DataStax Enterprise
Update solution on June 28, 2019

DSE is a distributed NoSQL database, using CQL (Cassandra Query Language), that is oriented towards (though not exclusive to) cloud and hybrid-cloud architectures. It is built on top of Cassandra, as illustrated in Figure 1. It boasts numerous capabilities above and beyond what Cassandra alone offers, including native search and analytics, auto-management functionality, and significant increases to speed and performance.
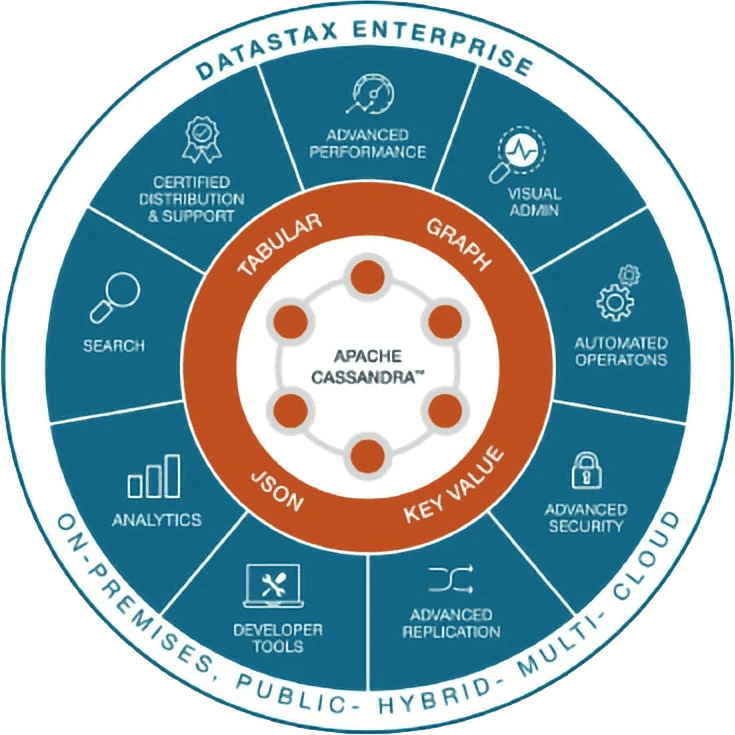
Fig 01 Showing how DataStax is built on top of Cassandra
As can be seen in this diagram, DSE provides multi-model capabilities and, unlike some other multi-model products you can leverage all of the models, not just within a single database instance but also within a single query. For example, the optimiser can automatically invoke Spark or search (Solr) from a Gremlin (graph) query. This has the advantage that if you are a Gremlin or CQL developer you don’t need to know or understand Spark (or Solr). One possible limitation is with respect to document model implementations where DataStax requires that a schema is defined.
Note that from the perspective of supporting hybrid processing environments DataStax takes the view that this should not only encompass analytic and transactional processing but also search.
Customer Quotes
“Search and analytics were some of the key capabilities we were looking for and with DataStax Enterprise, we got a unified platform that provides all these and more all in the same cluster. This was a significant reason why we chose DataStax Enterprise to power
our app.”
You Are My Guide
“The key benefit of using DSE is the co-location of data and technology with Cassandra and Solr for search and Cassandra with Spark for analytics. This results in the real-time nodes having access to data instantly and not requiring time-consuming or costly ETL processes to move data between systems, because all the data is transparently replicated in the cluster.”
Macquarie
Architecturally, the most notable feature of DSE is that it uses a master-less architecture in which all nodes are the same, with the result that there is no single point of failure. This particularly suits environments where you want to deploy across multiple clouds or in hybrid on-premises and cloud deployments. It also suits the way that DataStax supports workload management, which is illustrated in Figure 2.
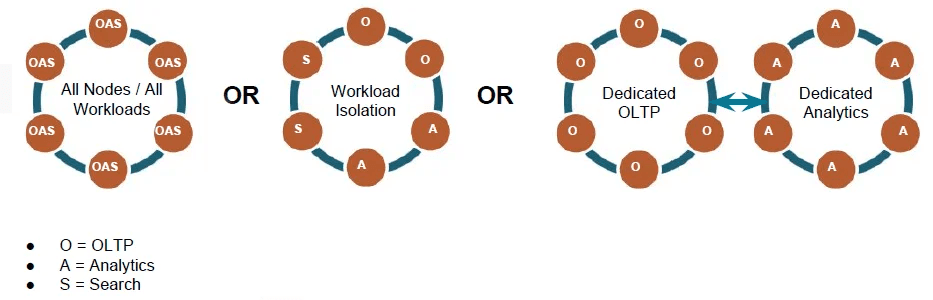
Fig 02 How DataStax supports workload management
As can be seen, you can support any workload within a node, you can specify that a particular node has a specific task or you can have clusters – (elastically) scalable individually – dedicated to a particular task, or you can mix and match these.
From a transactional standpoint the database supports the atomicity, isolation and durability of ACID guarantees but tuneable consistency. The latter is enabled by choosing to use either asynchronous or synchronous replication. The former provides eventual consistency and the latter immediate consistency but with the trade-off of reduced performance.
As far as analytics and search are concerned the company offers specific enterprise components known as DSE Analytics and DSE Search, which work in conjunction with both DSE itself and DSE Graph. As mentioned, DSE Analytics is integrated with Spark and the company claims that DSE Analytics is significantly faster than open source Spark. The product also supports Python and it has customers using both R and TensorFlow though these are not formally supported as yet. PMML (predictive modelling mark-up language) is not supported. It is worth also noting that DSE Graph in and of itself boasts some significant differentiators. This includes its dual processing engines, allowing you to easily switch between transactional and analytical processing, and DataStax Studio, a particularly impressive example of a visual development environment for graph.
Finally, it is worth commenting on DSE’s Kafka integration, which enables data to be streamed into the DSE environment. This is currently only a one-way process, but the company plans to support export to Kafka in a future release.
Cassandra initially made its name as a NoSQL database because it was designed from the outset to support key enterprise requirements such as constant availability, resilience, and disaster recovery, as well as scalability. Many other NoSQL databases did not start from this position and only added mission-critical capabilities – if they did – later. We prefer the approach taken by the developers of Cassandra. Moreover, in DSE there are substantial additional elements that go beyond Cassandra itself, some of which are at the feature level and some of which, such as the multi-model support, and the search and analytics capabilities, are more substantial.
The Bottom Line
DSE is almost unique in supporting both graph and conventional analytics alongside transactional processing and search. No other company we have spoken to sees hybrid processing as a three-way (transactions, analytics and search) environment, and we think DataStax’s approach makes a lot of sense.
Related Company
Connect with Us
Ready to Get Started
Learn how Bloor Research can support your organization’s journey toward a smarter, more secure future."
Connect with us Join Our Community