DataStax Enterprise (DSE) (Graph Engine)
Update solution on September 11, 2020
DSE is a distributed database oriented towards (though not exclusive to) a hybrid-cloud architecture. It is built on top of Cassandra and includes native search and analytics, continuous availability, and significant increases to speed and performance. It is available on-premises, in-cloud, or as part of a hybrid solution. A recently released offering, DataStax Astra, provides open source Cassandra as a database-as-a-service offering and although this supports the GraphQL API it does not currently (this may change) include DSE’s graph engine.
The graph engine in DSE is based on a property graph solution that is optimised for storing billions of items and relationships. It is suited for both transactional and analytical processing. In accordance with the latter, it also supports Spark-based analytics.
Customer Quotes
“DSE’s scalability and analytics capabilities provide us what we need to not only analyze every aspect of the supply chain, but also bring new innovations to market.”
elementum
“Graph analytics is great for showing relationships between data points, and this can be very valuable in a healthcare scenario. By looking at data in different ways within the same platform, we can support more in-depth interactions with patients and improve healthcare outcomes.”
Babylon Health
The DSE Graph Engine is a property graph that is built into DSE and leverages DSE’s capabilities for storage, search and analytics. Consequently, it inherits the scalability, high availability, performance (as much as 10 times faster with this re-engineering) and real-time processing that Cassandra and DataStax are well known for, with scaling up to billions of entities. In service to this, it leverages optimisation techniques such as query optimisation, data partitioning, and distributed query execution, among others. In particular, now that the graph data model is within the platform, this means that you can store your data exactly once but access it via either Cassandra or Gremlin (part of Tinkerpop) APIs. This means, for example, that you can create CQL (Cassandra Query Language) tables and read them via Gremlin, or vice versa. Thus providing interoperability and transparency. SQL and Spark APIs are also supported, with the latter supporting streaming environments as well as batch processing.
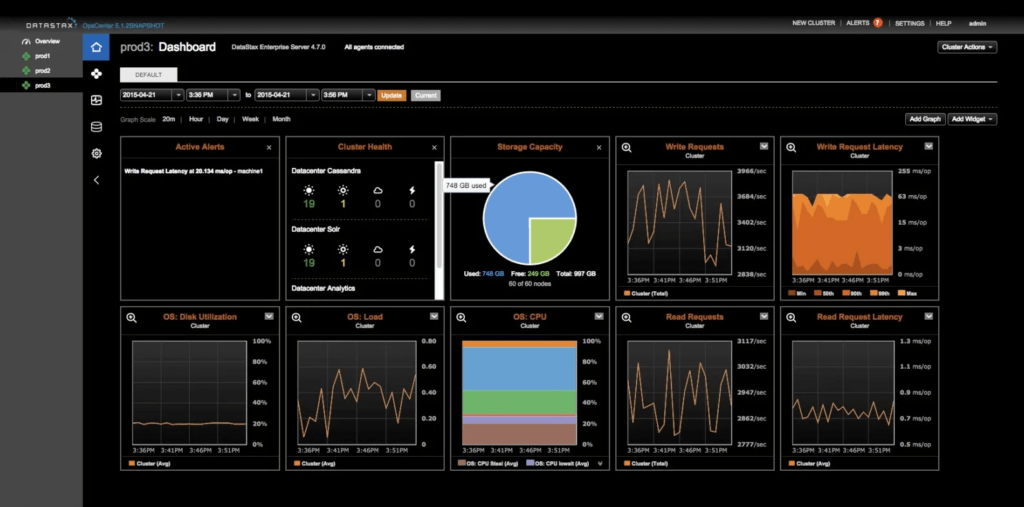
The Graph Engine is designed for both transactional and analytical processing, and consequently features two processing engines – one transactional, one analytical – and allows for both OLTP and OLAP graph traversals. Furthermore, switching between engines (and therefore modes of traversal) is relatively simple, and can be done without altering the underlying data. This means that you can leverage transactional and analytic queries on a single set of data, as needed. In addition, analytical and transactional workloads are separated, and automated workload management is provided. Notable new features for graph processing include significantly faster and simpler loading processes (because you are now simply loading into Cassandra) and intelligent indexing tool that analyses the traversals that you regularly make and then recommends appropriate indexes in order to optimise traversal performance.
