Compuware Test Data Management
Update solution on June 18, 2019
BMC Compuware Topaz for Enterprise Data forms the bulk of BMC’s test data management (TDM) solution. More generally, it focuses on visualising and manipulating enterprise data across both mainframe and distributed systems. By incorporating elements of – or, failing that, integrating with – various other BMC Compuware products, most notably BMC Compuware File-AID and BMC Compuware Topaz Workbench, Topaz for Enterprise Data provides an effective, all-in-one platform for TDM.
Note that all Topaz for Enterprise Data functionality can be applied to (and, in regards to data masking, is consistent across) both mainframe and distributed data, and that in either case your test data can be accessed and handled through a single, universal, self-service user interface. Moreover, the introduction of an open framework – complete with a CLI for executing Topaz for Enterprise Data specifications – allows the most recent version of the product to readily operate as part of both a continuous testing and delivery process and a full DevOps toolchain. Finally, the product can be installed and will process data both on premises and in the cloud, provided proper data access rules are defined.
Customer Quotes
“Topaz provides our developers with a way to implement data privacy rules to obfuscate multiple data types across platforms and with consistent results.”
TCF Bank
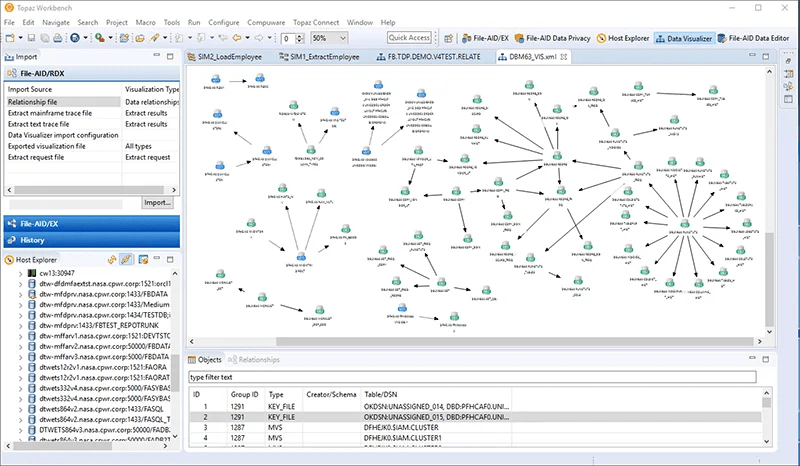
The most basic functionality Topaz for Enterprise Data provides is the ability to easily browse and edit your data across a variety of data sources and file formats, including DB2, IMS, SQL Server, Oracle and VSAM, and in a variety of preset or custom layouts (including raw data, for those who need it). This includes a wide range of functionality, such as comparing data files, visualising data relationships (courtesy of the Data Visualizer, seen in Figure 1), and copying data from one LPAR to another. For TDM, Topaz for Enterprise Data offers data identification, masking, and subsetting, the latter via its ETL capabilities. The product also offers some data generation capability; however, this is recommended for use only as a complement to data masking and not as a standalone synthetic data capability.
To facilitate masking, you must abstract each type of data in your system (for instance, ‘first name’ data) into a ‘data element’ that can then have fields and masking rules attached to it (the former automatically via field name matching). A coverage view is available to display these associations, and a number of masking rule actions are available out of the box. Additional rule logic can be created via an expression builder. Masking rules can be collated and managed centrally, and each rule (or set of rules) is dynamically applied to its associated data element (or subset) at execution time.
Referential integrity is always maintained when masking, masking is propagated across relationships, and BMC Compuware’s patented ‘composite processing’ ensures that your data is masked consistently, even when it is present in multiple formats or contained within a larger field. For instance, Topaz for Enterprise Data will recognize that “Mary Jane Smith” and “Smith, Mary Jane” are the same name and mask them appropriately.
