K2view Agentic Test Data Management
Update solution on June 24, 2026
K2view (named for the famously difficult-to-climb mountain) was founded in 2009, and has offices in the US, Germany, Israel, and the Netherlands. It is the developer of the K2view Data Product Platform, which originated as an ETL tool but has since grown into a widely-encompassing data management offering capable of addressing a variety of enterprise use cases. Its capabilities include data integration, data governance, data fabric, cloud migration, 360-degree customer view, test data management, sensitive data discovery, data preparation/delivery for AI, and more.
K2view Agentic Test Data Management combines K2view’s established Test Data Management solution with the new Test Case Data Agent add-on. It builds on K2view’s pre-existing sensitive data discovery, data masking, test data provisioning, test data cloning, and synthetic data generation capabilities by incorporating an agentic AI layer that interprets your test requirements and orchestrates appropriate test data creation actions across the K2view platform. In other words, it automatically creates and delivers usable, compliant test data directly from your requirements. The goal is to accelerate your test data creation and provisioning, and thereby your testing as a whole, so that it can keep up with the accelerated pace of AI-enabled software development rather than bottlenecking it.
Note that K2view’s synthetic data generation capabilities are delivered through K2view Synthetic Data Management (SDM). This requires a separate license from the rest of the platform but seamlessly integrates into it, with both SDM and non-SDM capabilities sharing a single interface and workflow.
The core of the K2view platform is its organisation of data into business entities (such as customer, account, or policy) contained within virtualised Micro-Databases that unify all data related to each entity, across all of your systems, into a single conceptual location. This makes it significantly easier to manage your data effectively, as it allows you to operate on each entity holistically, rather than as a collection of disparate fields. For instance, applying typical test data management operations – such as masking, subsetting, cloning, or synthetic data generation – at the entity level can preserve any relationships present in the original entity, and will always maintain referential integrity.
K2view’s test data management offering includes entity-level data masking, which is format-preserving, maintains existing relationships, and is consistent over multiple systems, formats, and masking runs; data subsetting, for creating a subset of business entities (which inherently retain referential integrity); (sensitive) data discovery and classification, via its data catalogue, using predefined regular expressions or an LLM plugin to examine both data and metadata; and synthetic data generation/management for both structured and unstructured data, via either entity data cloning (repeatedly duplicating and masking an existing entity), rule-based data generation (creating fake entities with field values determined by predefined rules), AI-based generation (described below), or a guided method that creates synthetic data directly from natural language prompts.
The latter two capabilities take particular advantage of AI, and more specifically machine learning. The platform’s data discovery uses it to help identify and classify your data, as well as generate textual descriptions of said classifications, while its synthetic data generation can use it to analyse your production data and generate synthetic entities which collectively approximate its statistical properties and distribution. Statistical reporting is provided as a means to validate this synthetic data, and model training capabilities are provided to facilitate AI use in general. In fact, synthetic data can itself be used to train your models, and there is significant reason to use it for this purpose in lieu of other kinds of data (anonymity, for one; the ability to train for very specific data scenarios, for another.
K2view also uses AI to abstract the technical underpinnings of test data management. For instance, a chatbot-style interface is available throughout the platform, allowing you to interact with it via natural language and making test data management available to all of your users, no matter their technical capability. This cause is furthered by Test Case Data Agent, which provides AI agents that interface with your requirements tools (such as, though hardly limited to, Jira), proactively recognise the test data your requirements demand, then create and deliver that test data automatically. More formally, this is a multi-step process in which an agent:
- Interprets the intent of a given requirement (which could be a user story, test case, or script) and identifies its test data needs.
- Creates a test data provisioning plan, incorporating the relevant data and metadata assets (which could be business entities, parameters, filters, task types, and/or data conditions) and accounting for whether the requirement can be satisfied using existing data (masked, cloned, synthetic, or a combination thereof) or requires new data to be generated.
- Executes said provisioning plan and delivers the data to the target environment.
For example, a test case may require a customer service representative to see an overdue payment warning when opening the profile of a customer who owes more than $100, has been overdue for more than 30 days, and is not yet in collections. K2view can interpret that requirement, identify the relevant entity as a customer, apply the required filters, find matching customers, and provision the associated data to your test environment. Note that the same test case could also contain negative and/or edge-case scenarios, which the Test Case Data Agent would also recognise and generate appropriate test data for, with no manual intervention – or even recognition – required on the part of the tester. Also note that the product optimises its test data approach for each test requirement. For instance, it will only go to the effort of creating synthetic data when masking or cloning existing data could not achieve the same results.
The end result is that test data management can be entirely automated from the end user perspective, effectively moving the technology away from the front end and into the back end (and the background). The platform exposes all of its functionality (including its AI capabilities) via APIs, making it available for integration with (and, where applicable, embedding into) various requirements tools, test management platforms, CI/CD pipelines, and so on.
