BigID Next Sensitive Data Discovery
Update solution on November 13, 2025
BigID was founded in 2016, is based in New York and Tel Aviv, and has offices in London. It has raised over $300m in venture capital to date, with notable investors including Salesforce Ventures, Bessemer Ventures, Scale Ventures, ClearSky Ventures and SAP.io. The latter is also a partner, and BigID can be directly licensed from SAP as well as from other value-added resellers. Other notable partnerships include (but are not limited to) TrustArc, OneTrust, RSA Archer, Collibra, and Immuta.
BigID Next is a data compliance, privacy and security platform that specialises in (sensitive) data discovery and classification. To this end, it offers automated, AI-driven discovery of both sensitive data and AI models across hundreds of different data sources, covering the entire enterprise. This includes, but is not limited to, popular relational data sources and AI models, big data sources (such as Amazon S3, Azure BLOB storage and a variety of NoSQL databases), unstructured data sources (such as file servers, SharePoint, and Microsoft Office), applications, messaging, streams (such as Apache Kafka and Amazon Kinesis) and middleware. If this isn’t enough, a “custom” connector is available for connecting with data sources that aren’t supported out of the box.
Under the hood, BigID Next is a microservices-based solution that leverages Docker containers and Kubernetes, and is deployable in on-prem, cloud, and hybrid environments, either self-managed or as a SaaS. The platform is highly modular, and you can deploy it in its entirety or start with a small deployment and grow it over time, as you prefer. While its discovery capabilities are foundational, you can build on them via various data management, privacy, and/or security applications (such as DSAR (Data Subject Access Request) automation, data lifecycle management, policy-based privacy automation/regulatory compliance, data loss prevention, risk management, and so on) provided by BigID, available either individually or bundled by use case (as shown in Figure 1). Various applications from partner companies are also available.
In addition to BigID Next, the company also offers BigID Express as a faster point of entry to the platform. This sister product is relatively limited in its capabilities, but is easy to deploy, simple to use (in part due to the aforementioned limitations), and can be built upon if and when desired. Pricing is metred based on volume of data, regardless of the product employed, so the selling point here is its expedience.
BigID Next scans your enterprise for sensitive data, capturing various kinds of relevant metadata – sensitivity, criticality, and so on – then identifying and classifying the corresponding data accordingly. Scanning is configurable – you can deploy as much or as little as you need, with a variety of different scanning types available – and you can deploy multiple scanners in parallel, against either one data source or many. Scans typically only examine samples from each data source, for efficiency purposes, but their findings are returned with a confidence level, allowing you to rescan in more detail if there is significant uncertainty. In addition, the platform will also scan your system for any AI models – whether internal or external – that it is interfaced with, as well the data those models are consuming.
The actual discovery process leverages AI and LLMs on top of more traditional discovery techniques. Over 1000 (in fact, closer to 1300) classifiers are available out of the box, and include multilingual support and metadata classification. You can also build your own. Different algorithms are used depending on the source, and can examine both data and metadata: for instance, for structured data the platform might use correlation-based machine learning and metadata enrichment, while for unstructured data it could employ a neural network based on named entity recognition. Regardless, discovery is typically “context-aware”, meaning that it uses AI to help determine meaning (and sensitivity) based on the surrounding context. For instance, this can be used to recognise this difference between “Dakota”, the name of a person (and therefore sensitive), and “Dakota”, one of the many places of the same name (and not, as a rule, sensitive). The end result of all of this is that BigID is able to claim an over 97% accurate identification rate for sensitive data.
Scanned metadata is stored in the platform’s metadata catalogue. While the results of discovery can be accessed through the catalogue directly, they are more typically exposed through either the catalogue’s “Google-like” Data Explorer search interface or the product’s more general dashboarding and reporting capabilities (see Figure 2). Scanned AI models are also inventoried, presenting a unified view of AI models and data usage within your system (seen in Figure 3). Moreover, catalogued data and AI assets can be mapped to various, customisable categories, such as organisational unit, and classification into these categories can be automated by examining data attributes, posture, and so on.