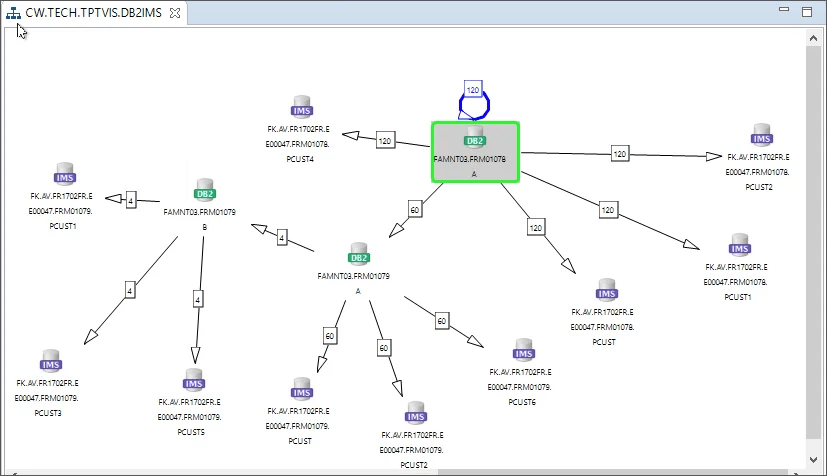
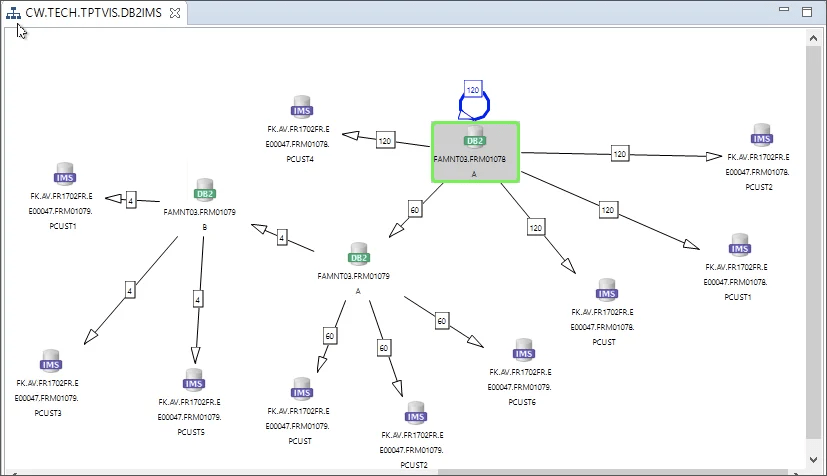
Fig 02 – Extract Visualizer in Topaz Workbench
Subsets are created via fairly standard ETL processes, albeit with a grip of extra features pertinent to TDM. Extracts are created using a driver table; referential integrity is maintained within the subset, as well as between the subset and any relevant applications (specified manually); and the makeup of your extract is presented to you visually, including a step-by-step breakdown of how your extract was created (see Figure 2). The transformation step is achieved by applying expressions, and loading via drag-and-drop column mapping. Both are, as mentioned, fairly standard.
Note that everything we’ve said in this section applies equally whether you’re working with the mainframe or with distributed systems. In addition, reports and audit logs are generated throughout.
Compuware distinguishes itself via its extensive support for the mainframe, which is outstanding in the test data management space. The fact that it will handle mainframe and distributed data sources consistently and within a single platform is particularly helpful. Moreover, Compuware’s test data management offering has historically been very easy to use – especially bearing in mind that it manages mainframe data – and this is even more true now that several important test data management capabilities have been consolidated within Topaz for Enterprise Data.
In addition, the abstract nature of data elements in Topaz for Enterprise Data makes it easy to mask several different but conceptually similar fields using the same set of rules, and minimises maintenance issues if those rules are ever changed. That said, matching fields to data elements based on their names is not always ideal: in practice, fields tend to be named arbitrarily and not necessarily with forethought. However, this is mitigated somewhat by the ease of adding fields to data elements and use of the coverage view to preview data identification and rule assignment.
The Bottom Line
If you want to leverage mainframe data for testing purposes – either in conjunction with distributed data or not – you should certainly be considering Topaz for Enterprise Data.
Related Company
Connect with Us
Ready to Get Started
Learn how Bloor Research can support your organization’s journey toward a smarter, more secure future."
Connect with us Join Our Community