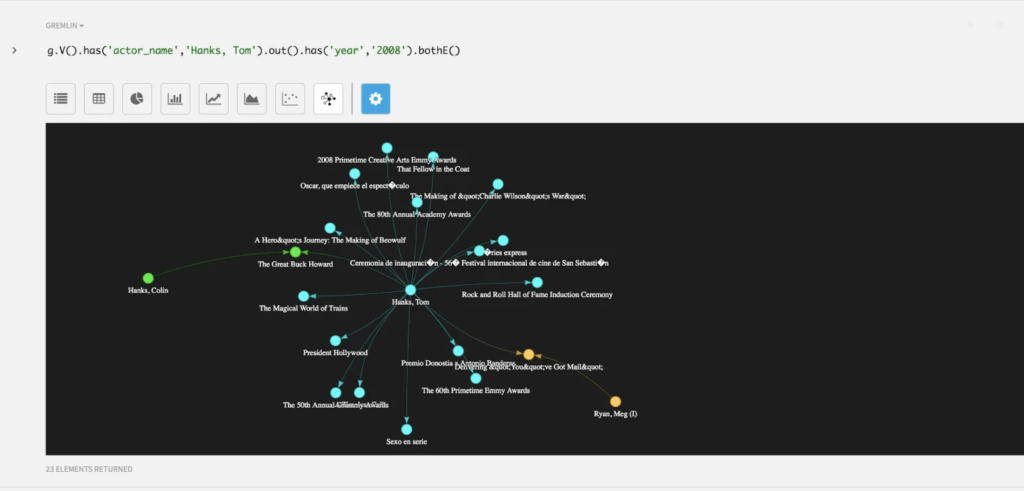
Fig 02 – DataStax Studio
There are a variety of tools for managing all aspects of your graphs and graph clusters. This includes Lifecycle Manager and OpsCenter, which allow you to automate and visualise the creation of new graph clusters, respectively. However, the most important tool for interacting with the Graph Engine is probably DataStax Studio (see Figure 2), a visual, browser-based development environment for your graph. It supports Spark SQL, Gremlin, and CQL (Cassandra Query Language), and additionally comes with a built-in smart Gremlin editor, similar to an RDBMS smart query editor. In fact, much of DataStax Studio is similar in feel to the visual development tools available in more conventional, relational environments. Moreover, to support the visualisation aspect of this tool, DataStax partners with a number of visualisation vendors, including Cambridge Intelligence, Tom Sawyer, Linkurious and Tableau (although the latter is a more general partnership, and not specific to graphs).
In the past, we have commented that graph was well-integrated within DSE and that it therefore shared many of the advantages of Cassandra. However, now that the Graph Engine is built in such a comment seems superfluous. Perhaps more to the point, to all intents and purposes DataStax no longer markets its graph capabilities as distinct from Cassandra. Of course, it is still available for use in that way if that is what you want to do, but the emphasis is now much more on how the two are complementary, whether that is in IoT environments or for applications involving Customer 360o or in a variety of other use cases.
The Bottom Line
DataStax is targeting DSE, including its Graph Engine, as “the cloud native platform for developers with zero lock-in, zero downtime at global scale”. Cassandra itself is, of course, widely seen as a popular environment for this purpose. By re-architecting DSE so that the graph data model is embedded within the platform DataStax is making the incorporation of graphs as a part of an application, rather than the whole thing, that much easier for developers. It makes a lot of sense.
Related Company
Connect with Us
Ready to Get Started
Learn how Bloor Research can support your organization’s journey toward a smarter, more secure future."
Connect with us Join Our Community