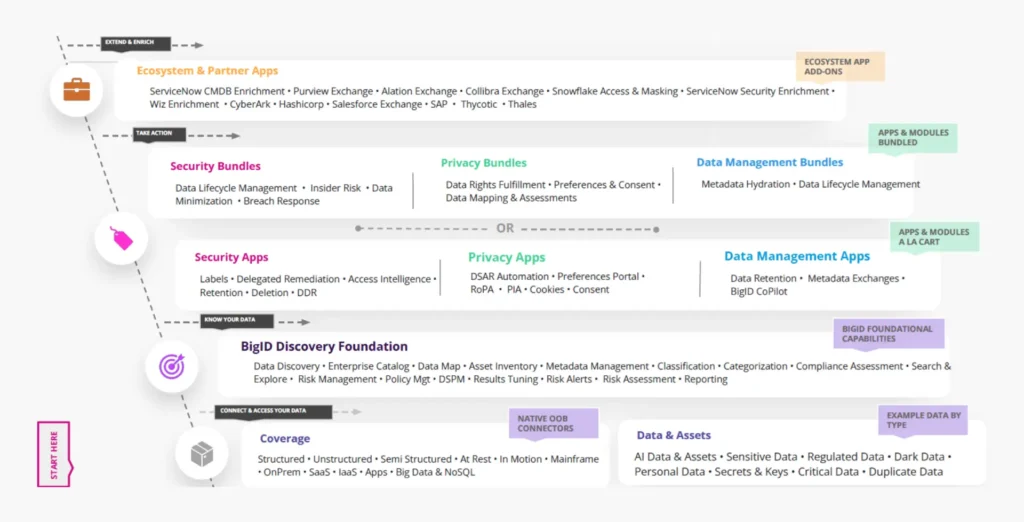
Figure 1 – BigID Next platform architecture
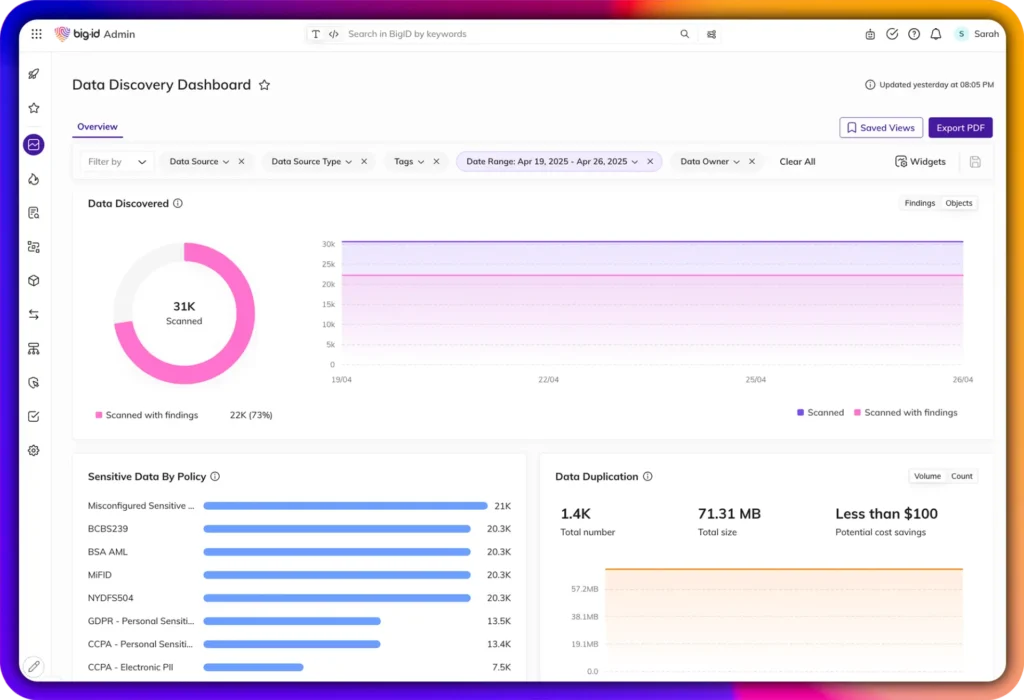
Figure 2 – BigID Next discovery dashboard
An integrated, LLM-driven AI copilot is available to help you manage this catalogue. It can automatically tag similar data assets (which, if actually identical, can then be deduplicated), infer ownership of orphaned data by assessing likely owners, recommend business-friendly display names and descriptions for data columns, and more. Additional tools are available for capturing data lineage, setting relevant data policies, investigating data breaches, and managing DSAR requests. In particular, there are facilities provided to identify both potential policy breaches and high-risk data sources (and who is using them).
BigID Next will integrate with various third-party environments, such as Tableau and Qlik. In particular, its discovery findings can be used to hydrate other data catalogues by pushing classifications to them, as well as bidirectionally exchanging metadata with them. Supported third-party catalogues for this purpose include Collibra, Alation, Informatica, Microsoft Purview, Snowflake, and Databricks. For additional solutions, a REST API is available.
Unlike some other vendors in this space, that have incrementally added data discovery capabilities onto tools that were historically focused in other directions, BigID Next has been built from the ground up to concentrate on data discovery. This is evidenced in both the quality and quantity of its classification methods: 97% accuracy is very impressive to begin with, and providing significantly upwards of 1000 classifiers out of the box is, if anything, even more so. Not to mention its vast array of compatible data sources and third-party product integrations, which also serve to showcase the product’s maturity and focus.
What’s more, from the outset BigID Next has been developed to exploit machine learning and artificial intelligence. This is a huge boon in the current era of generative AI, and very few of the company’s competitors can boast this sort of pedigree. For example, the platform’s approach to sensitive data discovery is built around using AI to bolster more mundane discovery methods. On that front, it has always been ahead of the curve, but with (generative) AI’s current popularity, in general and as part of data classification, BigID has an enormous head start over many vendors. Similarly, the platform’s ability to scan and catalogue AI models is both very relevant for AI governance (an increasingly hot topic) and something we haven’t seen on any other discovery vendors.