K2view offers a robust and comprehensive solution for test data management, and its entity-driven, business-led approach is a significant differentiator that produces realistic, compliant test data. In addition, its ability to use AI to drive data classification and synthetic data generation, while not a new feature – either to the product or to the market – is certainly welcome, as is its natural language interface. It is also worth noting that K2view offers a wide range of test data management functionality – such as data discovery, masking, subsetting, and multiple kinds of synthetic data generation – within a single platform, providing an array of methods for you to pick from on a case-by-case basis without needing to incorporate additional tools.
That said, the agentic AI layer provided by Test Case Data Agent is its most standout feature. It stands to further automate test data management by removing a very significant manual step – that of interpreting and actioning the creation of the test data demanded by each individual test scenario – from the testing process, dramatically accelerating your testing efforts as a result. Moreover, with AI rapidly increasing the pace of software creation, this level of acceleration may prove necessary if you want to avoid your testing – and more specifically, your test data – from persistently delaying your overall development lifecycle.
K2view’s already strong test data management capabilities, supplemented by its entity-driven architecture, are made even more compelling by the addition of agentic AI. We expect that the ability to move directly and automatically from requirements to test data, with effectively no effort on the part of the user, will prove to be an especially powerful and appealing feature, particularly for organisations in which test data remains – or, with the increasing adoption of AI-driven development, has become – a bottleneck.
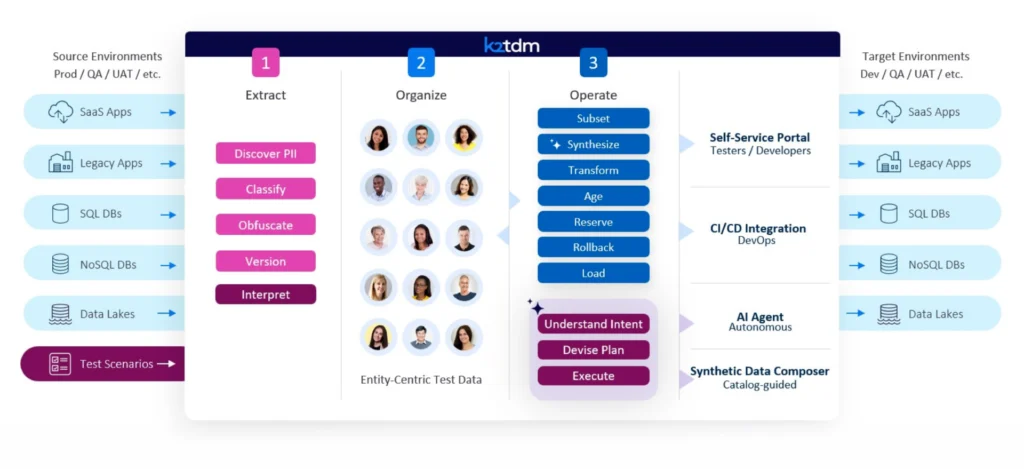
Figure 1 – K2view scenario-driven test data architecture, including the Test Case Data Agent
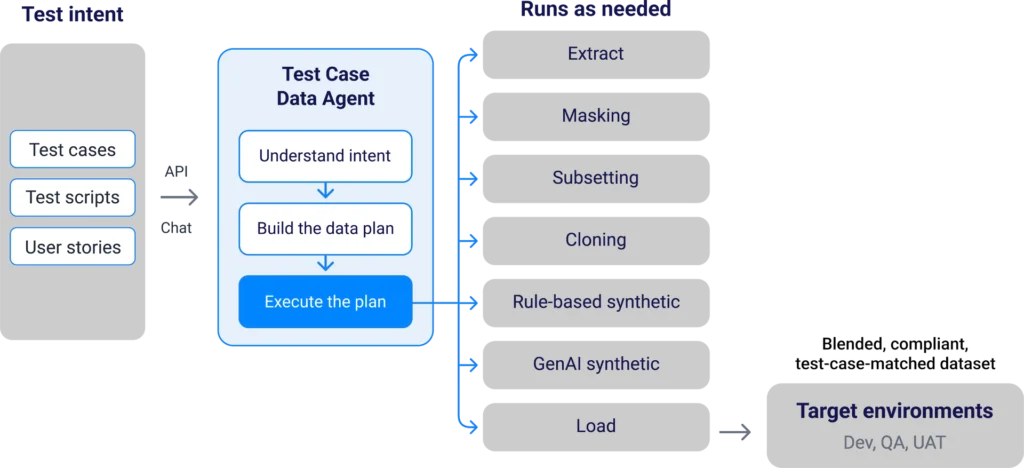
Figure 2 – How the K2view Test Case Data Agent works
Related Company
Connect with Us
Ready to Get Started
Learn how Bloor Research can support your organization’s journey toward a smarter, more secure future."
Connect with us Join Our Community