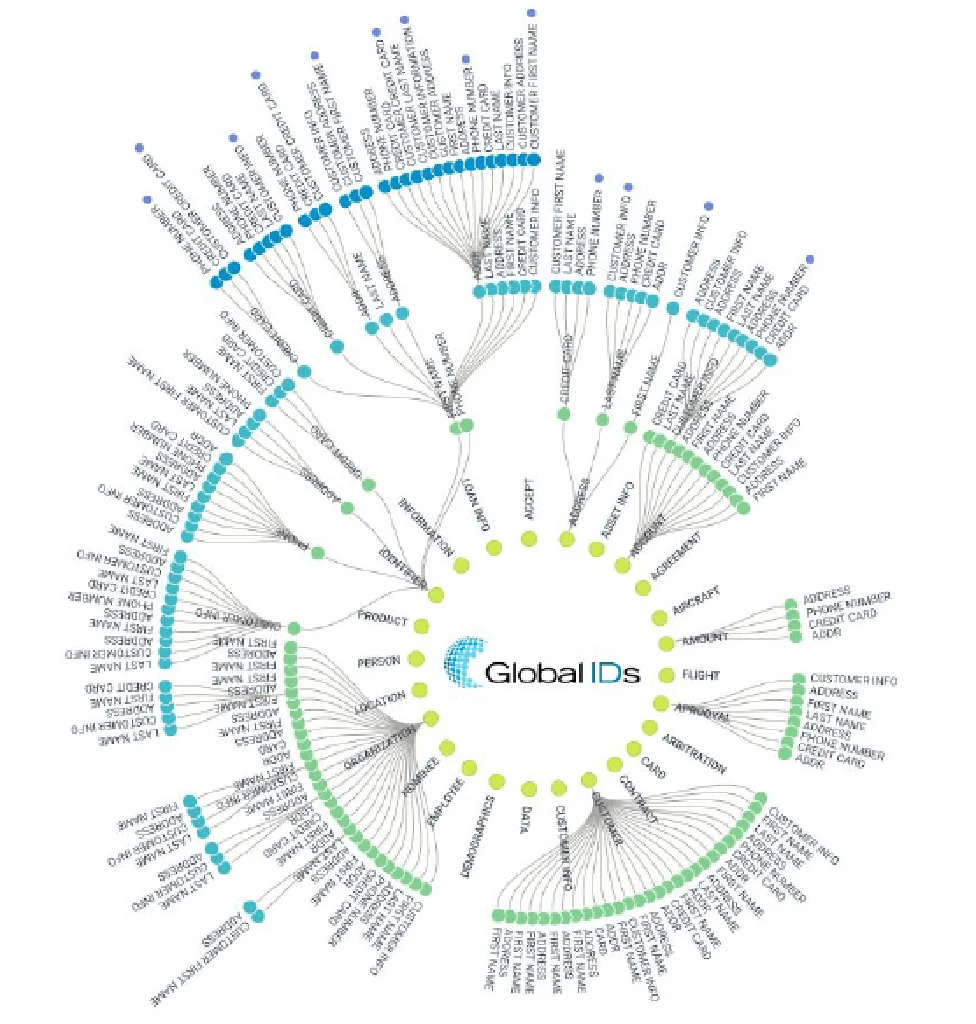
Fig 4 – Graph visualisation of data relationships
Aside from that, the major point in Global IDs favour is that it sees, and supports, data quality as a part of a chain of data management requirements rather than something that is a stand-alone function. We concur with this view but it does mean that you are unlikely to select Global IDs purely for data quality purposes but only as a part of a more holistic solution.
The Bottom Line
Global IDs focuses on the most intractable and complex data management problems. Typically, in the largest enterprises with huge volumes of data. We are not aware of any other vendor that has this singular focus. If your company falls into this category Global IDs should at least be on your short list of potential providers.
Related Company
Connect with Us
Ready to Get Started
Learn how Bloor Research can support your organization’s journey toward a smarter, more secure future."
Connect with us Join Our Community