There are other capabilities we could mention as well – we particularly like the Data Explorer search interface, for instance, as well as the platform’s ability to generate and assign business-friendly terms to often much less friendly column names – but while these are certainly nice to have, they are ultimately secondary to the points we have just described.
BigID Next is a data compliance, privacy and security platform that features an exceptionally mature and effective solution for sensitive data discovery. It offers impressive breadth (of both classifications and compatible data sources) and accuracy alongside long-standing, and similarly impressive, AI capabilities. Unless you have no space whatever for AI in your organisation, BigID Next should almost certainly be on your shortlist.
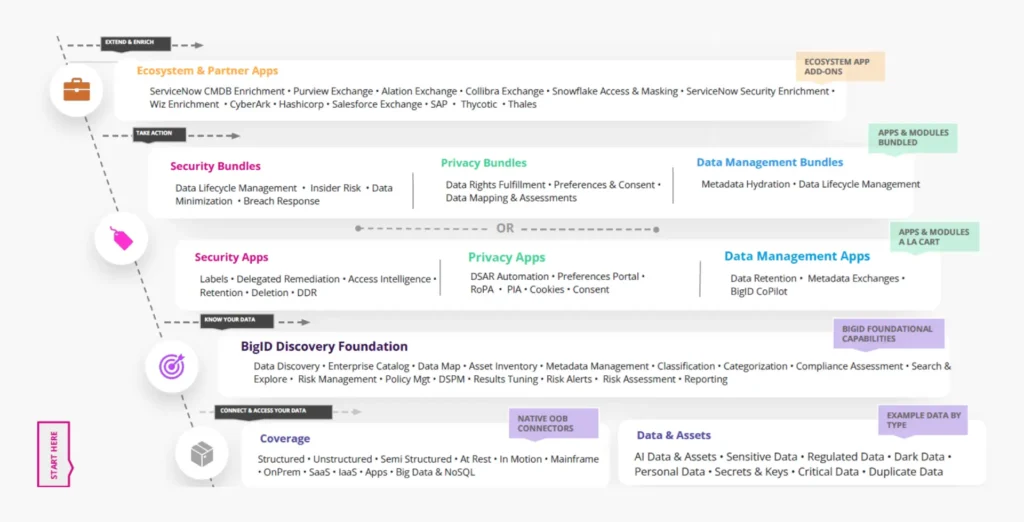
Figure 1 – BigID Next platform architecture
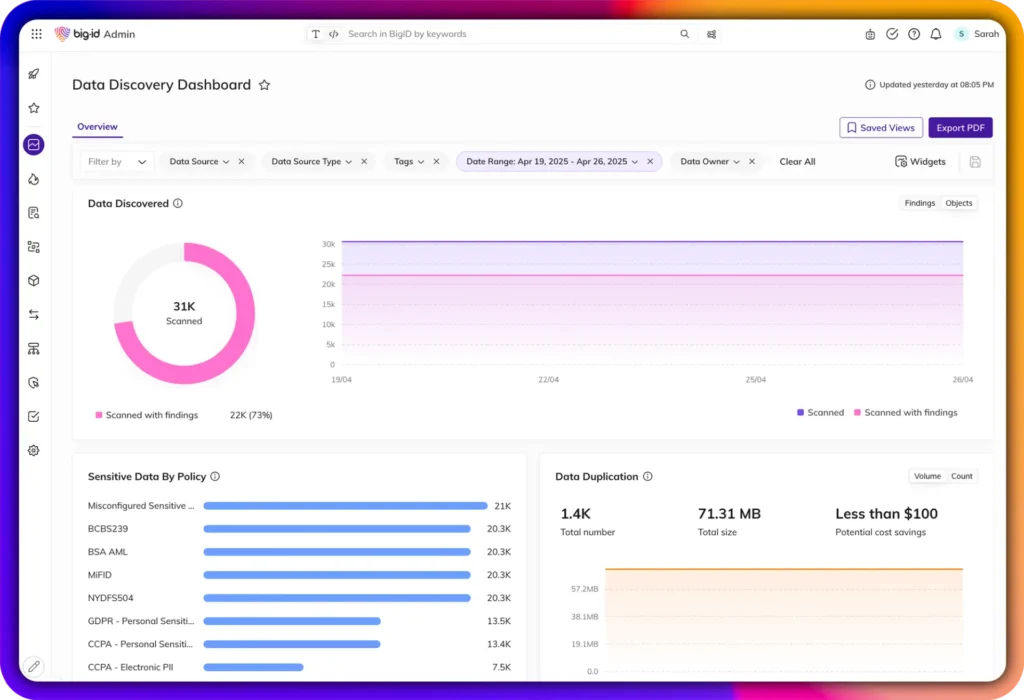
Figure 2 – BigID Next discovery dashboard

Figure 3 – BigID Next AI model view
“BigID Next has been built from the ground up to concentrate on data discovery.”
“BigID Next is a data compliance, privacy and security platform that features an exceptionally mature and effective solution for sensitive data discovery.”
Related Company
Connect with Us
Ready to Get Started
Learn how Bloor Research can support your organization’s journey toward a smarter, more secure future."
Connect with us Join Our Community