K2view Sensitive Data Discovery
Update solution on November 19, 2025
K2view (named for the famously difficult-to-climb mountain) was founded in 2009, and has offices in the US, Germany, Israel, and the Netherlands. It is the developer of the K2view Data Product Platform, which originated as an ETL tool but has since grown into a widely-encompassing data management offering capable of addressing a variety of enterprise use cases.
The K2view Data Product Platform is a unified data management platform that offers numerous capabilities within a single overarching product. It includes solutions for many different data tasks, including data integration, data governance, data fabric, cloud migration, 360-degree customer view, test data management, sensitive data discovery, and more.
The K2view Data Product Platform provides a single, foundational platform upon which multiple specialised K2view products are offered, addressing a wide range of enterprise data management challenges. Key products include Test Data Management, Synthetic Data Management, Data Pipelining, Customer 360, and Enterprise Data RAG. Most notably for this article, it includes significant sensitive data discovery functionality, an important element of its data masking solution.
One of the core capabilities of the K2view platform is its ability to organise your data into virtualised Micro-Databases, each one containing all of the information available on a particular business entity (such as a customer). This means that all data related to that entity is unified, and consistently refreshed, within a single (conceptual) location, making it far easier to process and manage that data.
Among other things, this helps drive discovery and masking. For example, it aids discoverability by providing you with identifying information that you can use to search for additional, relevant data. If an entity contains, say, an ID number, you can search for that number across your data sources (which could include structured, unstructured, and/or semi-structured data), and any results will likely correspond to the original entity. This structure also helps enable intelligent and consistent data masking, which we have discussed in detail in previous reports.
Moreover, business entities are automatically classified within the platform’s data catalogue, shown in Figure 1. This is intended as complementary to dedicated cataloguing products, rather than as a replacement, but nevertheless includes a sensitive data discovery process.
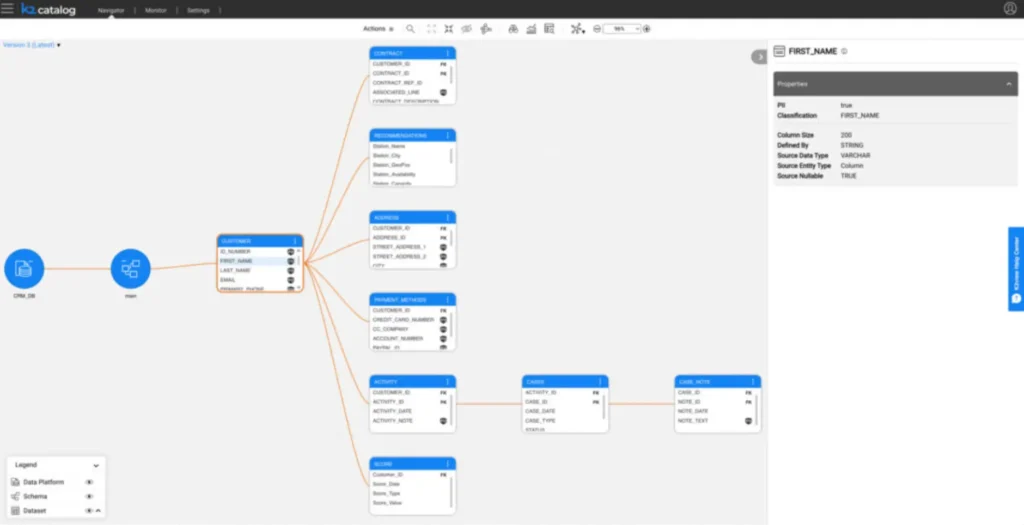
K2view’s data catalogue is designed to facilitate sensitive and PII data discovery while integrating with more fully-fledged data catalogues if they are present. It provides functionality for identifying and classifying your data, including sensitive data, on a continual basis. It accomplishes this by examining the data itself, its associated metadata, and its interactions with your data sources.
Data is classified using a series of classifiers, which match field names and values against patterns defined with regular expressions. Each classifier is equipped with a weighting that determines the certainty of the classification it represents, which is used to determine primacy when a field fits into multiple classifications as well as whether a classification is sufficiently certain to meet a preconfigured matching threshold. Classifications can be tagged as PII (which is to say, sensitive), and data that falls under that classification will be tagged as PII by association. In addition, PII tags can be associated to particular regulations, such as GDPR.
Furthermore, the catalogue provides options for leveraging LLMs, both for classifying data and for generating textual descriptions for your classifications. For example, you can use an LLM to identify foreign language names without depending on often unreliable column name metadata. This enables you to consistently find and classify even very uncommon names. Moreover, you can write the prompt for your LLM inside the product, allowing you to define how and where it should look for sensitive information.
Hundreds of prebuilt classifiers are built into the product, including classifiers for various governmental regulations. That said, these classifiers are designed to be customised and configured for your particular environment (which can be done within the catalogue). You can also build your own. Classifiers can be applied to both structured and unstructured data, including relational data, JSON, documents, text, images, and more. They can be executed where, when, and on which parts of your system as you so choose, either manually or on an automated schedule. Moreover, they can be applied dynamically to new data as it enters your system, with fine-grained control over which classifiers are used in this way.
The catalogue itself is highly visual and easy to use, and offers a variety of features above and beyond data classification (such as version comparisons) that are largely beyond the scope of this report. Notably, data masking processes can be assigned and configured for each data classification, which then act as a default masking algorithm for that type of data that can be applied automatically. In fact, K2view features a very robust solution for data masking. We have described this capability in some detail in its own report, so we will not repeat ourselves here, but suffice it to say that it effectively complements its solution for sensitive data discovery. Likewise, K2view features substantial synthetic data generation functionality – powered, in part, by its sensitive data discovery – that we have already discussed elsewhere.
The driving force behind K2view’s sensitive data discovery, and its key selling point in general, is its Micro-Database-driven business entity architecture. This architecture drives a “context-first” approach that the company’s discovery solution – and its offerings in general – revolve around. Indeed, the contextual foundation that business entities provide grants significant benefits for both discoverability in general and the discovery of sensitive data in particular. For example, building this foundation immediately centralises data that has been fragmented across multiple data sources but refers to the same base entity. It also makes it much easier to identify contextually sensitive data, since you already know its original context. What’s more, when it comes time to anonymise your sensitive data, it allows you to mask each entity individually and uniquely, ensuring your masking is consistent and that referential integrity is maintained throughout your data environment, even across multiple connected systems.
K2view also features a highly visual and user-friendly data catalogue that is focused primarily on finding and classifying your data, both sensitive and otherwise. Its numerous prebuilt classifiers are much appreciated, and so is the degree of configuration and customisation that is available for them. Its array of execution options, particularly its dynamic execution on newly-arrived data, are also worth highlighting, as is its LLM integration. In addition, it offers highly competitive data masking capabilities, which can be used to intelligently and automatically protect your sensitive data once it has been discovered. Indeed, there is enough to say about K2view’s data masking solution that we have written a report dedicated to it, which we recommend you treat as an essential companion piece to this one.
Related Company
Connect with Us
Ready to Get Started
Learn how Bloor Research can support your organization’s journey toward a smarter, more secure future."
Connect with us Join Our Community